 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Minimal Pairs with Ordinal Surprisal Curves and Entropy Across Applied Domains
Mar 15, 2026The minimal pairs paradigm of comparing model probabilities for contrasting completions has proven useful for evaluating linguistic knowledge in language models, yet its application has largely been confined to binary grammaticality judgments over syntactic phenomena. Additionally, standard prompting-based evaluation requires expensive text generation, may elicit post-hoc rationalizations rather than model judgments, and discards information about model uncertainty. We address both limitations by extending surprisal-based evaluation from binary grammaticality contrasts to ordinal-scaled classification and scoring tasks across multiple domains. Rather than asking models to generate answers, we measure the information-theoretic "surprise" (negative log probability) they assign to each position on rating scales (e.g., 1-5 or 1-9), yielding full surprisal curves that reveal both the model's preferred response and its uncertainty via entropy. We explore this framework across four domains: social-ecological-technological systems classification, causal statement identification (binary and scaled), figurative language detection, and deductive qualitative coding. Across these domains, surprisal curves produce interpretable classification signals with clear minima near expected ordinal scale positions, and entropy over the completion tended to distinguish genuinely ambiguous items from easier items.
Using Generative Text Models to Create Qualitative Codebooks for Student Evaluations of Teaching
Mar 18, 2024Feedback is a critical aspect of improvement. Unfortunately, when there is a lot of feedback from multiple sources, it can be difficult to distill the information into actionable insights. Consider student evaluations of teaching (SETs), which are important sources of feedback for educators. They can give instructors insights into what worked during a semester. A collection of SETs can also be useful to administrators as signals for courses or entire programs. However, on a large scale as in high-enrollment courses or administrative records over several years, the volume of SETs can render them difficult to analyze. In this paper, we discuss a novel method for analyzing SETs using natural language processing (NLP) and large language models (LLMs). We demonstrate the method by applying it to a corpus of 5,000 SETs from a large public university. We show that the method can be used to extract, embed, cluster, and summarize the SETs to identify the themes they express. More generally, this work illustrates how to use the combination of NLP techniques and LLMs to generate a codebook for SETs. We conclude by discussing the implications of this method for analyzing SETs and other types of student writing in teaching and research settings.
Exploring the Efficacy of ChatGPT in Analyzing Student Teamwork Feedback with an Existing Taxonomy
May 09, 2023



Teamwork is a critical component of many academic and professional settings. In those contexts, feedback between team members is an important element to facilitate successful and sustainable teamwork. However, in the classroom, as the number of teams and team members and frequency of evaluation increase, the volume of comments can become overwhelming for an instructor to read and track, making it difficult to identify patterns and areas for student improvement. To address this challenge, we explored the use of generative AI models, specifically ChatGPT, to analyze student comments in team based learning contexts. Our study aimed to evaluate ChatGPT's ability to accurately identify topics in student comments based on an existing framework consisting of positive and negative comments. Our results suggest that ChatGPT can achieve over 90\% accuracy in labeling student comments, providing a potentially valuable tool for analyzing feedback in team projects. This study contributes to the growing body of research on the use of AI models in educational contexts and highlights the potential of ChatGPT for facilitating analysis of student comments.
Reinforcement Learning-based N-ary Cross-Sentence Relation Extraction
Sep 26, 2020
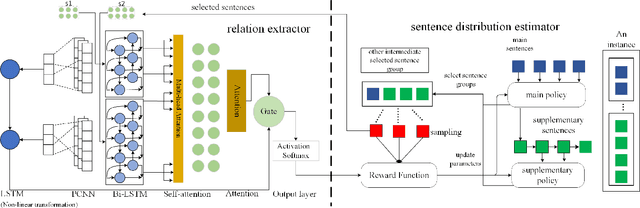

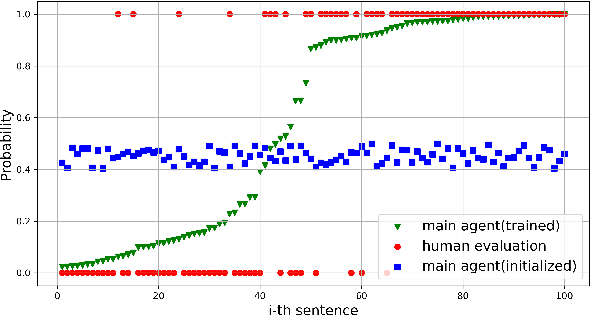
The models of n-ary cross sentence relation extraction based on distant supervision assume that consecutive sentences mentioning n entities describe the relation of these n entities. However, on one hand, this assumption introduces noisy labeled data and harms the models' performance. On the other hand, some non-consecutive sentences also describe one relation and these sentences cannot be labeled under this assumption. In this paper, we relax this strong assumption by a weaker distant supervision assumption to address the second issue and propose a novel sentence distribution estimator model to address the first problem. This estimator selects correctly labeled sentences to alleviate the effect of noisy data is a two-level agent reinforcement learning model. In addition, a novel universal relation extractor with a hybrid approach of attention mechanism and PCNN is proposed such that it can be deployed in any tasks, including consecutive and nonconsecutive sentences. Experiments demonstrate that the proposed model can reduce the impact of noisy data and achieve better performance on general n-ary cross sentence relation extraction task compared to baseline models.
