 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomagic: Crossmodal Prompt-driven Zero-shot Anomaly Generation
Nov 13, 2025We propose Anomagic, a zero-shot anomaly generation method that produces semantically coherent anomalies without requiring any exemplar anomalies. By unifying both visual and textual cues through a crossmodal prompt encoding scheme, Anomagic leverages rich contextual information to steer an inpainting-based generation pipeline. A subsequent contrastive refinement strategy enforces precise alignment between synthesized anomalies and their masks, thereby bolstering downstream anomaly detection accuracy. To facilitate training, we introduce AnomVerse, a collection of 12,987 anomaly-mask-caption triplets assembled from 13 publicly available datasets, where captions are automatically generated by multimodal large language models using structured visual prompts and template-based textual hints. Extensive experiments demonstrate that Anomagic trained on AnomVerse can synthesize more realistic and varied anomalies than prior methods, yielding superior improvements in downstream anomaly detection. Furthermore, Anomagic can generate anomalies for any normal-category image using user-defined prompts, establishing a versatile foundation model for anomaly generation.
Center-aware Residual Anomaly Synthesis for Multi-class Industrial Anomaly Detection
May 23, 2025Anomaly detection plays a vital role in the inspection of industrial images. Most existing methods require separate models for each category, resulting in multiplied deployment costs. This highlights the challenge of developing a unified model for multi-class anomaly detection. However, the significant increase in inter-class interference leads to severe missed detections. Furthermore, the intra-class overlap between normal and abnormal samples, particularly in synthesis-based methods, cannot be ignored and may lead to over-detection. To tackle these issues, we propose a novel Center-aware Residual Anomaly Synthesis (CRAS) method for multi-class anomaly detection. CRAS leverages center-aware residual learning to couple samples from different categories into a unified center, mitigating the effects of inter-class interference. To further reduce intra-class overlap, CRAS introduces distance-guided anomaly synthesis that adaptively adjusts noise variance based on normal data distribution. Experimental results on diverse datasets and real-world industrial applications demonstrate the superior detection accuracy and competitive inference speed of CRAS. The source code and the newly constructed dataset are publicly available at https://github.com/cqylunlun/CRAS.
Exploring Intrinsic Normal Prototypes within a Single Image for Universal Anomaly Detection
Mar 04, 2025Anomaly detection (AD) is essential for industrial inspection, yet existing methods typically rely on ``comparing'' test images to normal references from a training set. However, variations in appearance and positioning often complicate the alignment of these references with the test image, limiting detection accuracy. We observe that most anomalies manifest as local variations, meaning that even within anomalous images, valuable normal information remains. We argue that this information is useful and may be more aligned with the anomalies since both the anomalies and the normal information originate from the same image. Therefore, rather than relying on external normality from the training set, we propose INP-Former, a novel method that extracts Intrinsic Normal Prototypes (INPs) directly from the test image. Specifically, we introduce the INP Extractor, which linearly combines normal tokens to represent INPs. We further propose an INP Coherence Loss to ensure INPs can faithfully represent normality for the testing image. These INPs then guide the INP-Guided Decoder to reconstruct only normal tokens, with reconstruction errors serving as anomaly scores. Additionally, we propose a Soft Mining Loss to prioritize hard-to-optimize samples during training. INP-Former achieves state-of-the-art performance in single-class, multi-class, and few-shot AD tasks across MVTec-AD, VisA, and Real-IAD, positioning it as a versatile and universal solution for AD. Remarkably, INP-Former also demonstrates some zero-shot AD capability. Code is available at:https://github.com/luow23/INP-Former.
Self-Calibrated Dual Contrasting for Annotation-Efficient Bacteria Raman Spectroscopy Clustering and Classification
Dec 28, 2024
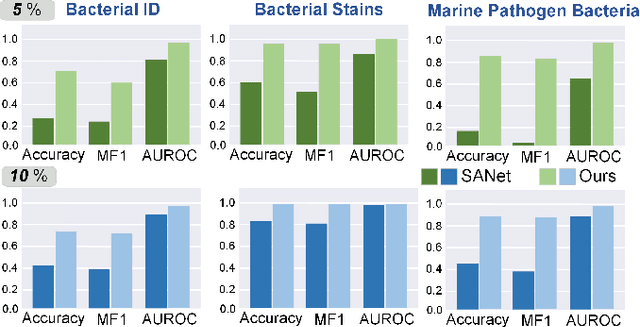


