 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORSD: Class-Oriented Relational Self Distillation
Apr 28, 2023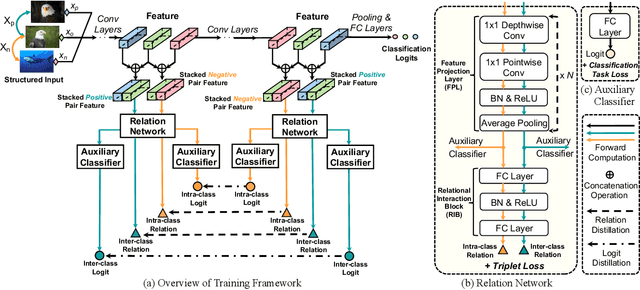
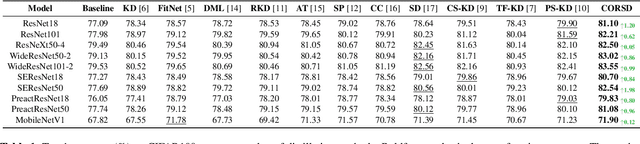
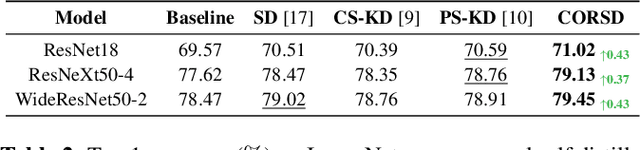
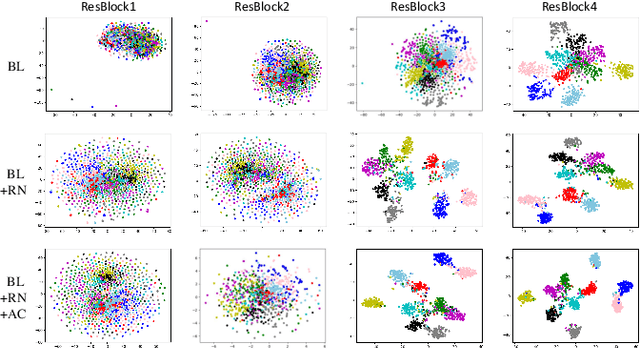
Knowledge distillation conducts an effective model compression method while holding some limitations:(1) the feature based distillation methods only focus on distilling the feature map but are lack of transferring the relation of data examples; (2) the relational distillation methods are either limited to the handcrafted functions for relation extraction, such as L2 norm, or weak in inter- and intra- class relation modeling. Besides, the feature divergence of heterogeneous teacher-student architectures may lead to inaccurate relational knowledge transferring. In this work, we propose a novel training framework named Class-Oriented Relational Self Distillation (CORSD) to address the limitations. The trainable relation networks are designed to extract relation of structured data input, and they enable the whole model to better classify samples by transferring the relational knowledge from the deepest layer of the model to shallow layers. Besides, auxiliary classifiers are proposed to make relation networks capture class-oriented relation that benefits classification task. Experiments demonstrate that CORSD achieves remarkable improvements. Compared to baseline, 3.8%, 1.5% and 4.5% averaged accuracy boost can be observed on CIFAR100, ImageNet and CUB-200-2011, respectively.
Multi-Glimpse Network: A Robust and Efficient Classification Architecture based on Recurrent Downsampled Attention
Nov 03, 2021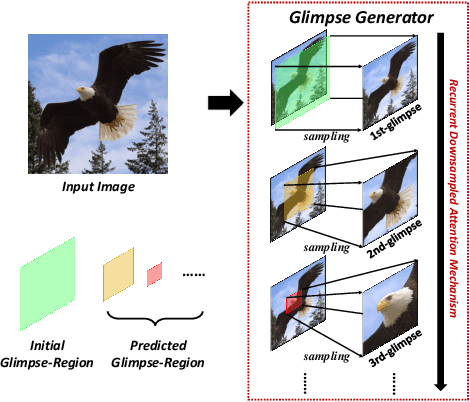
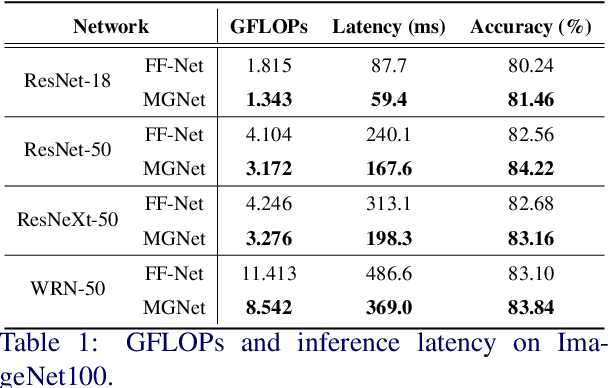
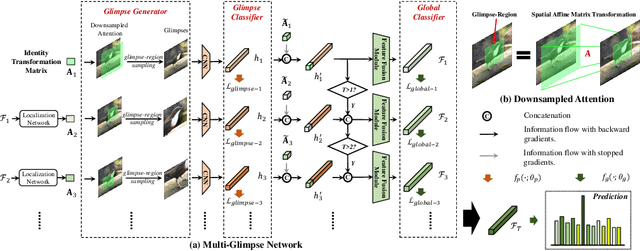
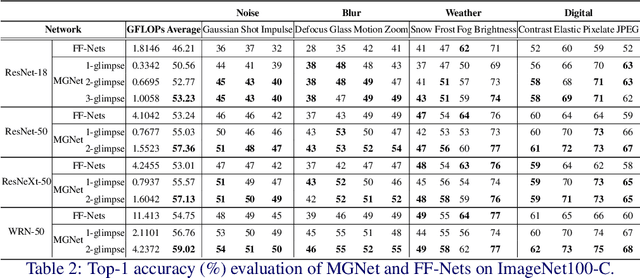
