 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA System and Benchmark for LLM-based Q&A on Heterogeneous Data
Sep 10, 2024In many industrial settings, users wish to ask questions whose answers may be found in structured data sources such as a spreadsheets, databases, APIs, or combinations thereof. Often, the user doesn't know how to identify or access the right data source. This problem is compounded even further if multiple (and potentially siloed) data sources must be assembled to derive the answer. Recently, various Text-to-SQL applications that leverage Large Language Models (LLMs) have addressed some of these problems by enabling users to ask questions in natural language. However, these applications remain impractical in realistic industrial settings because they fail to cope with the data source heterogeneity that typifies such environments. In this paper, we address heterogeneity by introducing the siwarex platform, which enables seamless natural language access to both databases and APIs. To demonstrate the effectiveness of siwarex, we extend the popular Spider dataset and benchmark by replacing some of its tables by data retrieval APIs. We find that siwarex does a good job of coping with data source heterogeneity. Our modified Spider benchmark will soon be available to the research community
Representation Stability as a Regularizer for Improved Text Analytics Transfer Learning
Apr 12, 2017


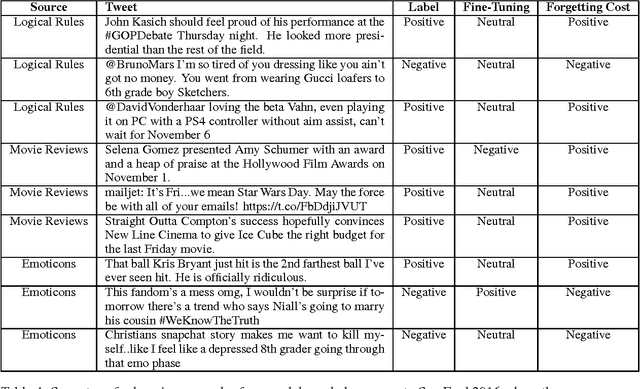
Although neural networks are well suited for sequential transfer learning tasks, the catastrophic forgetting problem hinders proper integration of prior knowledge. In this work, we propose a solution to this problem by using a multi-task objective based on the idea of distillation and a mechanism that directly penalizes forgetting at the shared representation layer during the knowledge integration phase of training. We demonstrate our approach on a Twitter domain sentiment analysis task with sequential knowledge transfer from four related tasks. We show that our technique outperforms networks fine-tuned to the target task. Additionally, we show both through empirical evidence and examples that it does not forget useful knowledge from the source task that is forgotten during standard fine-tuning. Surprisingly, we find that first distilling a human made rule based sentiment engine into a recurrent neural network and then integrating the knowledge with the target task data leads to a substantial gain in generalization performance. Our experiments demonstrate the power of multi-source transfer techniques in practical text analytics problems when paired with distillation. In particular, for the SemEval 2016 Task 4 Subtask A (Nakov et al., 2016) dataset we surpass the state of the art established during the competition with a comparatively simple model architecture that is not even competitive when trained on only the labeled task specific data.