 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAFFormer: A Hierarchical Attention-Free Framework for Alzheimer's Disease Detection From Spontaneous Speech
Paper and Code
May 07, 2024


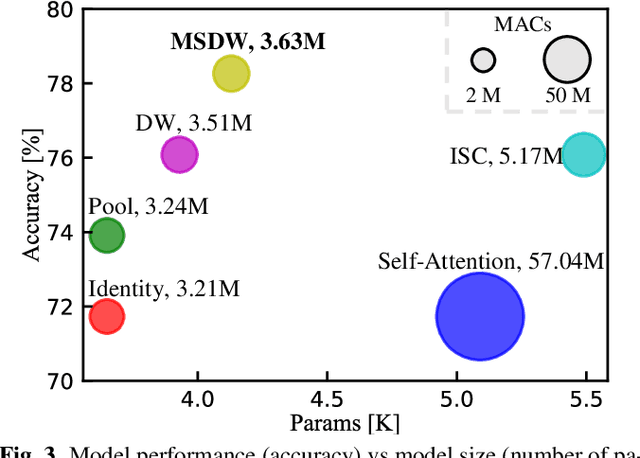
Automatically detecting Alzheimer's Disease (AD) from spontaneous speech plays an important role in its early diagnosis. Recent approaches highly rely on the Transformer architectures due to its efficiency in modelling long-range context dependencies. However, the quadratic increase in computational complexity associated with self-attention and the length of audio poses a challenge when deploying such models on edge devices. In this context, we construct a novel framework, namely Hierarchical Attention-Free Transformer (HAFFormer), to better deal with long speech for AD detection. Specifically, we employ an attention-free module of Multi-Scale Depthwise Convolution to replace the self-attention and thus avoid the expensive computation, and a GELU-based Gated Linear Unit to replace the feedforward layer, aiming to automatically filter out the redundant information. Moreover, we design a hierarchical structure to force it to learn a variety of information grains, from the frame level to the dialogue level. By conducting extensive experiments on the ADReSS-M dataset, the introduced HAFFormer can achieve competitive results (82.6% accuracy) with other recent work, but with significant computational complexity and model size reduction compared to the standard Transformer. This shows the efficiency of HAFFormer in dealing with long audio for AD detection.