 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering-based Unsupervised Generative Relation Extraction
Paper and Code
Sep 26, 2020
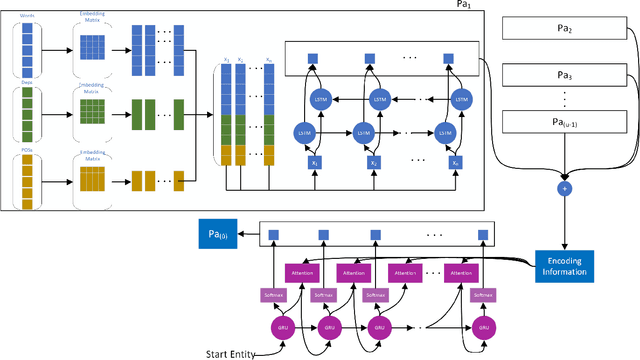
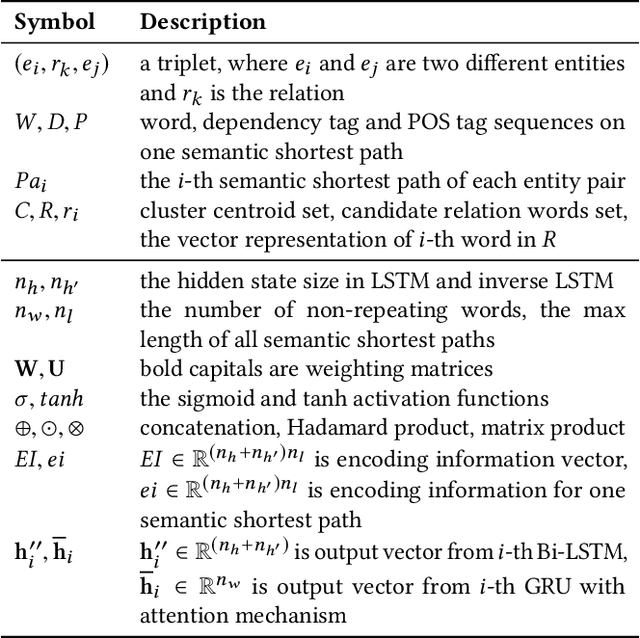
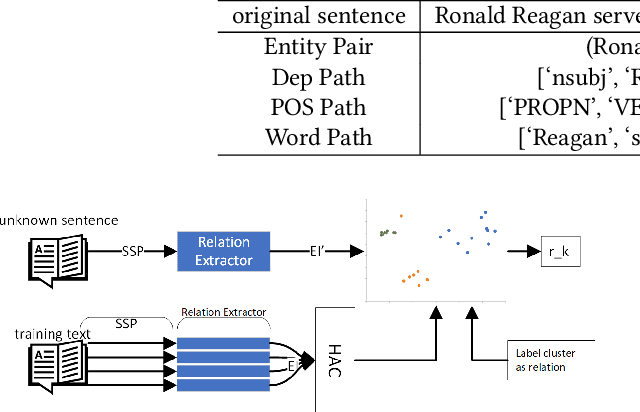
This paper focuses on the problem of unsupervised relation extraction. Existing probabilistic generative model-based relation extraction methods work by extracting sentence features and using these features as inputs to train a generative model. This model is then used to cluster similar relations. However, these methods do not consider correlations between sentences with the same entity pair during training, which can negatively impact model performance. To address this issue, we propose a Clustering-based Unsupervised generative Relation Extraction (CURE) framework that leverages an "Encoder-Decoder" architecture to perform self-supervised learning so the encoder can extract relation information. Given multiple sentences with the same entity pair as inputs, self-supervised learning is deployed by predicting the shortest path between entity pairs on the dependency graph of one of the sentences. After that, we extract the relation information using the well-trained encoder. Then, entity pairs that share the same relation are clustered based on their corresponding relation information. Each cluster is labeled with a few words based on the words in the shortest paths corresponding to the entity pairs in each cluster. These cluster labels also describe the meaning of these relation clusters. We compare the triplets extracted by our proposed framework (CURE) and baseline methods with a ground-truth Knowledge Base. Experimental results show that our model performs better than state-of-the-art models on both New York Times (NYT) and United Nations Parallel Corpus (UNPC) standard datasets.