Clustering-based Unsupervised Generative Relation Extraction
Sep 26, 2020
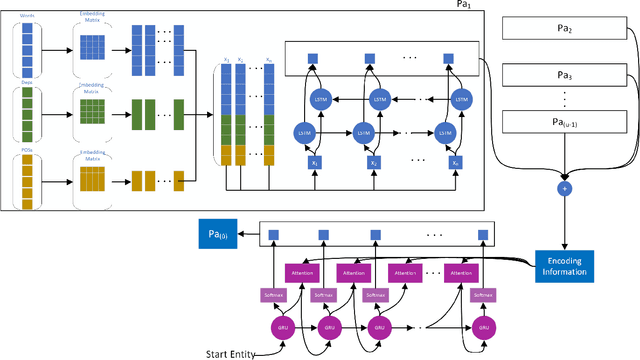
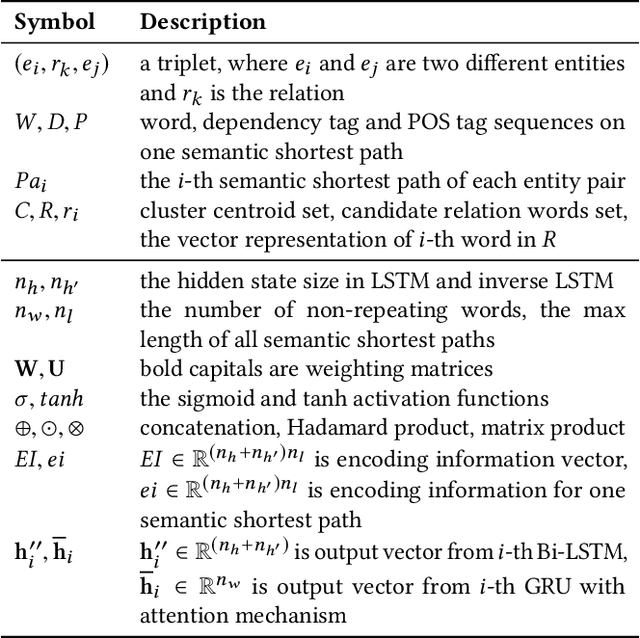
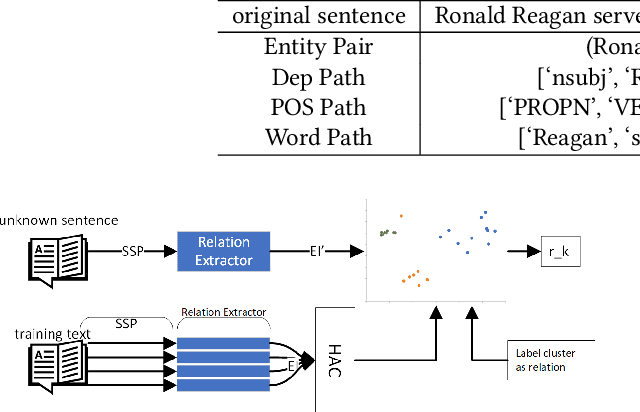
This paper focuses on the problem of unsupervised relation extraction. Existing probabilistic generative model-based relation extraction methods work by extracting sentence features and using these features as inputs to train a generative model. This model is then used to cluster similar relations. However, these methods do not consider correlations between sentences with the same entity pair during training, which can negatively impact model performance. To address this issue, we propose a Clustering-based Unsupervised generative Relation Extraction (CURE) framework that leverages an "Encoder-Decoder" architecture to perform self-supervised learning so the encoder can extract relation information. Given multiple sentences with the same entity pair as inputs, self-supervised learning is deployed by predicting the shortest path between entity pairs on the dependency graph of one of the sentences. After that, we extract the relation information using the well-trained encoder. Then, entity pairs that share the same relation are clustered based on their corresponding relation information. Each cluster is labeled with a few words based on the words in the shortest paths corresponding to the entity pairs in each cluster. These cluster labels also describe the meaning of these relation clusters. We compare the triplets extracted by our proposed framework (CURE) and baseline methods with a ground-truth Knowledge Base. Experimental results show that our model performs better than state-of-the-art models on both New York Times (NYT) and United Nations Parallel Corpus (UNPC) standard datasets.