 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation For Formant Estimation Using Deep Learning
Nov 06, 2016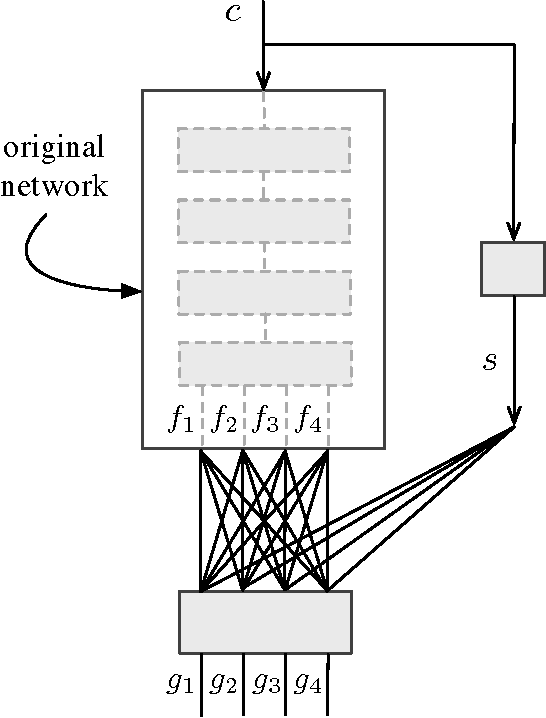


In this paper we present a domain adaptation technique for formant estimation using a deep network. We first train a deep learning network on a small read speech dataset. We then freeze the parameters of the trained network and use several different datasets to train an adaptation layer that makes the obtained network universal in the sense that it works well for a variety of speakers and speech domains with very different characteristics. We evaluated our adapted network on three datasets, each of which has different speaker characteristics and speech styles. The performance of our method compares favorably with alternative methods for formant estimation.
Automatic measurement of vowel duration via structured prediction
Oct 26, 2016
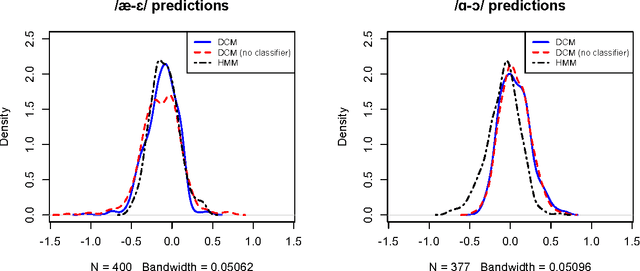

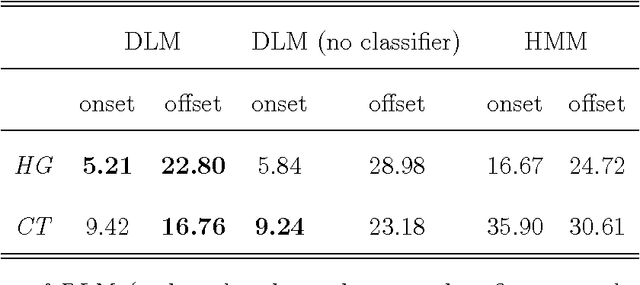
A key barrier to making phonetic studies scalable and replicable is the need to rely on subjective, manual annotation. To help meet this challenge, a machine learning algorithm was developed for automatic measurement of a widely used phonetic measure: vowel duration. Manually-annotated data were used to train a model that takes as input an arbitrary length segment of the acoustic signal containing a single vowel that is preceded and followed by consonants and outputs the duration of the vowel. The model is based on the structured prediction framework. The input signal and a hypothesized set of a vowel's onset and offset are mapped to an abstract vector space by a set of acoustic feature functions. The learning algorithm is trained in this space to minimize the difference in expectations between predicted and manually-measured vowel durations. The trained model can then automatically estimate vowel durations without phonetic or orthographic transcription. Results comparing the model to three sets of manually annotated data suggest it out-performed the current gold standard for duration measurement, an HMM-based forced aligner (which requires orthographic or phonetic transcription as an input).