 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Distributed Learning via Lazily Aggregated Quantized Gradients
Paper and Code

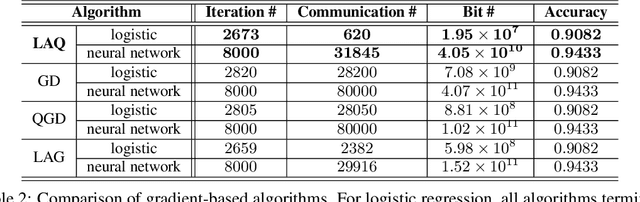

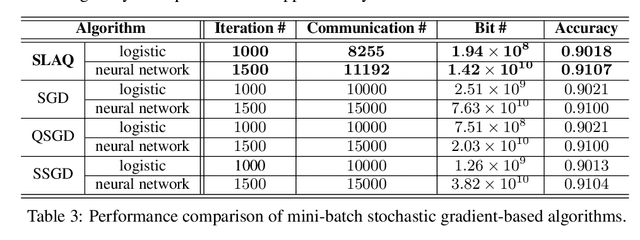
The present paper develops a novel aggregated gradient approach for distributed machine learning that adaptively compresses the gradient communication. The key idea is to first quantize the computed gradients, and then skip less informative quantized gradient communications by reusing outdated gradients. Quantizing and skipping result in `lazy' worker-server communications, which justifies the term Lazily Aggregated Quantized gradient that is henceforth abbreviated as LAQ. Our LAQ can provably attain the same linear convergence rate as the gradient descent in the strongly convex case, while effecting major savings in the communication overhead both in transmitted bits as well as in communication rounds. Empirically, experiments with real data corroborate a significant communication reduction compared to existing gradient- and stochastic gradient-based algorithms.