 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExPairT-LLM: Exact Learning for LLM Code Selection by Pairwise Queries
Nov 13, 2025Despite recent advances in LLMs, the task of code generation is still challenging. To cope, code selection algorithms select the best program from multiple programs generated by an LLM. However, existing algorithms can fail to identify the correct program, either because they can misidentify nonequivalent programs or because they rely on an LLM and assume it always correctly determines the output for every input. We present ExPairT-LLM, an exact learning algorithm for code selection that selects a program by posing to an LLM oracle two new types of queries: pairwise membership and pairwise equivalence. These queries are simpler for LLMs and enable ExPairT-LLM to identify the correct program through a tournament, which is robust to some LLM mistakes. We evaluate ExPairT-LLM on four popular code datasets. Its pass@1 (success rate) outperforms the state-of-the-art code selection algorithm on average by +13.0% and up to +27.1%. It also improves the pass@1 of LLMs performing complex reasoning by +24.0%.
Tight Robustness Certification through the Convex Hull of $\ell_0$ Attacks
Nov 13, 2025Few-pixel attacks mislead a classifier by modifying a few pixels of an image. Their perturbation space is an $\ell_0$-ball, which is not convex, unlike $\ell_p$-balls for $p\geq1$. However, existing local robustness verifiers typically scale by relying on linear bound propagation, which captures convex perturbation spaces. We show that the convex hull of an $\ell_0$-ball is the intersection of its bounding box and an asymmetrically scaled $\ell_1$-like polytope. The volumes of the convex hull and this polytope are nearly equal as the input dimension increases. We then show a linear bound propagation that precisely computes bounds over the convex hull and is significantly tighter than bound propagations over the bounding box or our $\ell_1$-like polytope. This bound propagation scales the state-of-the-art $\ell_0$ verifier on its most challenging robustness benchmarks by 1.24x-7.07x, with a geometric mean of 3.16.
Guarding the Privacy of Label-Only Access to Neural Network Classifiers via iDP Verification
Feb 26, 2025



