 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASSOD-Net: Cascaded and Separable Structures of Dilated Convolution for Embedded Vision Systems and Applications
Apr 29, 2021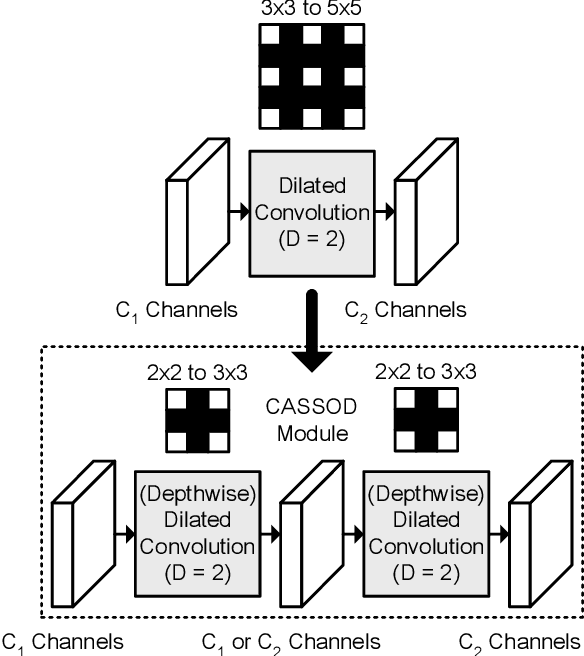

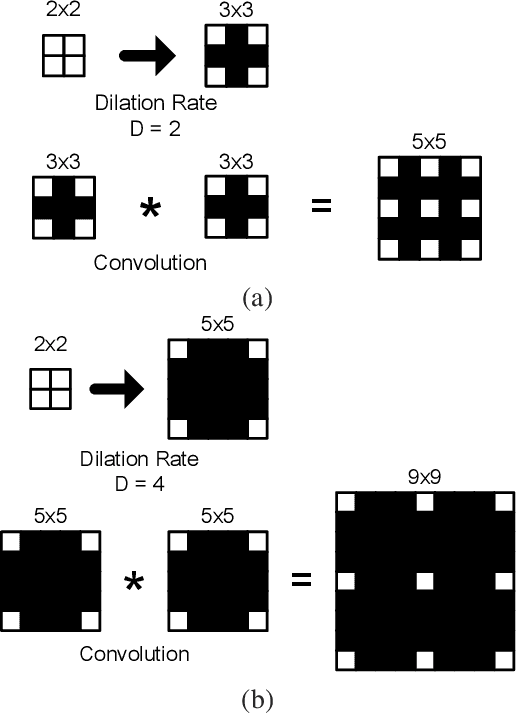
The field of view (FOV) of convolutional neural networks is highly related to the accuracy of inference. Dilated convolutions are known as an effective solution to the problems which require large FOVs. However, for general-purpose hardware or dedicated hardware, it usually takes extra time to handle dilated convolutions compared with standard convolutions. In this paper, we propose a network module, Cascaded and Separable Structure of Dilated (CASSOD) Convolution, and a special hardware system to handle the CASSOD networks efficiently. A CASSOD-Net includes multiple cascaded $2 \times 2$ dilated filters, which can be used to replace the traditional $3 \times 3$ dilated filters without decreasing the accuracy of inference. Two example applications, face detection and image segmentation, are tested with dilated convolutions and the proposed CASSOD modules. The new network for face detection achieves higher accuracy than the previous work with only 47% of filter weights in the dilated convolution layers of the context module. Moreover, the proposed hardware system can accelerate the computations of dilated convolutions, and it is 2.78 times faster than traditional hardware systems when the filter size is $3 \times 3$.