Raman scattering is based on molecular vibration spectroscopy and provides a powerful technology for pathogenic bacteria diagnosis using the unique molecular fingerprint information of a substance. The integration of deep learning technology has significantly improved the efficiency and accuracy of intelligent Raman spectroscopy (RS) recognition. However, the current RS recognition methods based on deep neural networks still require the annotation of a large amount of spectral data, which is labor-intensive. This paper presents a novel annotation-efficient Self-Calibrated Dual Contrasting (SCDC) method for RS recognition that operates effectively with few or no annotation. Our core motivation is to represent the spectrum from two different perspectives in two distinct subspaces: embedding and category. The embedding perspective captures instance-level information, while the category perspective reflects category-level information. Accordingly, we have implemented a dual contrastive learning approach from two perspectives to obtain discriminative representations, which are applicable for Raman spectroscopy recognition under both unsupervised and semi-supervised learning conditions. Furthermore, a self-calibration mechanism is proposed to enhance robustness. Validation of the identification task on three large-scale bacterial Raman spectroscopy datasets demonstrates that our SCDC method achieves robust recognition performance with very few (5$\%$ or 10$\%$) or no annotations, highlighting the potential of the proposed method for biospectral identification in annotation-efficient clinical scenarios.
VarAD: Lightweight High-Resolution Image Anomaly Detection via Visual Autoregressive Modeling
Dec 23, 2024This paper addresses a practical task: High-Resolution Image Anomaly Detection (HRIAD). In comparison to conventional image anomaly detection for low-resolution images, HRIAD imposes a heavier computational burden and necessitates superior global information capture capacity. To tackle HRIAD, this paper translates image anomaly detection into visual token prediction and proposes VarAD based on visual autoregressive modeling for token prediction. Specifically, VarAD first extracts multi-hierarchy and multi-directional visual token sequences, and then employs an advanced model, Mamba, for visual autoregressive modeling and token prediction. During the prediction process, VarAD effectively exploits information from all preceding tokens to predict the target token. Finally, the discrepancies between predicted tokens and original tokens are utilized to score anomalies. Comprehensive experiments on four publicly available datasets and a real-world button inspection dataset demonstrate that the proposed VarAD achieves superior high-resolution image anomaly detection performance while maintaining lightweight, rendering VarAD a viable solution for HRIAD. Code is available at \href{https://github.com/caoyunkang/VarAD}{\url{https://github.com/caoyunkang/VarAD}}.
AMI-Net: Adaptive Mask Inpainting Network for Industrial Anomaly Detection and Localization
Dec 16, 2024Unsupervised visual anomaly detection is crucial for enhancing industrial production quality and efficiency. Among unsupervised methods, reconstruction approaches are popular due to their simplicity and effectiveness. The key aspect of reconstruction methods lies in the restoration of anomalous regions, which current methods have not satisfactorily achieved. To tackle this issue, we introduce a novel \uline{A}daptive \uline{M}ask \uline{I}npainting \uline{Net}work (AMI-Net) from the perspective of adaptive mask-inpainting. In contrast to traditional reconstruction methods that treat non-semantic image pixels as targets, our method uses a pre-trained network to extract multi-scale semantic features as reconstruction targets. Given the multiscale nature of industrial defects, we incorporate a training strategy involving random positional and quantitative masking. Moreover, we propose an innovative adaptive mask generator capable of generating adaptive masks that effectively mask anomalous regions while preserving normal regions. In this manner, the model can leverage the visible normal global contextual information to restore the masked anomalous regions, thereby effectively suppressing the reconstruction of defects. Extensive experimental results on the MVTec AD and BTAD industrial datasets validate the effectiveness of the proposed method. Additionally, AMI-Net exhibits exceptional real-time performance, striking a favorable balance between detection accuracy and speed, rendering it highly suitable for industrial applications. Code is available at: https://github.com/luow23/AMI-Net
DiffRaman: A Conditional Latent Denoising Diffusion Probabilistic Model for Bacterial Raman Spectroscopy Identification Under Limited Data Conditions
Dec 11, 2024



