 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-inspired reverse adversarial examples
Paper and Code
May 28, 2019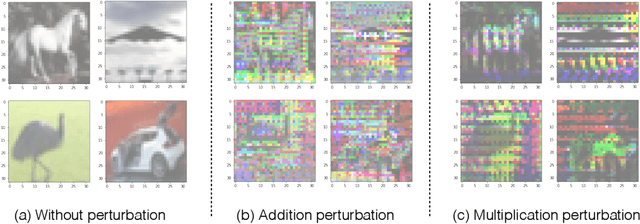


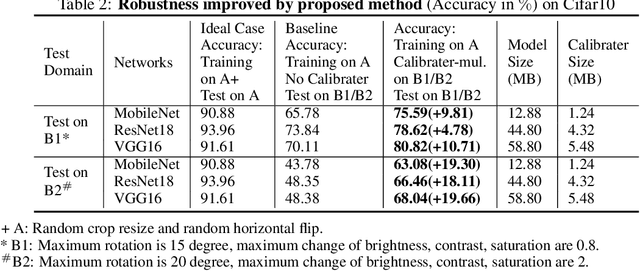
A human does not have to see all elephants to recognize an animal as an elephant. On contrast, current state-of-the-art deep learning approaches heavily depend on the variety of training samples and the capacity of the network. In practice, the size of network is always limited and it is impossible to access all the data samples. Under this circumstance, deep learning models are extremely fragile to human-imperceivable adversarial examples, which impose threats to all safety critical systems. Inspired by the association and attention mechanisms of the human brain, we propose reverse adversarial examples method that can greatly improve models' robustness on unseen data. Experiments show that our reverse adversarial method can improve accuracy on average 19.02% on ResNet18, MobileNet, and VGG16 on unseen data transformation. Besides, the proposed method is also applicable to compressed models and shows potential to compensate the robustness drop brought by model quantization - an absolute 30.78% accuracy improvement.