Hardware Architecture of Embedded Inference Accelerator and Analysis of Algorithms for Depthwise and Large-Kernel Convolutions
Apr 29, 2021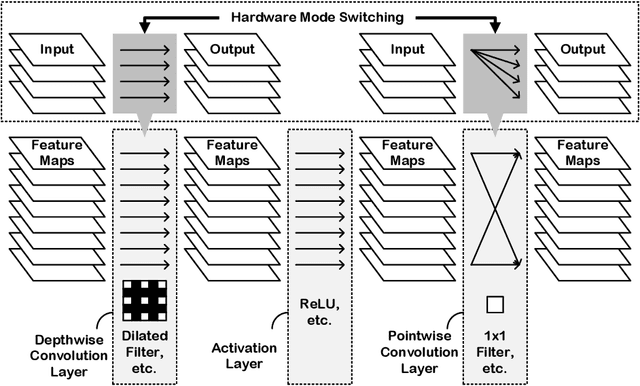
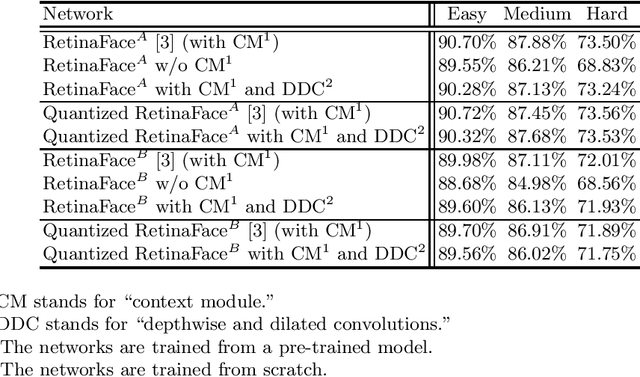
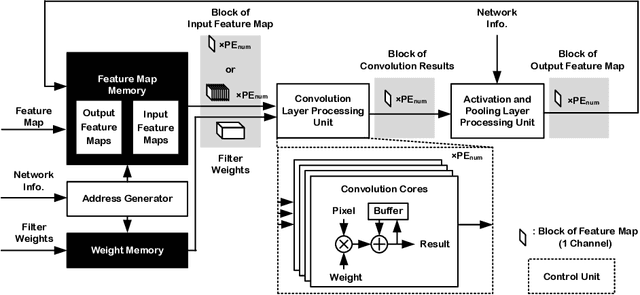
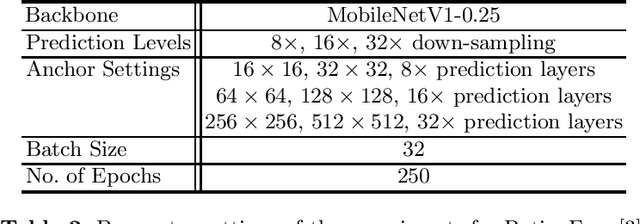
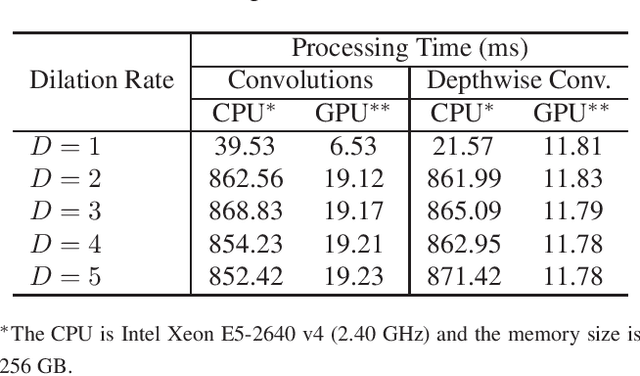
In order to handle modern convolutional neural networks (CNNs) efficiently, a hardware architecture of CNN inference accelerator is proposed to handle depthwise convolutions and regular convolutions, which are both essential building blocks for embedded-computer-vision algorithms. Different from related works, the proposed architecture can support filter kernels with different sizes with high flexibility since it does not require extra costs for intra-kernel parallelism, and it can generate convolution results faster than the architecture of the related works. The experimental results show the importance of supporting depthwise convolutions and dilated convolutions with the proposed hardware architecture. In addition to depthwise convolutions with large-kernels, a new structure called DDC layer, which includes the combination of depthwise convolutions and dilated convolutions, is also analyzed in this paper. For face detection, the computational costs decrease by 30%, and the model size decreases by 20% when the DDC layers are applied to the network. For image classification, the accuracy is increased by 1% by simply replacing $3 \times 3$ filters with $5 \times 5$ filters in depthwise convolutions.