Most feedforward convolutional neural networks spend roughly the same efforts for each pixel. Yet human visual recognition is an interaction between eye movements and spatial attention, which we will have several glimpses of an object in different regions. Inspired by this observation, we propose an end-to-end trainable Multi-Glimpse Network (MGNet) which aims to tackle the challenges of high computation and the lack of robustness based on recurrent downsampled attention mechanism. Specifically, MGNet sequentially selects task-relevant regions of an image to focus on and then adaptively combines all collected information for the final prediction. MGNet expresses strong resistance against adversarial attacks and common corruptions with less computation. Also, MGNet is inherently more interpretable as it explicitly informs us where it focuses during each iteration. Our experiments on ImageNet100 demonstrate the potential of recurrent downsampled attention mechanisms to improve a single feedforward manner. For example, MGNet improves 4.76% accuracy on average in common corruptions with only 36.9% computational cost. Moreover, while the baseline incurs an accuracy drop to 7.6%, MGNet manages to maintain 44.2% accuracy in the same PGD attack strength with ResNet-50 backbone. Our code is available at https://github.com/siahuat0727/MGNet.
Non-structured DNN Weight Pruning Considered Harmful
Jul 03, 2019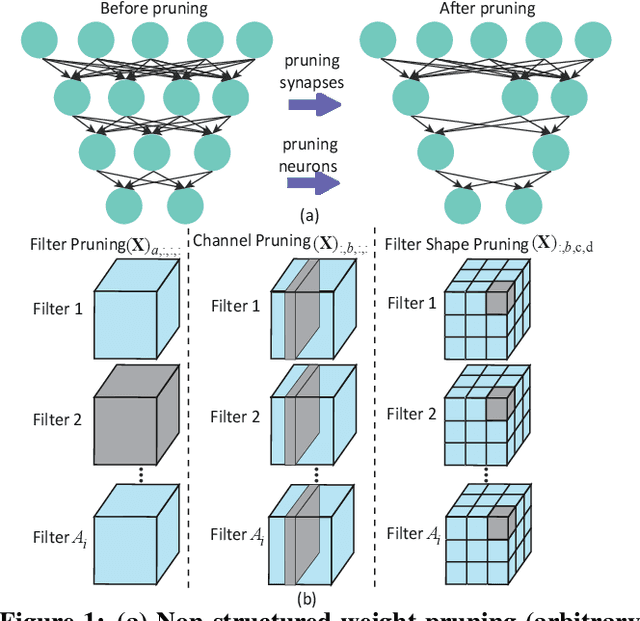
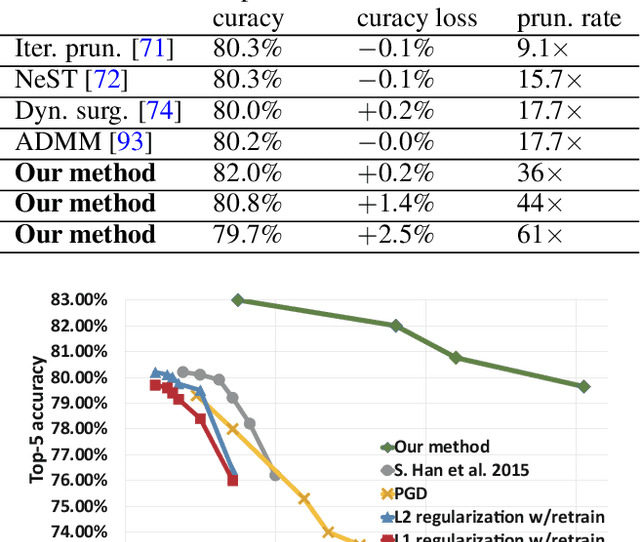
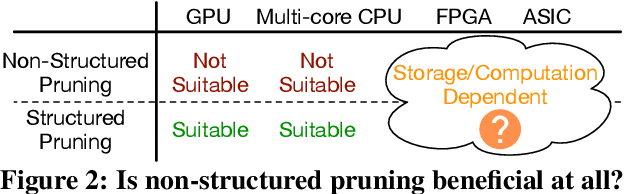
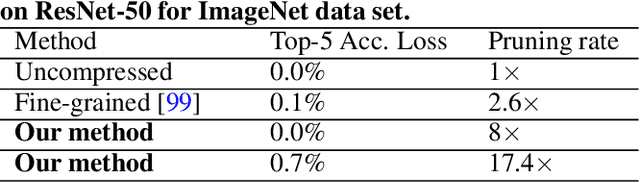
Large deep neural network (DNN) models pose the key challenge to energy efficiency due to the significantly higher energy consumption of off-chip DRAM accesses than arithmetic or SRAM operations. It motivates the intensive research on model compression with two main approaches. Weight pruning leverages the redundancy in the number of weights and can be performed in a non-structured, which has higher flexibility and pruning rate but incurs index accesses due to irregular weights, or structured manner, which preserves the full matrix structure with lower pruning rate. Weight quantization leverages the redundancy in the number of bits in weights. Compared to pruning, quantization is much more hardware-friendly, and has become a "must-do" step for FPGA and ASIC implementations. This paper provides a definitive answer to the question for the first time. First, we build ADMM-NN-S by extending and enhancing