 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContact SLAM: An Active Tactile Exploration Policy Based on Physical Reasoning Utilized in Robotic Fine Blind Manipulation Tasks
Dec 11, 2025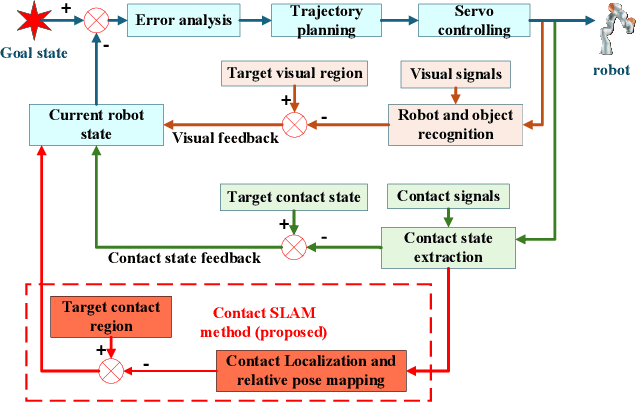
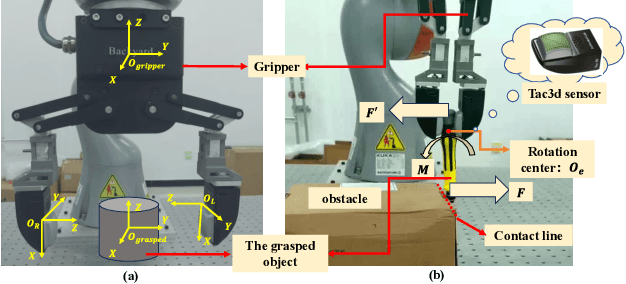
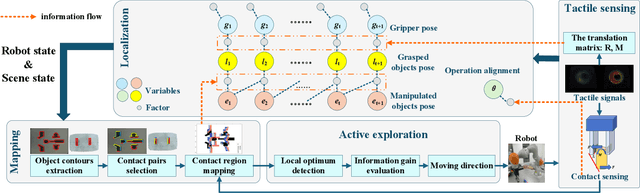
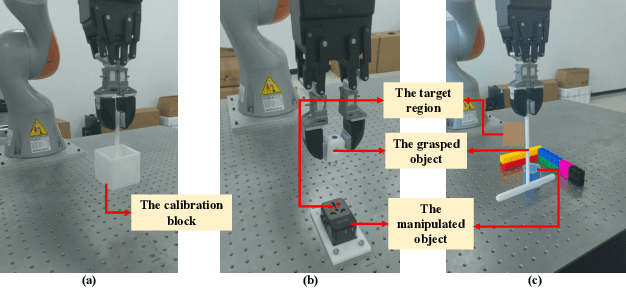
Contact-rich manipulation is difficult for robots to execute and requires accurate perception of the environment. In some scenarios, vision is occluded. The robot can then no longer obtain real-time scene state information through visual feedback. This is called ``blind manipulation". In this manuscript, a novel physically-driven contact cognition method, called ``Contact SLAM", is proposed. It estimates the state of the environment and achieves manipulation using only tactile sensing and prior knowledge of the scene. To maximize exploration efficiency, this manuscript also designs an active exploration policy. The policy gradually reduces uncertainties in the manipulation scene. The experimental results demonstrated the effectiveness and accuracy of the proposed method in several contact-rich tasks, including the difficult and delicate socket assembly task and block-pushing task.
Curiosity-Diffuser: Curiosity Guide Diffusion Models for Reliability
Mar 19, 2025One of the bottlenecks in robotic intelligence is the instability of neural network models, which, unlike control models, lack a well-defined convergence domain and stability. This leads to risks when applying intelligence in the physical world. Specifically, imitation policy based on neural network may generate hallucinations, leading to inaccurate behaviors that impact the safety of real-world applications. To address this issue, this paper proposes the Curiosity-Diffuser, aimed at guiding the conditional diffusion model to generate trajectories with lower curiosity, thereby improving the reliability of policy. The core idea is to use a Random Network Distillation (RND) curiosity module to assess whether the model's behavior aligns with the training data, and then minimize curiosity by classifier guidance diffusion to reduce overgeneralization during inference. Additionally, we propose a computationally efficient metric for evaluating the reliability of the policy, measuring the similarity between the generated behaviors and the training dataset, to facilitate research about reliability learning. Finally, simulation verify the effectiveness and applicability of the proposed method to a variety of scenarios, showing that Curiosity-Diffuser significantly improves task performance and produces behaviors that are more similar to the training data. The code for this work is available at: github.com/CarlDegio/Curiosity-Diffuser
Semantic-Geometric-Physical-Driven Robot Manipulation Skill Transfer via Skill Library and Tactile Representation
Nov 18, 2024



Deploying robots in open-world environments involves complex tasks characterized by long sequences and rich interactions, necessitating efficient transfer of robotic skills across diverse and complex scenarios. To address this challenge, we propose a skill library framework based on knowledge graphs, which endows robots with high-level skill awareness and spatial semantic understanding. The framework hierarchically organizes operational knowledge by constructing a "task graph" and a "scene graph" to represent task and scene semantic information, respectively. We introduce a "state graph" to facilitate interaction between high-level task planning and low-level scene information. Furthermore, we propose a hierarchical transfer framework for operational skills. At the task level, the framework integrates contextual learning and chain-of-thought