 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Labeling Oracles: What does it mean to steal ML models?
Paper and Code
Oct 03, 2023

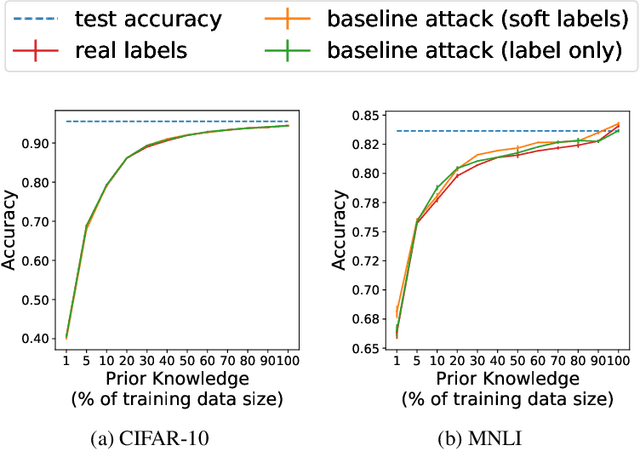
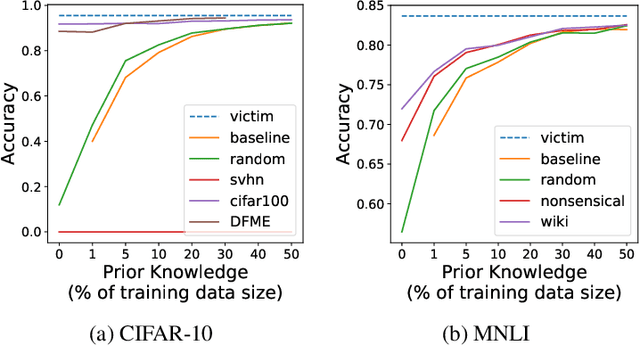
Model extraction attacks are designed to steal trained models with only query access, as is often provided through APIs that ML-as-a-Service providers offer. ML models are expensive to train, in part because data is hard to obtain, and a primary incentive for model extraction is to acquire a model while incurring less cost than training from scratch. Literature on model extraction commonly claims or presumes that the attacker is able to save on both data acquisition and labeling costs. We show that the attacker often does not. This is because current attacks implicitly rely on the adversary being able to sample from the victim model's data distribution. We thoroughly evaluate factors influencing the success of model extraction. We discover that prior knowledge of the attacker, i.e. access to in-distribution data, dominates other factors like the attack policy the adversary follows to choose which queries to make to the victim model API. Thus, an adversary looking to develop an equally capable model with a fixed budget has little practical incentive to perform model extraction, since for the attack to work they need to collect in-distribution data, saving only on the cost of labeling. With low labeling costs in the current market, the usefulness of such attacks is questionable. Ultimately, we demonstrate that the effect of prior knowledge needs to be explicitly decoupled from the attack policy. To this end, we propose a benchmark to evaluate attack policy directly.