 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAST: Language Model Aware Speech Tokenization
Paper and Code
Sep 05, 2024
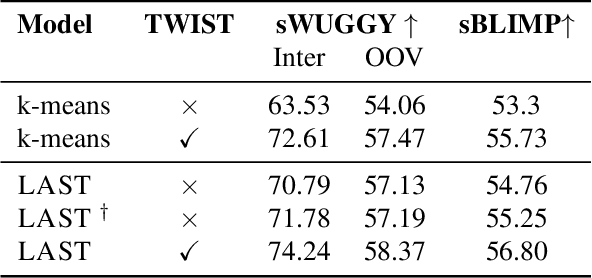


Speech tokenization serves as the foundation of speech language model (LM), enabling them to perform various tasks such as spoken language modeling, text-to-speech, speech-to-text, etc. Most speech tokenizers are trained independently of the LM training process, relying on separate acoustic models and quantization methods. Following such an approach may create a mismatch between the tokenization process and its usage afterward. In this study, we propose a novel approach to training a speech tokenizer by leveraging objectives from pre-trained textual LMs. We advocate for the integration of this objective into the process of learning discrete speech representations. Our aim is to transform features from a pre-trained speech model into a new feature space that enables better clustering for speech LMs. We empirically investigate the impact of various model design choices, including speech vocabulary size and text LM size. Our results demonstrate the proposed tokenization method outperforms the evaluated baselines considering both spoken language modeling and speech-to-text. More importantly, unlike prior work, the proposed method allows the utilization of a single pre-trained LM for processing both speech and text inputs, setting it apart from conventional tokenization approaches.