 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGRO-SQL: Agentic Group-Relative Optimization with High-Fidelity Data Synthesis
Dec 29, 2025The advancement of Text-to-SQL systems is currently hindered by the scarcity of high-quality training data and the limited reasoning capabilities of models in complex scenarios. In this paper, we propose a holistic framework that addresses these issues through a dual-centric approach. From a Data-Centric perspective, we construct an iterative data factory that synthesizes RL-ready data characterized by high correctness and precise semantic-logic alignment, ensured by strict verification. From a Model-Centric perspective, we introduce a novel Agentic Reinforcement Learning framework. This framework employs a Diversity-Aware Cold Start stage to initialize a robust policy, followed by Group Relative Policy Optimization (GRPO) to refine the agent's reasoning via environmental feedback. Extensive experiments on BIRD and Spider benchmarks demonstrate that our synergistic approach achieves state-of-the-art performance among single-model methods.
ALFEE: Adaptive Large Foundation Model for EEG Representation
May 07, 2025While foundation models excel in text, image, and video domains, the critical biological signals, particularly electroencephalography(EEG), remain underexplored. EEG benefits neurological research with its high temporal resolution, operational practicality, and safety profile. However, low signal-to-noise ratio, inter-subject variability, and cross-paradigm differences hinder the generalization of current models. Existing methods often employ simplified strategies, such as a single loss function or a channel-temporal joint representation module, and suffer from a domain gap between pretraining and evaluation tasks that compromises efficiency and adaptability. To address these limitations, we propose the Adaptive Large Foundation model for EEG signal representation(ALFEE) framework, a novel hybrid transformer architecture with two learning stages for robust EEG representation learning. ALFEE employs a hybrid attention that separates channel-wise feature aggregation from temporal dynamics modeling, enabling robust EEG representation with variable channel configurations. A channel encoder adaptively compresses variable channel information, a temporal encoder captures task-guided evolution, and a hybrid decoder reconstructs signals in both temporal and frequency domains. During pretraining, ALFEE optimizes task prediction, channel and temporal mask reconstruction, and temporal forecasting to enhance multi-scale and multi-channel representation. During fine-tuning, a full-model adaptation with a task-specific token dictionary and a cross-attention layer boosts performance across multiple tasks. After 25,000 hours of pretraining, extensive experimental results on six downstream EEG tasks demonstrate the superior performance of ALFEE over existing models. Our ALFEE framework establishes a scalable foundation for biological signal analysis with implementation at https://github.com/xw1216/ALFEE.
StreamingBench: Assessing the Gap for MLLMs to Achieve Streaming Video Understanding
Nov 06, 2024

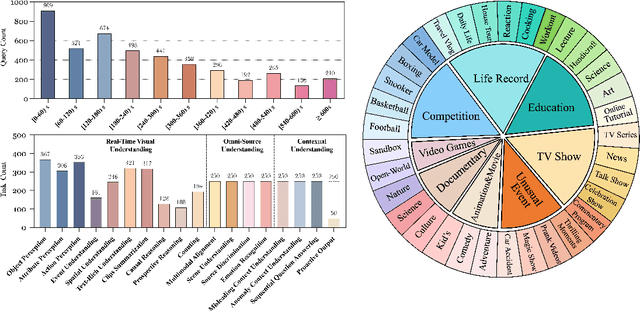

The rapid development of Multimodal Large Language Models (MLLMs) has expanded their capabilities from image comprehension to video understanding. However, most of these MLLMs focus primarily on offline video comprehension, necessitating extensive processing of all video frames before any queries can be made. This presents a significant gap compared to the human ability to watch, listen, think, and respond to streaming inputs in real time, highlighting the limitations of current MLLMs. In this paper, we introduce StreamingBench, the first comprehensive benchmark designed to evaluate the streaming video understanding capabilities of MLLMs. StreamingBench assesses three core aspects of streaming video understanding: (1) real-time visual understanding, (2) omni-source understanding, and (3) contextual understanding. The benchmark consists of 18 tasks, featuring 900 videos and 4,500 human-curated QA pairs. Each video features five questions presented at different time points to simulate a continuous streaming scenario. We conduct experiments on StreamingBench with 13 open-source and proprietary MLLMs and find that even the most advanced proprietary MLLMs like Gemini 1.5 Pro and GPT-4o perform significantly below human-level streaming video understanding capabilities. We hope our work can facilitate further advancements for MLLMs, empowering them to approach human-level video comprehension and interaction in more realistic scenarios.