 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Privacy in Hierarchical Federated Learning: A Formal Analysis and Evaluation
Jan 21, 2024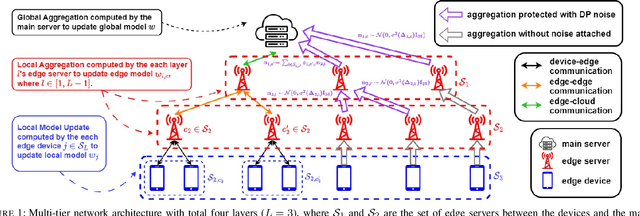
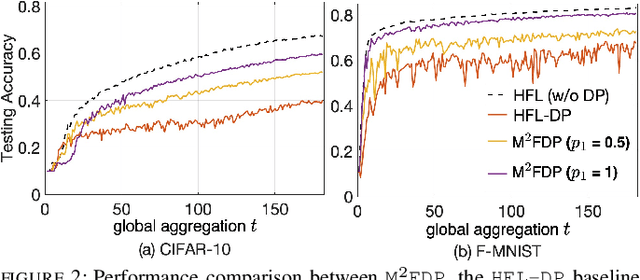
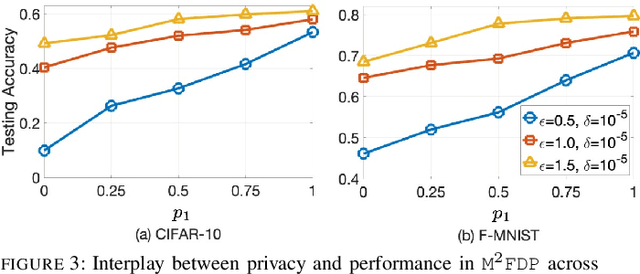
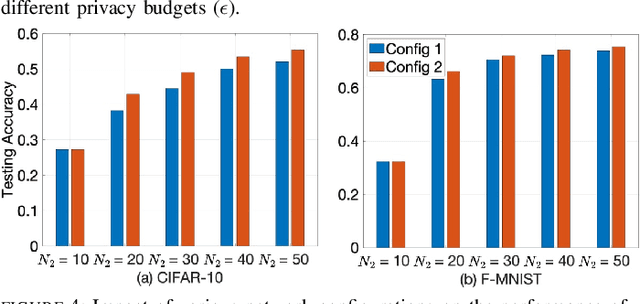
While federated learning (FL) eliminates the transmission of raw data over a network, it is still vulnerable to privacy breaches from the communicated model parameters. In this work, we formalize Differentially Private Hierarchical Federated Learning (DP-HFL), a DP-enhanced FL methodology that seeks to improve the privacy-utility tradeoff inherent in FL. Building upon recent proposals for Hierarchical Differential Privacy (HDP), one of the key concepts of DP-HFL is adapting DP noise injection at different layers of an established FL hierarchy -- edge devices, edge servers, and cloud servers -- according to the trust models within particular subnetworks. We conduct a comprehensive analysis of the convergence behavior of DP-HFL, revealing conditions on parameter tuning under which the model training process converges sublinearly to a stationarity gap, with this gap depending on the network hierarchy, trust model, and target privacy level. Subsequent numerical evaluations demonstrate that DP-HFL obtains substantial improvements in convergence speed over baselines for different privacy budgets, and validate the impact of network configuration on training.