prompting within a four-stage prompt paradigm, leveraging large language models' (LLMs) reasoning and generalization capabilities to achieve task-level subtask sequence transfer. At the motion level, an adaptive trajectory transfer method is developed using the A* algorithm and the skill library, enabling motion-level adaptive trajectory transfer. At the physical level, we introduce an adaptive contour extraction and posture perception method based on tactile perception. This method dynamically obtains high-precision contour and posture information from visual-tactile texture data and adjusts transferred skills, such as contact positions and postures, to ensure effectiveness in new environments. Experimental results validate the effectiveness of the proposed methods. Project website:https://github.com/MingchaoQi/skill_transfer
Learning from Imperfect Demonstrations through Dynamics Evaluation
Dec 18, 2023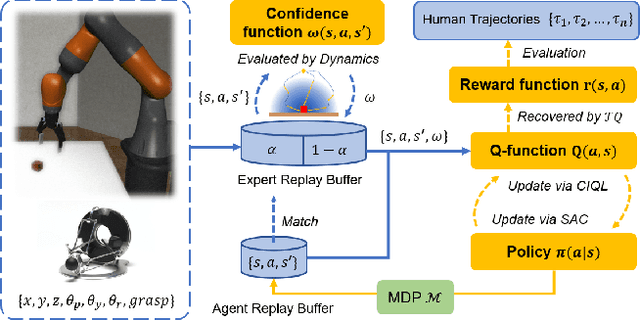
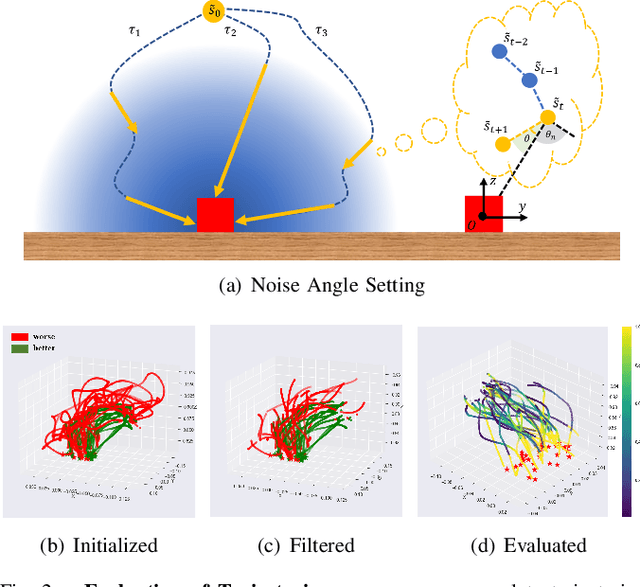

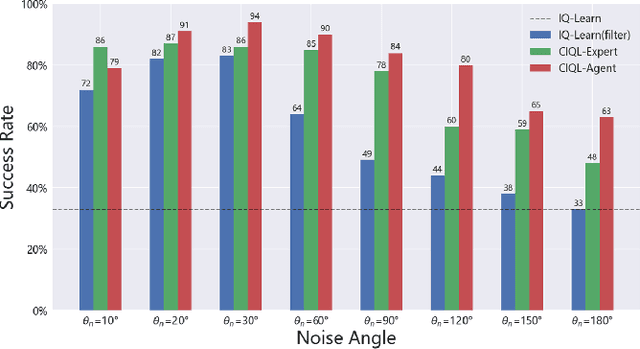
Standard imitation learning usually assumes that demonstrations are drawn from an optimal policy distribution. However, in real-world scenarios, every human demonstration may exhibit nearly random behavior and collecting high-quality human datasets can be quite costly. This requires imitation learning can learn from imperfect demonstrations to obtain robotic policies that align human intent. Prior work uses confidence scores to extract useful information from imperfect demonstrations, which relies on access to ground truth rewards or active human supervision. In this paper, we propose a dynamics-based method to evaluate the data confidence scores without above efforts. We develop a generalized confidence-based imitation learning framework called Confidence-based Inverse soft-Q Learning (CIQL), which can employ different optimal policy matching methods by simply changing object functions. Experimental results show that our confidence evaluation method can increase the success rate by $40.3\%$ over the original algorithm and $13.5\%$ over the simple noise filtering.
Tactile Active Inference Reinforcement Learning for Efficient Robotic Manipulation Skill Acquisition
Nov 19, 2023Robotic manipulation holds the potential to replace humans in the execution of tedious or dangerous tasks. However, control-based approaches are not suitable due to the difficulty of formally describing open-world manipulation in reality, and the inefficiency of existing learning methods. Thus, applying manipulation in a wide range of scenarios presents significant challenges. In this study, we propose a novel method for skill learning in robotic manipulation called Tactile Active Inference Reinforcement Learning (Tactile-AIRL), aimed at achieving efficient training. To enhance the performance of reinforcement learning (RL), we introduce active inference, which integrates model-based techniques and intrinsic curiosity into the RL process. This integration improves the algorithm's training efficiency and adaptability to sparse rewards. Additionally, we utilize a vision-based tactile sensor to provide detailed perception for manipulation tasks. Finally, we employ a model-based approach to imagine and plan appropriate actions through free energy minimization. Simulation results demonstrate that our method achieves significantly high training efficiency in non-prehensile objects pushing tasks. It enables agents to excel in both dense and sparse reward tasks with just a few interaction episodes, surpassing the SAC baseline. Furthermore, we conduct physical experiments on a gripper screwing task using our method, which showcases the algorithm's rapid learning capability and its potential for practical applications.