 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective and Sparse Adversarial Attack on Spiking Neural Networks via Breaking Invisible Surrogate Gradients
Mar 05, 2025Spiking neural networks (SNNs) have shown their competence in handling spatial-temporal event-based data with low energy consumption. Similar to conventional artificial neural networks (ANNs), SNNs are also vulnerable to gradient-based adversarial attacks, wherein gradients are calculated by spatial-temporal back-propagation (STBP) and surrogate gradients (SGs). However, the SGs may be invisible for an inference-only model as they do not influence the inference results, and current gradient-based attacks are ineffective for binary dynamic images captured by the dynamic vision sensor (DVS). While some approaches addressed the issue of invisible SGs through universal SGs, their SGs lack a correlation with the victim model, resulting in sub-optimal performance. Moreover, the imperceptibility of existing SNN-based binary attacks is still insufficient. In this paper, we introduce an innovative potential-dependent surrogate gradient (PDSG) method to establish a robust connection between the SG and the model, thereby enhancing the adaptability of adversarial attacks across various models with invisible SGs. Additionally, we propose the sparse dynamic attack (SDA) to effectively attack binary dynamic images. Utilizing a generation-reduction paradigm, SDA can fully optimize the sparsity of adversarial perturbations. Experimental results demonstrate that our PDSG and SDA outperform state-of-the-art SNN-based attacks across various models and datasets. Specifically, our PDSG achieves 100% attack success rate on ImageNet, and our SDA obtains 82% attack success rate by modifying only 0.24% of the pixels on CIFAR10DVS. The code is available at https://github.com/ryime/PDSG-SDA .
Multimodal Emotion Recognition Model using Physiological Signals
Nov 29, 2019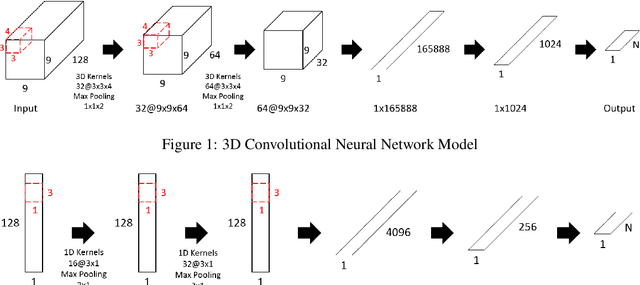
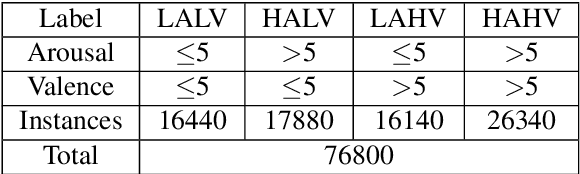
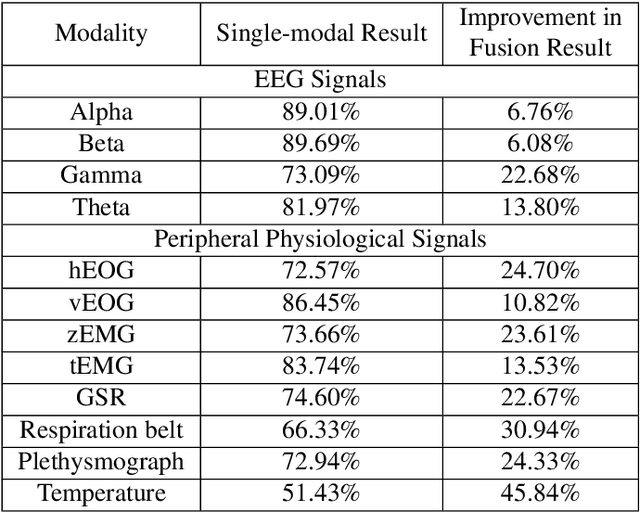

As an important field of research in Human-Machine Interactions, emotion recognition based on physiological signals has become research hotspots. Motivated by the outstanding performance of deep learning approaches in recognition tasks, we proposed a Multimodal Emotion Recognition Model that consists of a 3D convolutional neural network model, a 1D convolutional neural network model and a biologically inspired multimodal fusion model which integrates multimodal information on the decision level for emotion recognition. We use this model to classify four emotional regions from the arousal valence plane, i.e., low arousal and low valence (LALV), high arousal and low valence (HALV), low arousal and high valence (LAHV) and high arousal and high valence (HAHV) in the DEAP and AMIGOS dataset. The 3D CNN model and 1D CNN model are used for emotion recognition based on electroencephalogram (EEG) signals and peripheral physiological signals respectively, and get the accuracy of 93.53% and 95.86% with the original EEG signals in these two datasets. Compared with the single-modal recognition, the multimodal fusion model improves the accuracy of emotion recognition by 5% ~ 25%, and the fusion result of EEG signals (decomposed into four frequency bands) and peripheral physiological signals get the accuracy of 95.77%, 97.27% and 91.07%, 99.74% in these two datasets respectively. Integrated EEG signals and peripheral physiological signals, this model could reach the highest accuracy about 99% in both datasets which shows that our proposed method demonstrates certain advantages in solving the emotion recognition tasks.