ADMM-NN, a recently proposed joint weight pruning and quantization framework. Second, we develop a methodology for fair and fundamental comparison of non-structured and structured pruning in terms of both storage and computation efficiency. Our results show that ADMM-NN-S consistently outperforms the prior art: (i) it achieves 348x, 36x, and 8x overall weight pruning on LeNet-5, AlexNet, and ResNet-50, respectively, with (almost) zero accuracy loss; (ii) we demonstrate the first fully binarized (for all layers) DNNs can be lossless in accuracy in many cases. These results provide a strong baseline and credibility of our study. Based on the proposed comparison framework, with the same accuracy and quantization, the results show that non-structrued pruning is not competitive in terms of both storage and computation efficiency. Thus, we conclude that non-structured pruning is considered harmful. We urge the community not to continue the DNN inference acceleration for non-structured sparsity.
Brain-inspired reverse adversarial examples
May 28, 2019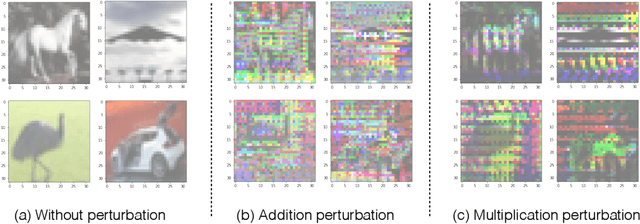


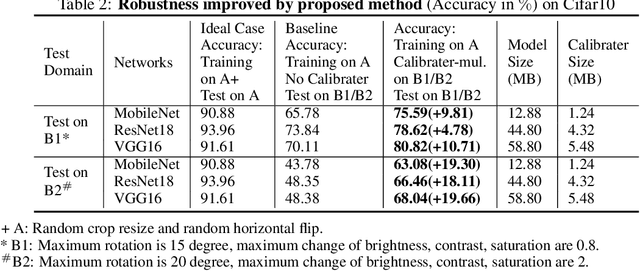
A human does not have to see all elephants to recognize an animal as an elephant. On contrast, current state-of-the-art deep learning approaches heavily depend on the variety of training samples and the capacity of the network. In practice, the size of network is always limited and it is impossible to access all the data samples. Under this circumstance, deep learning models are extremely fragile to human-imperceivable adversarial examples, which impose threats to all safety critical systems. Inspired by the association and attention mechanisms of the human brain, we propose reverse adversarial examples method that can greatly improve models' robustness on unseen data. Experiments show that our reverse adversarial method can improve accuracy on average 19.02% on ResNet18, MobileNet, and VGG16 on unseen data transformation. Besides, the proposed method is also applicable to compressed models and shows potential to compensate the robustness drop brought by model quantization - an absolute 30.78% accuracy improvement.