 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONVIQT: Contrastive Video Quality Estimator
Paper and Code
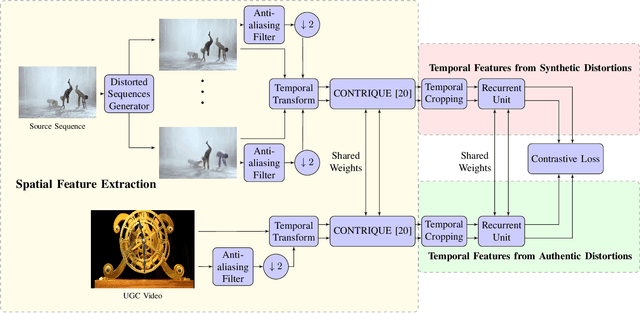
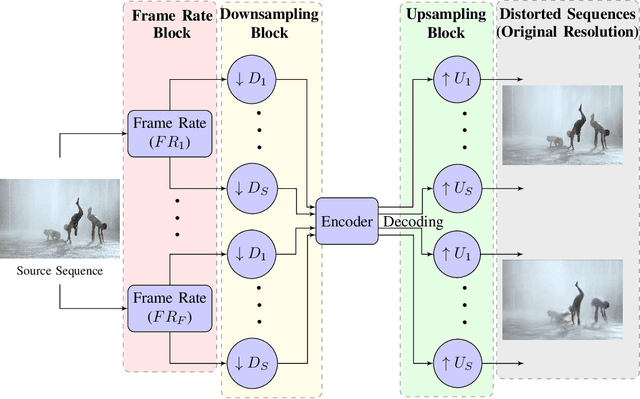


Perceptual video quality assessment (VQA) is an integral component of many streaming and video sharing platforms. Here we consider the problem of learning perceptually relevant video quality representations in a self-supervised manner. Distortion type identification and degradation level determination is employed as an auxiliary task to train a deep learning model containing a deep Convolutional Neural Network (CNN) that extracts spatial features, as well as a recurrent unit that captures temporal information. The model is trained using a contrastive loss and we therefore refer to this training framework and resulting model as CONtrastive VIdeo Quality EstimaTor (CONVIQT). During testing, the weights of the trained model are frozen, and a linear regressor maps the learned features to quality scores in a no-reference (NR) setting. We conduct comprehensive evaluations of the proposed model on multiple VQA databases by analyzing the correlations between model predictions and ground-truth quality ratings, and achieve competitive performance when compared to state-of-the-art NR-VQA models, even though it is not trained on those databases. Our ablation experiments demonstrate that the learned representations are highly robust and generalize well across synthetic and realistic distortions. Our results indicate that compelling representations with perceptual bearing can be obtained using self-supervised learning. The implementations used in this work have been made available at https://github.com/pavancm/CONVIQT.