 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum Approximation in Asynchronous Private Federated Learning
Paper and Code
Feb 14, 2024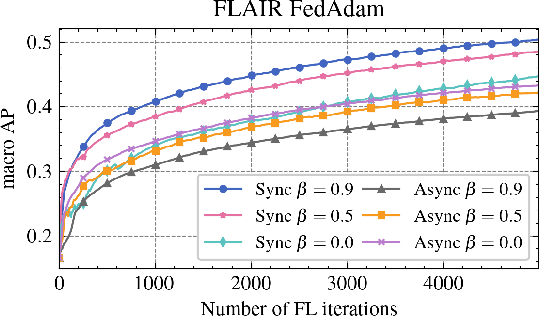
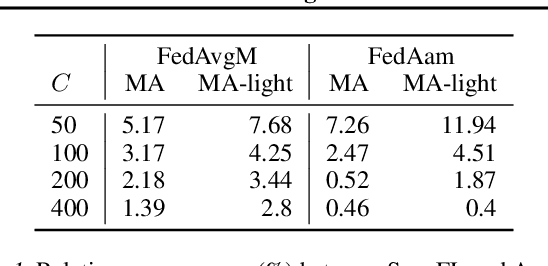
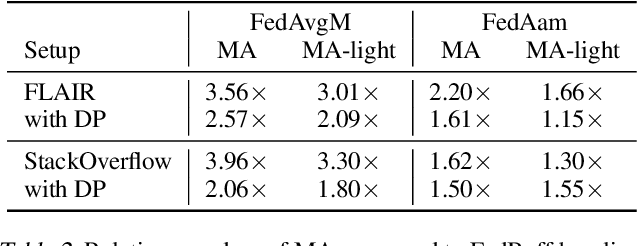
Asynchronous protocols have been shown to improve the scalability of federated learning (FL) with a massive number of clients. Meanwhile, momentum-based methods can achieve the best model quality in synchronous FL. However, naively applying momentum in asynchronous FL algorithms leads to slower convergence and degraded model performance. It is still unclear how to effective combinie these two techniques together to achieve a win-win. In this paper, we find that asynchrony introduces implicit bias to momentum updates. In order to address this problem, we propose momentum approximation that minimizes the bias by finding an optimal weighted average of all historical model updates. Momentum approximation is compatible with secure aggregation as well as differential privacy, and can be easily integrated in production FL systems with a minor communication and storage cost. We empirically demonstrate that on benchmark FL datasets, momentum approximation can achieve $1.15 \textrm{--}4\times$ speed up in convergence compared to existing asynchronous FL optimizers with momentum.