 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Hybrid Federated Learning over Large-Scale Wireless Fog Networks
Paper and Code
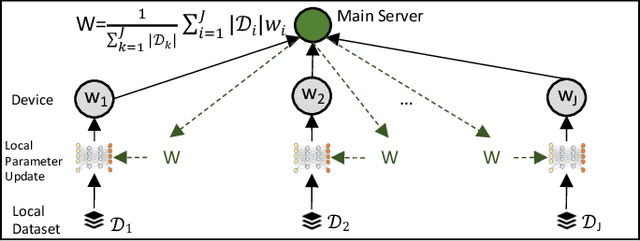
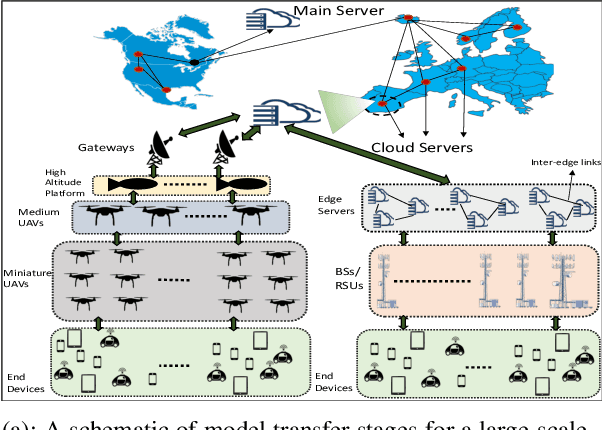
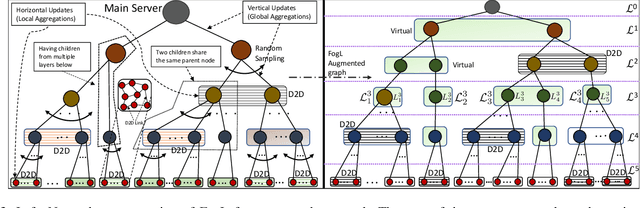
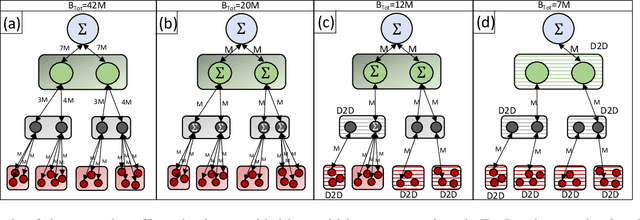
One of the popular methods for distributed machine learning (ML) is federated learning, in which devices train local models based on their datasets, which are in turn aggregated periodically by a server. In large-scale fog networks, the "star" learning topology of federated learning poses several challenges in terms of resource utilization. We develop multi-stage hybrid model training (MH-MT), a novel learning methodology for distributed ML in these scenarios. Leveraging the hierarchical structure of fog systems, MH-MT combines multi-stage parameter relaying with distributed consensus formation among devices in a hybrid learning paradigm across network layers. We theoretically derive the convergence bound of MH-MT with respect to the network topology, ML model, and algorithm parameters such as the rounds of consensus employed in different clusters of devices. We obtain a set of policies for the number of consensus rounds at different clusters to guarantee either a finite optimality gap or convergence to the global optimum. Subsequently, we develop an adaptive distributed control algorithm for MH-MT to tune the number of consensus rounds at each cluster of local devices over time to meet convergence criteria. Our numerical experiments validate the performance of MH-MT in terms of convergence speed and resource utilization.