 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUD-TGN: Advancing Action Unit Detection with Temporal Convolution and GPT-2 in Wild Audiovisual Contexts
Mar 20, 2024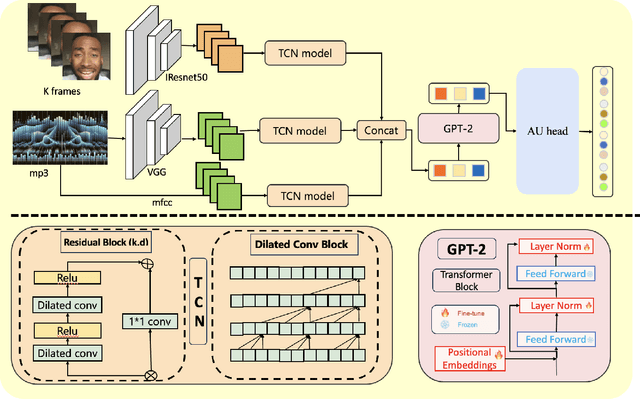
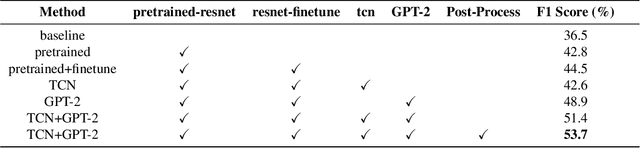
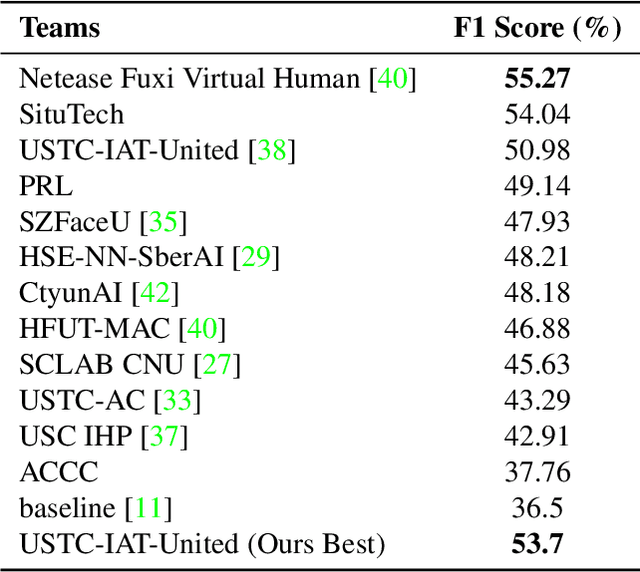
Leveraging the synergy of both audio data and visual data is essential for understanding human emotions and behaviors, especially in in-the-wild setting. Traditional methods for integrating such multimodal information often stumble, leading to less-than-ideal outcomes in the task of facial action unit detection. To overcome these shortcomings, we propose a novel approach utilizing audio-visual multimodal data. This method enhances audio feature extraction by leveraging Mel Frequency Cepstral Coefficients (MFCC) and Log-Mel spectrogram features alongside a pre-trained VGGish network. Moreover, this paper adaptively captures fusion features across modalities by modeling the temporal relationships, and ultilizes a pre-trained GPT-2 model for sophisticated context-aware fusion of multimodal information. Our method notably improves the accuracy of AU detection by understanding the temporal and contextual nuances of the data, showcasing significant advancements in the comprehension of intricate scenarios. These findings underscore the potential of integrating temporal dynamics and contextual interpretation, paving the way for future research endeavors.
Multimodal Fusion Method with Spatiotemporal Sequences and Relationship Learning for Valence-Arousal Estimation
Mar 20, 2024


This paper presents our approach for the VA (Valence-Arousal) estimation task in the ABAW6 competition. We devised a comprehensive model by preprocessing video frames and audio segments to extract visual and audio features. Through the utilization of Temporal Convolutional Network (TCN) modules, we effectively captured the temporal and spatial correlations between these features. Subsequently, we employed a Transformer encoder structure to learn long-range dependencies, thereby enhancing the model's performance and generalization ability. Our method leverages a multimodal data fusion approach, integrating pre-trained audio and video backbones for feature extraction, followed by TCN-based spatiotemporal encoding and Transformer-based temporal information capture. Experimental results demonstrate the effectiveness of our approach, achieving competitive performance in VA estimation on the AffWild2 dataset.
Exploring Facial Expression Recognition through Semi-Supervised Pretraining and Temporal Modeling
Mar 19, 2024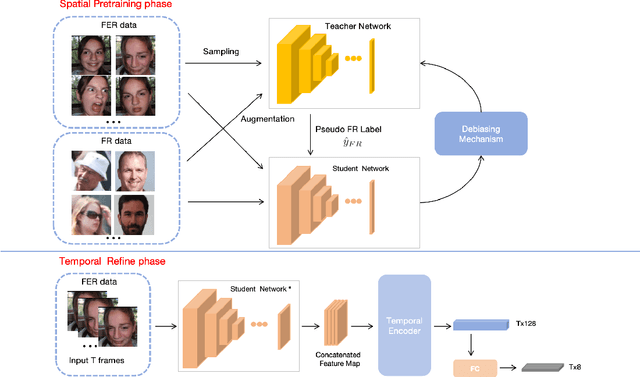

Facial Expression Recognition (FER) plays a crucial role in computer vision and finds extensive applications across various fields. This paper aims to present our approach for the upcoming 6th Affective Behavior Analysis in-the-Wild (ABAW) competition, scheduled to be held at CVPR2024. In the facial expression recognition task, The limited size of the FER dataset poses a challenge to the expression recognition model's generalization ability, resulting in subpar recognition performance. To address this problem, we employ a semi-supervised learning technique to generate expression category pseudo-labels for unlabeled face data. At the same time, we uniformly sampled the labeled facial expression samples and implemented a debiased feedback learning strategy to address the problem of category imbalance in the dataset and the possible data bias in semi-supervised learning. Moreover, to further compensate for the limitation and bias of features obtained only from static images, we introduced a Temporal Encoder to learn and capture temporal relationships between neighbouring expression image features. In the 6th ABAW competition, our method achieved outstanding results on the official validation set, a result that fully confirms the effectiveness and competitiveness of our proposed method.