 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamingBench: Assessing the Gap for MLLMs to Achieve Streaming Video Understanding
Nov 06, 2024

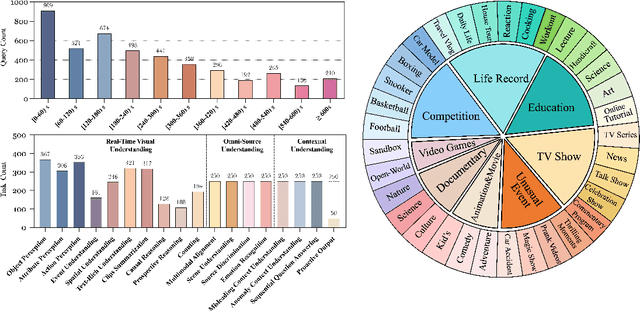

The rapid development of Multimodal Large Language Models (MLLMs) has expanded their capabilities from image comprehension to video understanding. However, most of these MLLMs focus primarily on offline video comprehension, necessitating extensive processing of all video frames before any queries can be made. This presents a significant gap compared to the human ability to watch, listen, think, and respond to streaming inputs in real time, highlighting the limitations of current MLLMs. In this paper, we introduce StreamingBench, the first comprehensive benchmark designed to evaluate the streaming video understanding capabilities of MLLMs. StreamingBench assesses three core aspects of streaming video understanding: (1) real-time visual understanding, (2) omni-source understanding, and (3) contextual understanding. The benchmark consists of 18 tasks, featuring 900 videos and 4,500 human-curated QA pairs. Each video features five questions presented at different time points to simulate a continuous streaming scenario. We conduct experiments on StreamingBench with 13 open-source and proprietary MLLMs and find that even the most advanced proprietary MLLMs like Gemini 1.5 Pro and GPT-4o perform significantly below human-level streaming video understanding capabilities. We hope our work can facilitate further advancements for MLLMs, empowering them to approach human-level video comprehension and interaction in more realistic scenarios.
Results of the Big ANN: NeurIPS'23 competition
Sep 25, 2024


The 2023 Big ANN Challenge, held at NeurIPS 2023, focused on advancing the state-of-the-art in indexing data structures and search algorithms for practical variants of Approximate Nearest Neighbor (ANN) search that reflect the growing complexity and diversity of workloads. Unlike prior challenges that emphasized scaling up classical ANN search ~\cite{DBLP:conf/nips/SimhadriWADBBCH21}, this competition addressed filtered search, out-of-distribution data, sparse and streaming variants of ANNS. Participants developed and submitted innovative solutions that were evaluated on new standard datasets with constrained computational resources. The results showcased significant improvements in search accuracy and efficiency over industry-standard baselines, with notable contributions from both academic and industrial teams. This paper summarizes the competition tracks, datasets, evaluation metrics, and the innovative approaches of the top-performing submissions, providing insights into the current advancements and future directions in the field of approximate nearest neighbor search.
CODIS: Benchmarking Context-Dependent Visual Comprehension for Multimodal Large Language Models
Feb 21, 2024



Multimodal large language models (MLLMs) have demonstrated promising results in a variety of tasks that combine vision and language. As these models become more integral to research and applications, conducting comprehensive evaluations of their capabilities has grown increasingly important. However, most existing benchmarks fail to consider that, in certain situations, images need to be interpreted within a broader context. In this work, we introduce a new benchmark, named as CODIS, designed to assess the ability of models to use context provided in free-form text to enhance visual comprehension. Our findings indicate that MLLMs consistently fall short of human performance on this benchmark. Further analysis confirms that these models struggle to effectively extract and utilize contextual information to improve their understanding of images. This underscores the pressing need to enhance the ability of MLLMs to comprehend visuals in a context-dependent manner. View our project website at https://thunlp-mt.github.io/CODIS.