 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelay-Aware Hierarchical Federated Learning
Paper and Code
Mar 23, 2023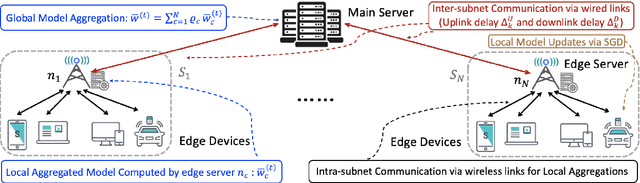
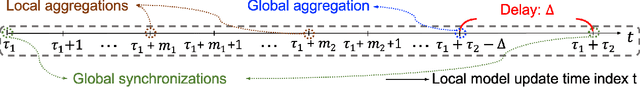
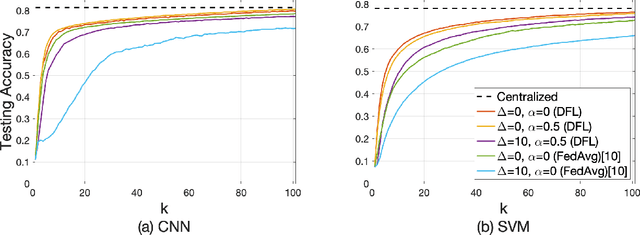
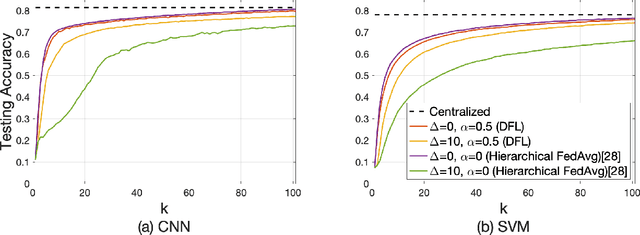
Federated learning has gained popularity as a means of training models distributed across the wireless edge. The paper introduces delay-aware federated learning (DFL) to improve the efficiency of distributed machine learning (ML) model training by addressing communication delays between edge and cloud. DFL employs multiple stochastic gradient descent iterations on device datasets during each global aggregation interval and intermittently aggregates model parameters through edge servers in local subnetworks. The cloud server synchronizes the local models with the global deployed model computed via a local-global combiner at global synchronization. The convergence behavior of DFL is theoretically investigated under a generalized data heterogeneity metric. A set of conditions is obtained to achieve the sub-linear convergence rate of O(1/k). Based on these findings, an adaptive control algorithm is developed for DFL, implementing policies to mitigate energy consumption and edge-to-cloud communication latency while aiming for a sublinear convergence rate. Numerical evaluations show DFL's superior performance in terms of faster global model convergence, reduced resource consumption, and robustness against communication delays compared to existing FL algorithms. In summary, this proposed method offers improved efficiency and satisfactory results when dealing with both convex and non-convex loss functions.