Raman spectroscopy has attracted significant attention in various biochemical detection fields, especially in the rapid identification of pathogenic bacteria. The integration of this technology with deep learning to facilitate automated bacterial Raman spectroscopy diagnosis has emerged as a key focus in recent research. However, the diagnostic performance of existing deep learning methods largely depends on a sufficient dataset, and in scenarios where there is a limited availability of Raman spectroscopy data, it is inadequate to fully optimize the numerous parameters of deep neural networks. To address these challenges, this paper proposes a data generation method utilizing deep generative models to expand the data volume and enhance the recognition accuracy of bacterial Raman spectra. Specifically, we introduce DiffRaman, a conditional latent denoising diffusion probability model for Raman spectra generation. Experimental results demonstrate that synthetic bacterial Raman spectra generated by DiffRaman can effectively emulate real experimental spectra, thereby enhancing the performance of diagnostic models, especially under conditions of limited data. Furthermore, compared to existing generative models, the proposed DiffRaman offers improvements in both generation quality and computational efficiency. Our DiffRaman approach offers a well-suited solution for automated bacteria Raman spectroscopy diagnosis in data-scarce scenarios, offering new insights into alleviating the labor of spectroscopic measurements and enhancing rare bacteria identification.
Adversarial Contrastive Domain-Generative Learning for Bacteria Raman Spectrum Joint Denoising and Cross-Domain Identification
Dec 11, 2024



Raman spectroscopy, as a label-free detection technology, has been widely utilized in the clinical diagnosis of pathogenic bacteria. However, Raman signals are naturally weak and sensitive to the condition of the acquisition process. The characteristic spectra of a bacteria can manifest varying signal-to-noise ratios and domain discrepancies under different acquisition conditions. Consequently, existing methods often face challenges when making identification for unobserved acquisition conditions, i.e., the testing acquisition conditions are unavailable during model training. In this article, a generic framework, namely, an adversarial contrastive domain-generative learning framework, is proposed for joint Raman spectroscopy denoising and cross-domain identification. The proposed method is composed of a domain generation module and a domain task module. Through adversarial learning between these two modules, it utilizes only a single available source domain spectral data to generate extended denoised domains that are semantically consistent with the source domain and extracts domain-invariant representations. Comprehensive case studies indicate that the proposed method can simultaneously conduct spectral denoising without necessitating noise-free ground-truth and can achieve improved diagnostic accuracy and robustness under cross-domain unseen spectral acquisition conditions. This suggests that the proposed method holds remarkable potential as a diagnostic tool in real clinical cases.
Prior Normality Prompt Transformer for Multi-class Industrial Image Anomaly Detection
Jun 17, 2024



Image anomaly detection plays a pivotal role in industrial inspection. Traditional approaches often demand distinct models for specific categories, resulting in substantial deployment costs. This raises concerns about multi-class anomaly detection, where a unified model is developed for multiple classes. However, applying conventional methods, particularly reconstruction-based models, directly to multi-class scenarios encounters challenges such as identical shortcut learning, hindering effective discrimination between normal and abnormal instances. To tackle this issue, our study introduces the Prior Normality Prompt Transformer (PNPT) method for multi-class image anomaly detection. PNPT strategically incorporates normal semantics prompting to mitigate the "identical mapping" problem. This entails integrating a prior normality prompt into the reconstruction process, yielding a dual-stream model. This innovative architecture combines normal prior semantics with abnormal samples, enabling dual-stream reconstruction grounded in both prior knowledge and intrinsic sample characteristics. PNPT comprises four essential modules: Class-Specific Normality Prompting Pool (CS-NPP), Hierarchical Patch Embedding (HPE), Semantic Alignment Coupling Encoding (SACE), and Contextual Semantic Conditional Decoding (CSCD). Experimental validation on diverse benchmark datasets and real-world industrial applications highlights PNPT's superior performance in multi-class industrial anomaly detection.
Global-Regularized Neighborhood Regression for Efficient Zero-Shot Texture Anomaly Detection
Jun 11, 2024



Texture surface anomaly detection finds widespread applications in industrial settings. However, existing methods often necessitate gathering numerous samples for model training. Moreover, they predominantly operate within a close-set detection framework, limiting their ability to identify anomalies beyond the training dataset. To tackle these challenges, this paper introduces a novel zero-shot texture anomaly detection method named Global-Regularized Neighborhood Regression (GRNR). Unlike conventional approaches, GRNR can detect anomalies on arbitrary textured surfaces without any training data or cost. Drawing from human visual cognition, GRNR derives two intrinsic prior supports directly from the test texture image: local neighborhood priors characterized by coherent similarities and global normality priors featuring typical normal patterns. The fundamental principle of GRNR involves utilizing the two extracted intrinsic support priors for self-reconstructive regression of the query sample. This process employs the transformation facilitated by local neighbor support while being regularized by global normality support, aiming to not only achieve visually consistent reconstruction results but also preserve normality properties. We validate the effectiveness of GRNR across various industrial scenarios using eight benchmark datasets, demonstrating its superior detection performance without the need for training data. Remarkably, our method is applicable for open-set texture defect detection and can even surpass existing vanilla approaches that require extensive training.