Delay-Aware Hierarchical Federated Learning
Mar 23, 2023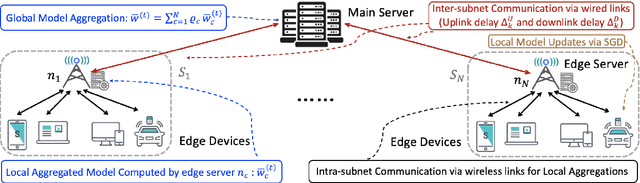
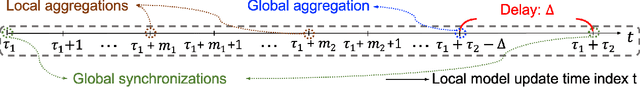
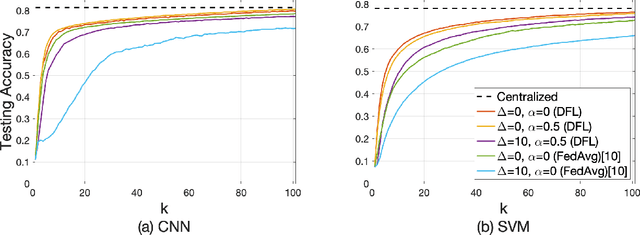
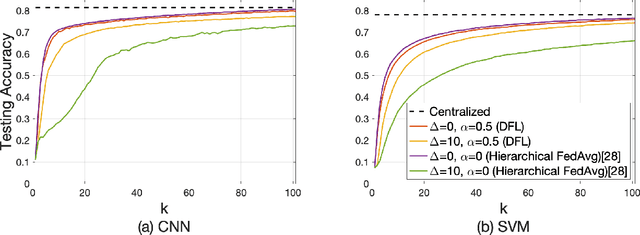
Federated learning has gained popularity as a means of training models distributed across the wireless edge. The paper introduces delay-aware federated learning (DFL) to improve the efficiency of distributed machine learning (ML) model training by addressing communication delays between edge and cloud. DFL employs multiple stochastic gradient descent iterations on device datasets during each global aggregation interval and intermittently aggregates model parameters through edge servers in local subnetworks. The cloud server synchronizes the local models with the global deployed model computed via a local-global combiner at global synchronization. The convergence behavior of DFL is theoretically investigated under a generalized data heterogeneity metric. A set of conditions is obtained to achieve the sub-linear convergence rate of O(1/k). Based on these findings, an adaptive control algorithm is developed for DFL, implementing policies to mitigate energy consumption and edge-to-cloud communication latency while aiming for a sublinear convergence rate. Numerical evaluations show DFL's superior performance in terms of faster global model convergence, reduced resource consumption, and robustness against communication delays compared to existing FL algorithms. In summary, this proposed method offers improved efficiency and satisfactory results when dealing with both convex and non-convex loss functions.
Resource-Efficient and Delay-Aware Federated Learning Design under Edge Heterogeneity
Jan 03, 2022
Federated learning (FL) has emerged as a popular methodology for distributing machine learning across wireless edge devices. In this work, we consider optimizing the tradeoff between model performance and resource utilization in FL, under device-server communication delays and device computation heterogeneity. Our proposed StoFedDelAv algorithm incorporates a local-global model combiner into the FL synchronization step. We theoretically characterize the convergence behavior of StoFedDelAv and obtain the optimal combiner weights, which consider the global model delay and expected local gradient error at each device. We then formulate a network-aware optimization problem which tunes the minibatch sizes of the devices to jointly minimize energy consumption and machine learning training loss, and solve the non-convex problem through a series of convex approximations. Our simulations reveal that StoFedDelAv outperforms the current art in FL in terms of model convergence speed and network resource utilization when the minibatch size and the combiner weights are adjusted. Additionally, our method can reduce the number of uplink communication rounds required during the model training period to reach the same accuracy.