Neural networks are susceptible to privacy attacks that can extract private information of the training set. To cope, several training algorithms guarantee differential privacy (DP) by adding noise to their computation. However, DP requires to add noise considering every possible training set. This leads to a significant decrease in the network's accuracy. Individual DP (iDP) restricts DP to a given training set. We observe that some inputs deterministically satisfy iDP without any noise. By identifying them, we can provide iDP label-only access to the network with a minor decrease to its accuracy. However, identifying the inputs that satisfy iDP without any noise is highly challenging. Our key idea is to compute the iDP deterministic bound (iDP-DB), which overapproximates the set of inputs that do not satisfy iDP, and add noise only to their predicted labels. To compute the tightest iDP-DB, which enables to guard the label-only access with minimal accuracy decrease, we propose LUCID, which leverages several formal verification techniques. First, it encodes the problem as a mixed-integer linear program, defined over a network and over every network trained identically but without a unique data point. Second, it abstracts a set of networks using a hyper-network. Third, it eliminates the overapproximation error via a novel branch-and-bound technique. Fourth, it bounds the differences of matching neurons in the network and the hyper-network and employs linear relaxation if they are small. We show that LUCID can provide classifiers with a perfect individuals' privacy guarantee (0-iDP) -- which is infeasible for DP training algorithms -- with an accuracy decrease of 1.4%. For more relaxed $\varepsilon$-iDP guarantees, LUCID has an accuracy decrease of 1.2%. In contrast, existing DP training algorithms reduce the accuracy by 12.7%.
Boosting Few-Pixel Robustness Verification via Covering Verification Designs
May 17, 2024
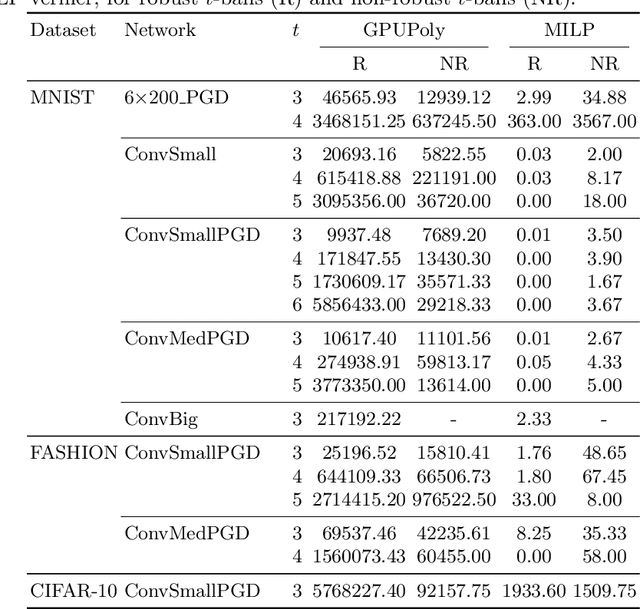
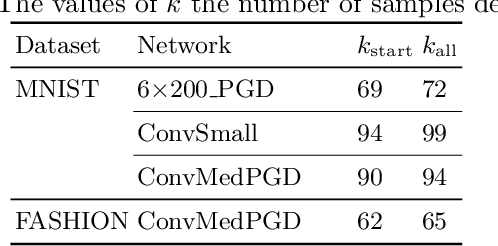
Proving local robustness is crucial to increase the reliability of neural networks. While many verifiers prove robustness in $L_\infty$ $\epsilon$-balls, very little work deals with robustness verification in $L_0$ $\epsilon$-balls, capturing robustness to few pixel attacks. This verification introduces a combinatorial challenge, because the space of pixels to perturb is discrete and of exponential size. A previous work relies on covering designs to identify sets for defining $L_\infty$ neighborhoods, which if proven robust imply that the $L_0$ $\epsilon$-ball is robust. However, the number of neighborhoods to verify remains very high, leading to a high analysis time. We propose covering verification designs, a combinatorial design that tailors effective but analysis-incompatible coverings to $L_0$ robustness verification. The challenge is that computing a covering verification design introduces a high time and memory overhead, which is intensified in our setting, where multiple candidate coverings are required to identify how to reduce the overall analysis time. We introduce CoVerD, an $L_0$ robustness verifier that selects between different candidate coverings without constructing them, but by predicting their block size distribution. This prediction relies on a theorem providing closed-form expressions for the mean and variance of this distribution. CoVerD constructs the chosen covering verification design on-the-fly, while keeping the memory consumption minimal and enabling to parallelize the analysis. The experimental results show that CoVerD reduces the verification time on average by up to 5.1x compared to prior work and that it scales to larger $L_0$ $\epsilon$-balls.
Verification of Neural Networks' Global Robustness
Mar 06, 2024



Neural networks are successful in various applications but are also susceptible to adversarial attacks. To show the safety of network classifiers, many verifiers have been introduced to reason about the local robustness of a given input to a given perturbation. While successful, local robustness cannot generalize to unseen inputs. Several works analyze global robustness properties, however, neither can provide a precise guarantee about the cases where a network classifier does not change its classification. In this work, we propose a new global robustness property for classifiers aiming at finding the minimal globally robust bound, which naturally extends the popular local robustness property for classifiers. We introduce VHAGaR, an anytime verifier for computing this bound. VHAGaR relies on three main ideas: encoding the problem as a mixed-integer programming and pruning the search space by identifying dependencies stemming from the perturbation or the network's computation and generalizing adversarial attacks to unknown inputs. We evaluate VHAGaR on several datasets and classifiers and show that, given a three hour timeout, the average gap between the lower and upper bound on the minimal globally robust bound computed by VHAGaR is 1.9, while the gap of an existing global robustness verifier is 154.7. Moreover, VHAGaR is 130.6x faster than this verifier. Our results further indicate that leveraging dependencies and adversarial attacks makes VHAGaR 78.6x faster.
Verification of Neural Networks Local Differential Classification Privacy
Oct 31, 2023
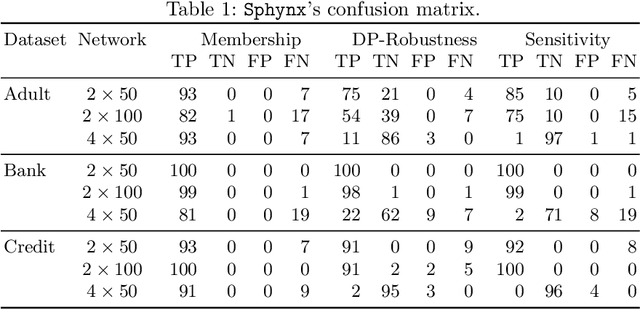

