 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIMRL: A Novel Meta-Reinforcement Learning Framework for Non-Stationary and Multi-Task Environments
Jan 13, 2025In recent years, meta-reinforcement learning (meta-RL) algorithm has been proposed to improve sample efficiency in the field of decision-making and control, enabling agents to learn new knowledge from a small number of samples. However, most research uses the Gaussian distribution to extract task representation, which is poorly adapted to tasks that change in non-stationary environment. To address this problem, we propose a novel meta-reinforcement learning method by leveraging Gaussian mixture model and the transformer network to construct task inference model. The Gaussian mixture model is utilized to extend the task representation and conduct explicit encoding of tasks. Specifically, the classification of tasks is encoded through transformer network to determine the Gaussian component corresponding to the task. By leveraging task labels, the transformer network is trained using supervised learning. We validate our method on MuJoCo benchmarks with non-stationary and multi-task environments. Experimental results demonstrate that the proposed method dramatically improves sample efficiency and accurately recognizes the classification of the tasks, while performing excellently in the environment.
Fast and Accurate Multi-Agent Trajectory Prediction For Crowded Unknown Scenes
Jul 12, 2024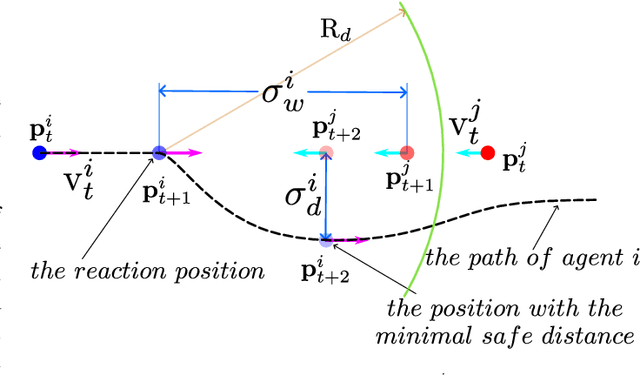

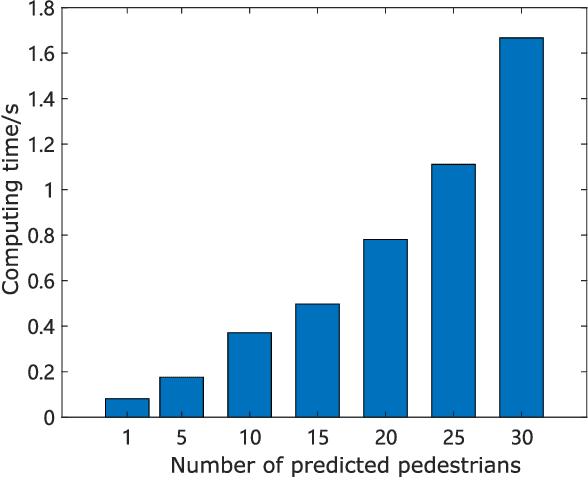
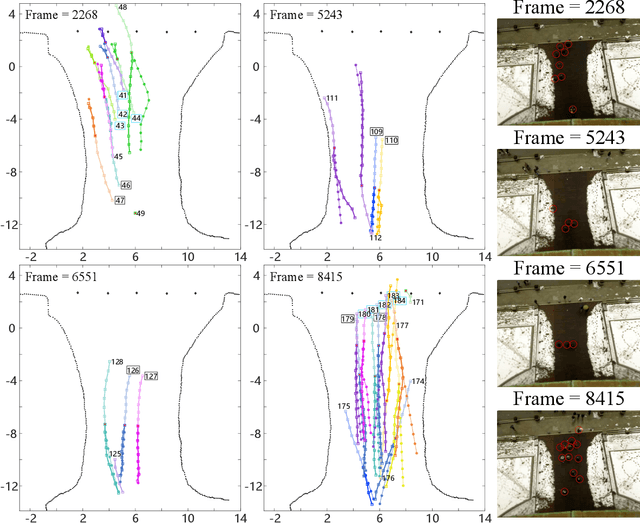
This paper studies the problem of multi-agent trajectory prediction in crowded unknown environments. A novel energy function optimization-based framework is proposed to generate prediction trajectories. Firstly, a new energy function is designed for easier optimization. Secondly, an online optimization pipeline for calculating parameters and agents' velocities is developed. In this pipeline, we first design an efficient group division method based on Frechet distance to classify agents online. Then the strategy on decoupling the optimization of velocities and critical parameters in the energy function is developed, where the the slap swarm algorithm and gradient descent algorithms are integrated to solve the optimization problems more efficiently. Thirdly, we propose a similarity-based resample evaluation algorithm to predict agents' optimal goals, defined as the target-moving headings of agents, which effectively extracts hidden information in observed states and avoids learning agents' destinations via the training dataset in advance. Experiments and comparison studies verify the advantages of the proposed method in terms of prediction accuracy and speed.
