 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecycling Model Updates in Federated Learning: Are Gradient Subspaces Low-Rank?
Paper and Code
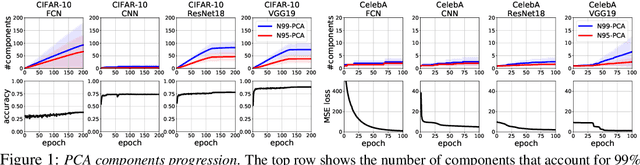
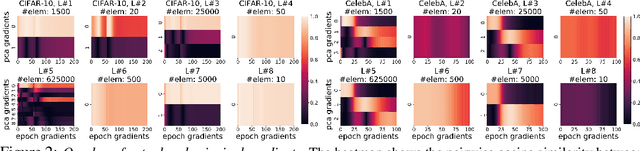
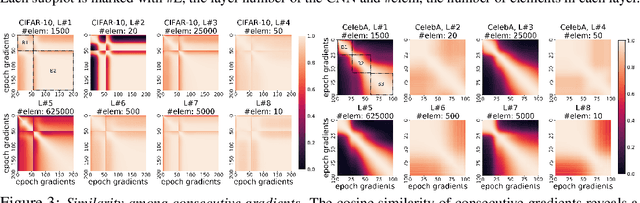
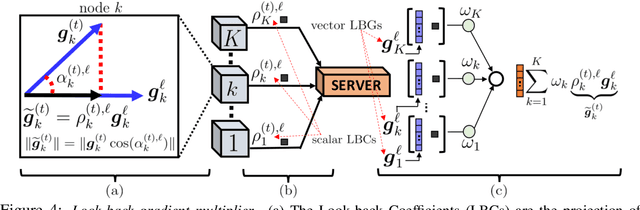
In this paper, we question the rationale behind propagating large numbers of parameters through a distributed system during federated learning. We start by examining the rank characteristics of the subspace spanned by gradients across epochs (i.e., the gradient-space) in centralized model training, and observe that this gradient-space often consists of a few leading principal components accounting for an overwhelming majority (95-99%) of the explained variance. Motivated by this, we propose the "Look-back Gradient Multiplier" (LBGM) algorithm, which exploits this low-rank property to enable gradient recycling between model update rounds of federated learning, reducing transmissions of large parameters to single scalars for aggregation. We analytically characterize the convergence behavior of LBGM, revealing the nature of the trade-off between communication savings and model performance. Our subsequent experimental results demonstrate the improvement LBGM obtains in communication overhead compared to conventional federated learning on several datasets and deep learning models. Additionally, we show that LBGM is a general plug-and-play algorithm that can be used standalone or stacked on top of existing sparsification techniques for distributed model training.