Federated Learning Beyond the Star: Local D2D Model Consensus with Global Cluster Sampling
Sep 12, 2021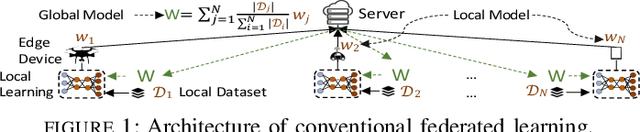
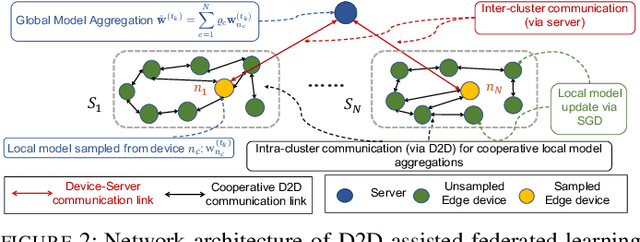
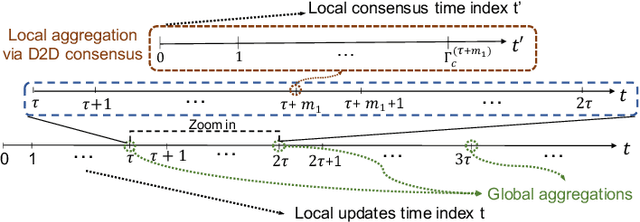
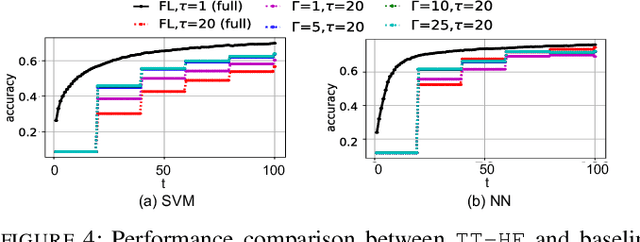
Federated learning has emerged as a popular technique for distributing model training across the network edge. Its learning architecture is conventionally a star topology between the devices and a central server. In this paper, we propose two timescale hybrid federated learning (TT-HF), which migrates to a more distributed topology via device-to-device (D2D) communications. In TT-HF, local model training occurs at devices via successive gradient iterations, and the synchronization process occurs at two timescales: (i) macro-scale, where global aggregations are carried out via device-server interactions, and (ii) micro-scale, where local aggregations are carried out via D2D cooperative consensus formation in different device clusters. Our theoretical analysis reveals how device, cluster, and network-level parameters affect the convergence of TT-HF, and leads to a set of conditions under which a convergence rate of O(1/t) is guaranteed. Experimental results demonstrate the improvements in convergence and utilization that can be obtained by TT-HF over state-of-the-art federated learning baselines.
Two Timescale Hybrid Federated Learning with Cooperative D2D Local Model Aggregations
Mar 18, 2021


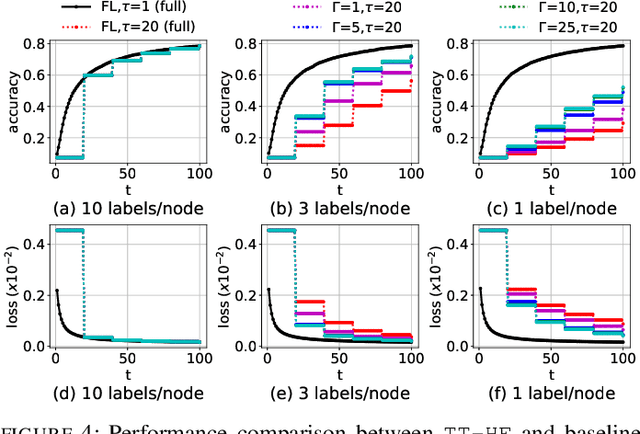
Federated learning has emerged as a popular technique for distributing machine learning (ML) model training across the wireless edge. In this paper, we propose two timescale hybrid federated learning (TT-HF), which is a hybrid between the device-to-server communication paradigm in federated learning and device-to-device (D2D) communications for model training. In TT-HF, during each global aggregation interval, devices (i) perform multiple stochastic gradient descent iterations on their individual datasets, and (ii) aperiodically engage in consensus formation of their model parameters through cooperative, distributed D2D communications within local clusters. With a new general definition of gradient diversity, we formally study the convergence behavior of TT-HF, resulting in new convergence bounds for distributed ML. We leverage our convergence bounds to develop an adaptive control algorithm that tunes the step size, D2D communication rounds, and global aggregation period of TT-HF over time to target a sublinear convergence rate of O(1/t) while minimizing network resource utilization. Our subsequent experiments demonstrate that TT-HF significantly outperforms the current art in federated learning in terms of model accuracy and/or network energy consumption in different scenarios where local device datasets exhibit statistical heterogeneity.