Directly Attention Loss Adjusted Prioritized Experience Replay
Nov 24, 2023Prioritized Experience Replay (PER) enables the model to learn more about relatively important samples by artificially changing their accessed frequencies. However, this non-uniform sampling method shifts the state-action distribution that is originally used to estimate Q-value functions, which brings about the estimation deviation. In this article, an novel off policy reinforcement learning training framework called Directly Attention Loss Adjusted Prioritized Experience Replay (DALAP) is proposed, which can directly quantify the changed extent of the shifted distribution through Parallel Self-Attention network, so as to accurately compensate the error. In addition, a Priority-Encouragement mechanism is designed simultaneously to optimize the sample screening criterion, and further improve the training efficiency. In order to verify the effectiveness and generality of DALAP, we integrate it with the value-function based, the policy-gradient based and multi-agent reinforcement learning algorithm, respectively. The multiple groups of comparative experiments show that DALAP has the significant advantages of both improving the convergence rate and reducing the training variance.
QFree: A Universal Value Function Factorization for Multi-Agent Reinforcement Learning
Nov 01, 2023



Centralized training is widely utilized in the field of multi-agent reinforcement learning (MARL) to assure the stability of training process. Once a joint policy is obtained, it is critical to design a value function factorization method to extract optimal decentralized policies for the agents, which needs to satisfy the individual-global-max (IGM) principle. While imposing additional limitations on the IGM function class can help to meet the requirement, it comes at the cost of restricting its application to more complex multi-agent environments. In this paper, we propose QFree, a universal value function factorization method for MARL. We start by developing mathematical equivalent conditions of the IGM principle based on the advantage function, which ensures that the principle holds without any compromise, removing the conservatism of conventional methods. We then establish a more expressive mixing network architecture that can fulfill the equivalent factorization. In particular, the novel loss function is developed by considering the equivalent conditions as regularization term during policy evaluation in the MARL algorithm. Finally, the effectiveness of the proposed method is verified in a nonmonotonic matrix game scenario. Moreover, we show that QFree achieves the state-of-the-art performance in a general-purpose complex MARL benchmark environment, Starcraft Multi-Agent Challenge (SMAC).
Attention Loss Adjusted Prioritized Experience Replay
Sep 13, 2023Prioritized Experience Replay (PER) is a technical means of deep reinforcement learning by selecting experience samples with more knowledge quantity to improve the training rate of neural network. However, the non-uniform sampling used in PER inevitably shifts the state-action space distribution and brings the estimation error of Q-value function. In this paper, an Attention Loss Adjusted Prioritized (ALAP) Experience Replay algorithm is proposed, which integrates the improved Self-Attention network with Double-Sampling mechanism to fit the hyperparameter that can regulate the importance sampling weights to eliminate the estimation error caused by PER. In order to verify the effectiveness and generality of the algorithm, the ALAP is tested with value-function based, policy-gradient based and multi-agent reinforcement learning algorithms in OPENAI gym, and comparison studies verify the advantage and efficiency of the proposed training framework.
