 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRREH: Reconstruction Relations Embedded Hashing for Semi-Paired Cross-Modal Retrieval
Paper and Code
May 28, 2024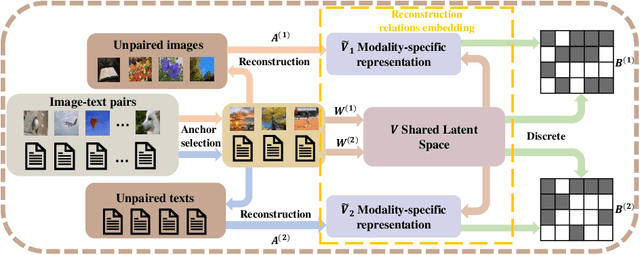
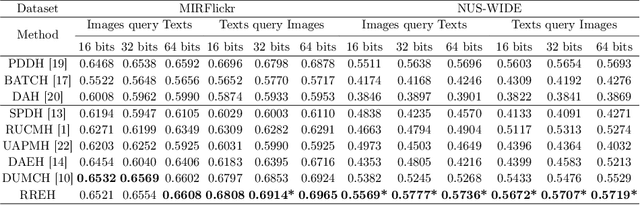
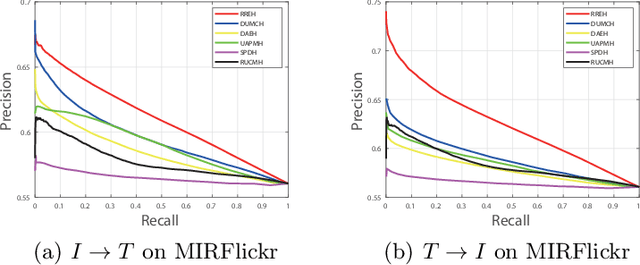
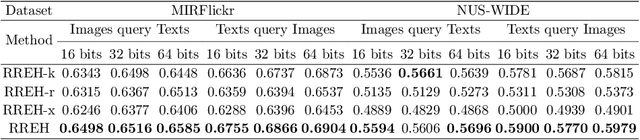
Known for efficient computation and easy storage, hashing has been extensively explored in cross-modal retrieval. The majority of current hashing models are predicated on the premise of a direct one-to-one mapping between data points. However, in real practice, data correspondence across modalities may be partially provided. In this research, we introduce an innovative unsupervised hashing technique designed for semi-paired cross-modal retrieval tasks, named Reconstruction Relations Embedded Hashing (RREH). RREH assumes that multi-modal data share a common subspace. For paired data, RREH explores the latent consistent information of heterogeneous modalities by seeking a shared representation. For unpaired data, to effectively capture the latent discriminative features, the high-order relationships between unpaired data and anchors are embedded into the latent subspace, which are computed by efficient linear reconstruction. The anchors are sampled from paired data, which improves the efficiency of hash learning. The RREH trains the underlying features and the binary encodings in a unified framework with high-order reconstruction relations preserved. With the well devised objective function and discrete optimization algorithm, RREH is designed to be scalable, making it suitable for large-scale datasets and facilitating efficient cross-modal retrieval. In the evaluation process, the proposed is tested with partially paired data to establish its superiority over several existing methods.