* Camera-ready version for ECCV 2020 workshop (Embedded Vision Workshop)
BAMSProd: A Step towards Generalizing the Adaptive Optimization Methods to Deep Binary Model
Sep 29, 2020
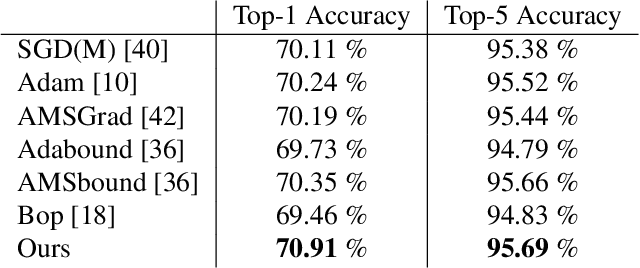

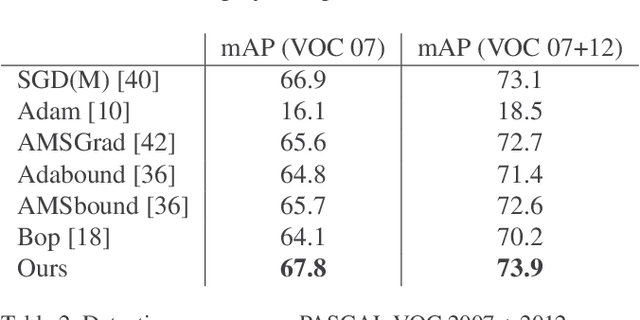
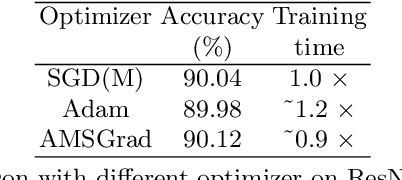
Recent methods have significantly reduced the performance degradation of Binary Neural Networks (BNNs), but guaranteeing the effective and efficient training of BNNs is an unsolved problem. The main reason is that the estimated gradients produced by the Straight-Through-Estimator (STE) mismatches with the gradients of the real derivatives. In this paper, we provide an explicit convex optimization example where training the BNNs with the traditionally adaptive optimization methods still faces the risk of non-convergence, and identify that constraining the range of gradients is critical for optimizing the deep binary model to avoid highly suboptimal solutions. For solving above issues, we propose a BAMSProd algorithm with a key observation that the convergence property of optimizing deep binary model is strongly related to the quantization errors. In brief, it employs an adaptive range constraint via an errors measurement for smoothing the gradients transition while follows the exponential moving strategy from AMSGrad to avoid errors accumulation during the optimization. The experiments verify the corollary of theoretical convergence analysis, and further demonstrate that our optimization method can speed up the convergence about 1:2x and boost the performance of BNNs to a significant level than the specific binary optimizer about 3:7%, even in a highly non-convex optimization problem.
* 10 pages, 4 figures, 2 tables
QuantNet: Learning to Quantize by Learning within Fully Differentiable Framework
Sep 10, 2020
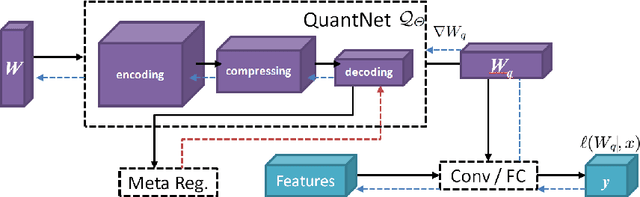

Despite the achievements of recent binarization methods on reducing the performance degradation of Binary Neural Networks (BNNs), gradient mismatching caused by the Straight-Through-Estimator (STE) still dominates quantized networks. This paper proposes a meta-based quantizer named QuantNet, which utilizes a differentiable sub-network to directly binarize the full-precision weights without resorting to STE and any learnable gradient estimators. Our method not only solves the problem of gradient mismatching, but also reduces the impact of discretization errors, caused by the binarizing operation in the deployment, on performance. Generally, the proposed algorithm is implemented within a fully differentiable framework, and is easily extended to the general network quantization with any bits. The quantitative experiments on CIFAR-100 and ImageNet demonstrate that QuantNet achieves the signifficant improvements comparing with previous binarization methods, and even bridges gaps of accuracies between binarized models and full-precision models.