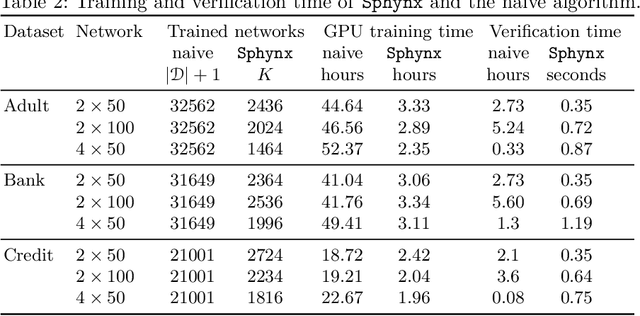
Neural networks are susceptible to privacy attacks. To date, no verifier can reason about the privacy of individuals participating in the training set. We propose a new privacy property, called local differential classification privacy (LDCP), extending local robustness to a differential privacy setting suitable for black-box classifiers. Given a neighborhood of inputs, a classifier is LDCP if it classifies all inputs the same regardless of whether it is trained with the full dataset or whether any single entry is omitted. A naive algorithm is highly impractical because it involves training a very large number of networks and verifying local robustness of the given neighborhood separately for every network. We propose Sphynx, an algorithm that computes an abstraction of all networks, with a high probability, from a small set of networks, and verifies LDCP directly on the abstract network. The challenge is twofold: network parameters do not adhere to a known distribution probability, making it difficult to predict an abstraction, and predicting too large abstraction harms the verification. Our key idea is to transform the parameters into a distribution given by KDE, allowing to keep the over-approximation error small. To verify LDCP, we extend a MILP verifier to analyze an abstract network. Experimental results show that by training only 7% of the networks, Sphynx predicts an abstract network obtaining 93% verification accuracy and reducing the analysis time by $1.7\cdot10^4$x.
Boosting Robustness Verification of Semantic Feature Neighborhoods
Sep 12, 2022



Deep neural networks have been shown to be vulnerable to adversarial attacks that perturb inputs based on semantic features. Existing robustness analyzers can reason about semantic feature neighborhoods to increase the networks' reliability. However, despite the significant progress in these techniques, they still struggle to scale to deep networks and large neighborhoods. In this work, we introduce VeeP, an active learning approach that splits the verification process into a series of smaller verification steps, each is submitted to an existing robustness analyzer. The key idea is to build on prior steps to predict the next optimal step. The optimal step is predicted by estimating the certification velocity and sensitivity via parametric regression. We evaluate VeeP on MNIST, Fashion-MNIST, CIFAR-10 and ImageNet and show that it can analyze neighborhoods of various features: brightness, contrast, hue, saturation, and lightness. We show that, on average, given a 90 minute timeout, VeeP verifies 96% of the maximally certifiable neighborhoods within 29 minutes, while existing splitting approaches verify, on average, 73% of the maximally certifiable neighborhoods within 58 minutes.
Learning Disjunctions of Predicates
Jun 15, 2017



Let $F$ be a set of boolean functions. We present an algorithm for learning $F_\vee := \{\vee_{f\in S} f \mid S \subseteq F\}$ from membership queries. Our algorithm asks at most $|F| \cdot OPT(F_\vee)$ membership queries where $OPT(F_\vee)$ is the minimum worst case number of membership queries for learning $F_\vee$. When $F$ is a set of halfspaces over a constant dimension space or a set of variable inequalities, our algorithm runs in polynomial time. The problem we address has practical importance in the field of program synthesis, where the goal is to synthesize a program that meets some requirements. Program synthesis has become popular especially in settings aiming to help end users. In such settings, the requirements are not provided upfront and the synthesizer can only learn them by posing membership queries to the end user. Our work enables such synthesizers to learn the exact requirements while bounding the number of membership queries.