 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrast with Reconstruct: Contrastive 3D Representation Learning Guided by Generative Pretraining
Paper and Code
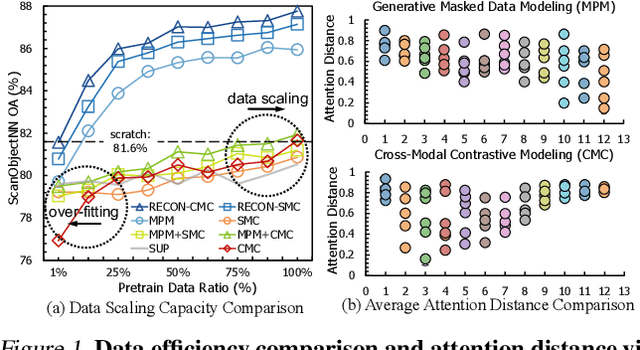
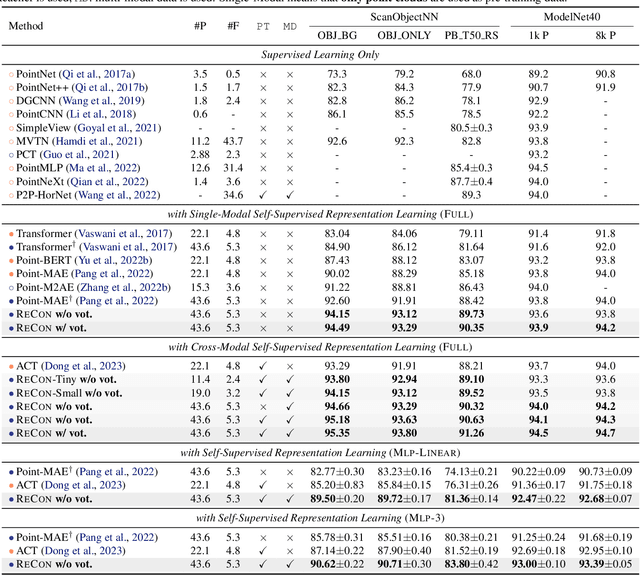
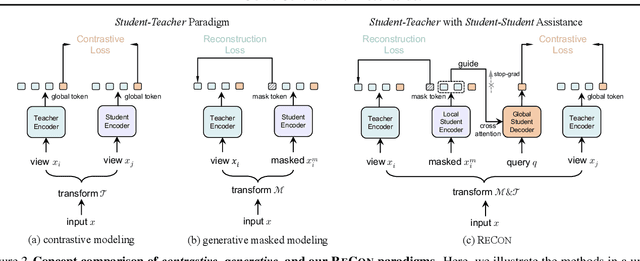
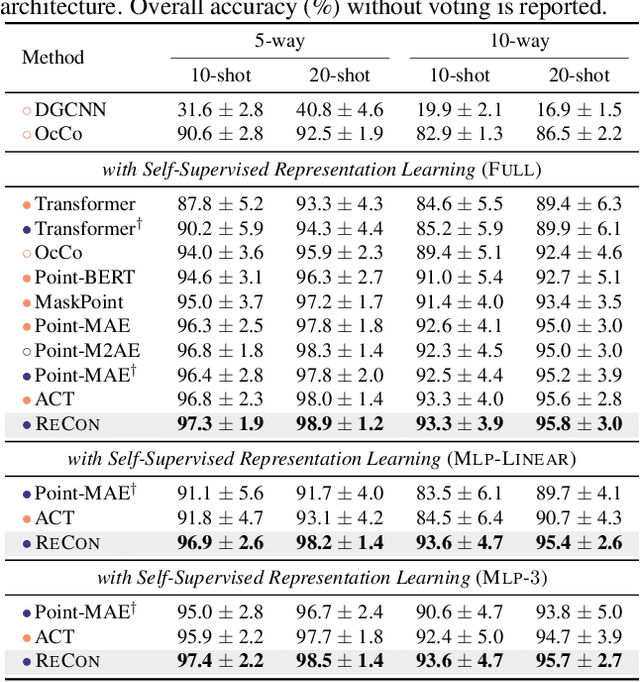
Mainstream 3D representation learning approaches are built upon contrastive or generative modeling pretext tasks, where great improvements in performance on various downstream tasks have been achieved. However, by investigating the methods of these two paradigms, we find that (i) contrastive models are data-hungry that suffer from a representation over-fitting issue; (ii) generative models have a data filling issue that shows inferior data scaling capacity compared to contrastive models. This motivates us to learn 3D representations by sharing the merits of both paradigms, which is non-trivial due to the pattern difference between the two paradigms. In this paper, we propose contrast with reconstruct (ReCon) that unifies these two paradigms. ReCon is trained to learn from both generative modeling teachers and cross-modal contrastive teachers through ensemble distillation, where the generative student guides the contrastive student. An encoder-decoder style ReCon-block is proposed that transfers knowledge through cross attention with stop-gradient, which avoids pretraining over-fitting and pattern difference issues. ReCon achieves a new state-of-the-art in 3D representation learning, e.g., 91.26% accuracy on ScanObjectNN. Codes will be released at https://github.com/qizekun/ReCon.