 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$Z^*$: Zero-shot Style Transfer via Attention Rearrangement
Paper and Code
Nov 25, 2023

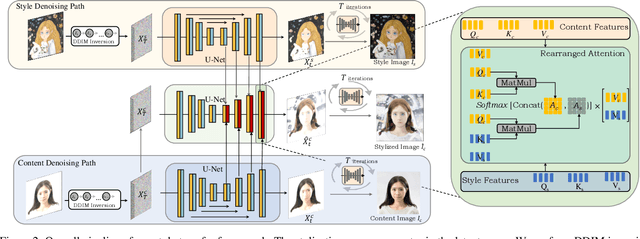
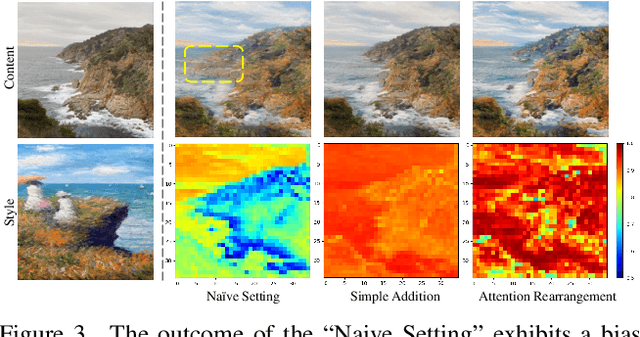
Despite the remarkable progress in image style transfer, formulating style in the context of art is inherently subjective and challenging. In contrast to existing learning/tuning methods, this study shows that vanilla diffusion models can directly extract style information and seamlessly integrate the generative prior into the content image without retraining. Specifically, we adopt dual denoising paths to represent content/style references in latent space and then guide the content image denoising process with style latent codes. We further reveal that the cross-attention mechanism in latent diffusion models tends to blend the content and style images, resulting in stylized outputs that deviate from the original content image. To overcome this limitation, we introduce a cross-attention rearrangement strategy. Through theoretical analysis and experiments, we demonstrate the effectiveness and superiority of the diffusion-based $\underline{Z}$ero-shot $\underline{S}$tyle $\underline{T}$ransfer via $\underline{A}$ttention $\underline{R}$earrangement, Z-STAR.