Policy Learning for Nonlinear Model Predictive Control with Application to USVs
Nov 18, 2022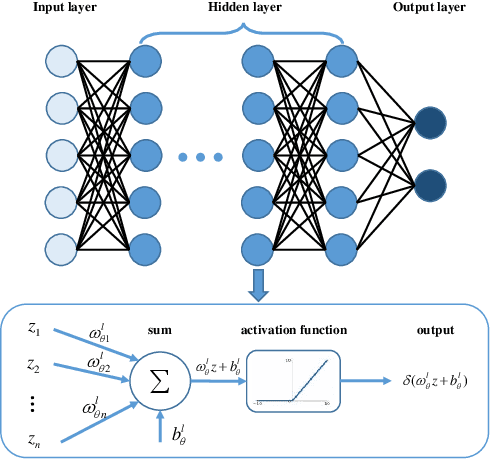
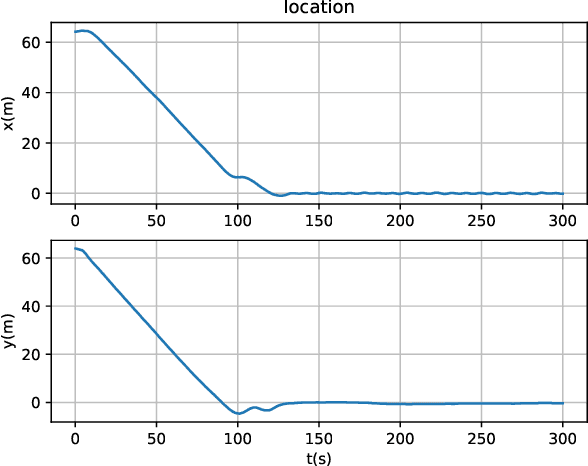
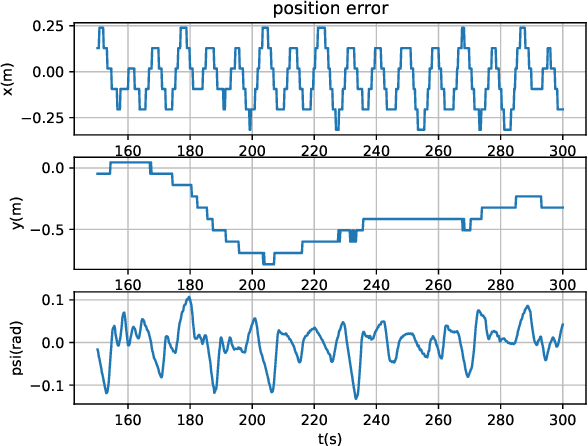
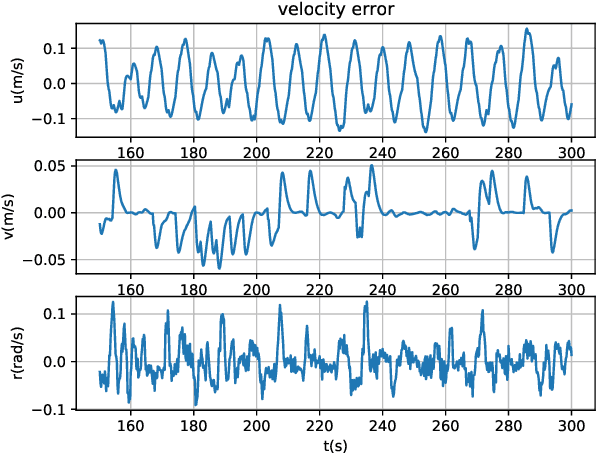
The unaffordable computation load of nonlinear model predictive control (NMPC) has prevented it for being used in robots with high sampling rates for decades. This paper is concerned with the policy learning problem for nonlinear MPC with system constraints, and its applications to unmanned surface vehicles (USVs), where the nonlinear MPC policy is learned offline and deployed online to resolve the computational complexity issue. A deep neural networks (DNN) based policy learning MPC (PL-MPC) method is proposed to avoid solving nonlinear optimal control problems online. The detailed policy learning method is developed and the PL-MPC algorithm is designed. The strategy to ensure the practical feasibility of policy implementation is proposed, and it is theoretically proved that the closed-loop system under the proposed method is asymptotically stable in probability. In addition, we apply the PL-MPC algorithm successfully to the motion control of USVs. It is shown that the proposed algorithm can be implemented at a sampling rate up to $5 Hz$ with high-precision motion control. The experiment video is available via:\url{https://v.youku.com/v_show/id_XNTkwMTM0NzM5Ng==.html