 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignCap: Aligning Speech Emotion Captioning to Human Preferences
Paper and Code
Oct 24, 2024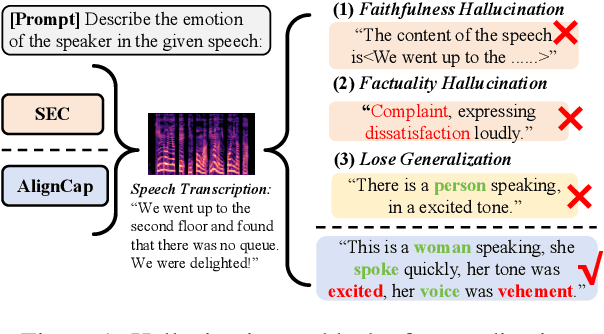

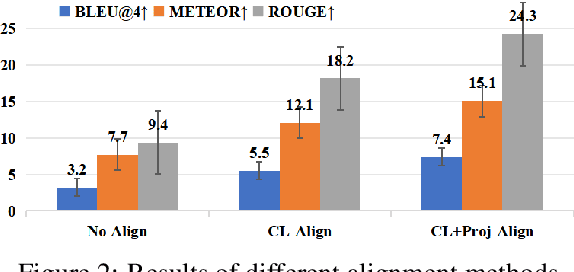
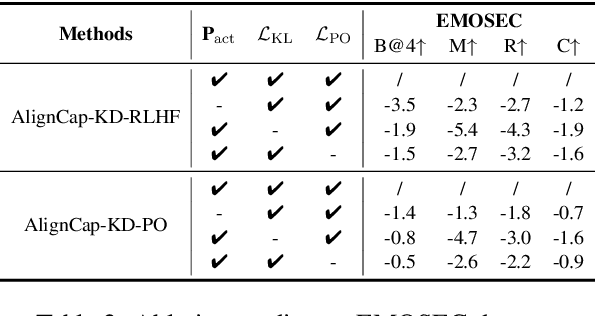
Speech Emotion Captioning (SEC) has gradually become an active research task. The emotional content conveyed through human speech are often complex, and classifying them into fixed categories may not be enough to fully capture speech emotions. Describing speech emotions through natural language may be a more effective approach. However, existing SEC methods often produce hallucinations and lose generalization on unseen speech. To overcome these problems, we propose AlignCap, which Aligning Speech Emotion Captioning to Human Preferences based on large language model (LLM) with two properties: 1) Speech-Text Alignment, which minimizing the divergence between the LLM's response prediction distributions for speech and text inputs using knowledge distillation (KD) Regularization. 2) Human Preference Alignment, where we design Preference Optimization (PO) Regularization to eliminate factuality and faithfulness hallucinations. We also extract emotional clues as a prompt for enriching fine-grained information under KD-Regularization. Experiments demonstrate that AlignCap presents stronger performance to other state-of-the-art methods on Zero-shot SEC task.