Federated Learning with Communication Delay in Edge Networks
Aug 21, 2020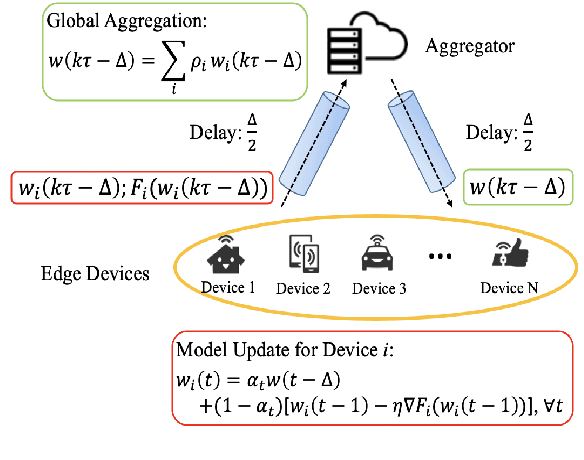
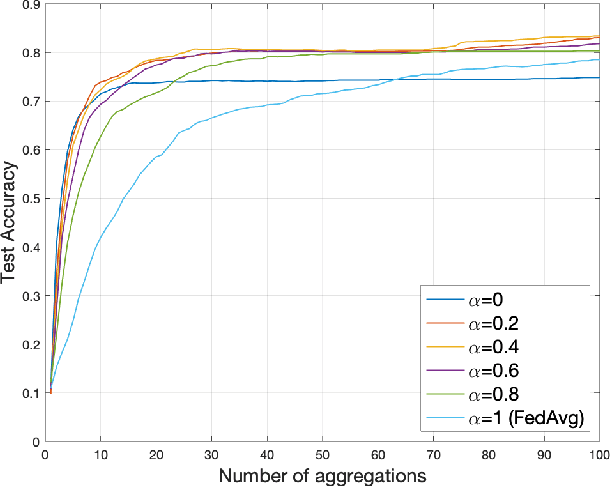
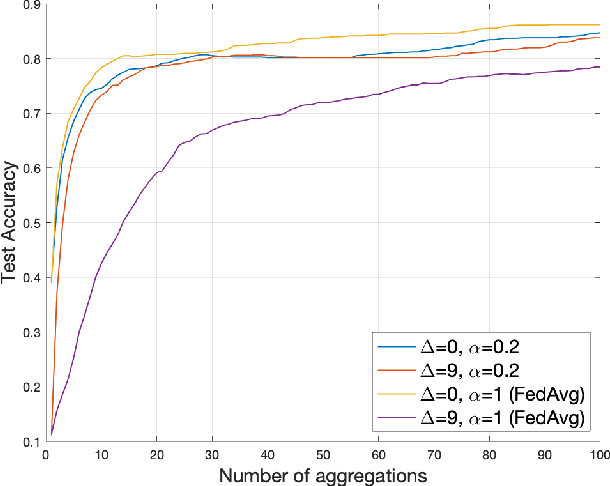
Federated learning has received significant attention as a potential solution for distributing machine learning (ML) model training through edge networks. This work addresses an important consideration of federated learning at the network edge: communication delays between the edge nodes and the aggregator. A technique called FedDelAvg (federated delayed averaging) is developed, which generalizes the standard federated averaging algorithm to incorporate a weighting between the current local model and the delayed global model received at each device during the synchronization step. Through theoretical analysis, an upper bound is derived on the global model loss achieved by FedDelAvg, which reveals a strong dependency of learning performance on the values of the weighting and learning rate. Experimental results on a popular ML task indicate significant improvements in terms of convergence speed when optimizing the weighting scheme to account for delays.