 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Distribution-assisted Evolutionary Dynamic Optimization as an Online Calibrator for Complex Social Simulations
Jan 27, 2026The calibration of simulators for complex social systems aims to identify the optimal parameter that drives the output of the simulator best matching the target data observed from the system. As many social systems may change internally over time, calibration naturally becomes an online task, requiring parameters to be updated continuously to maintain the simulator's fidelity. In this work, the online setting is first formulated as a dynamic optimization problem (DOP), requiring the search for a sequence of optimal parameters that fit the simulator to real system changes. However, in contrast to traditional DOP formulations, online calibration explicitly incorporates the observational data as the driver of environmental dynamics. Due to this fundamental difference, existing Evolutionary Dynamic Optimization (EDO) methods, despite being extensively studied for black-box DOPs, are ill-equipped to handle such a scenario. As a result, online calibration problems constitute a new set of challenging DOPs. Here, we propose to explicitly learn the posterior distributions of the parameters and the observational data, thereby facilitating both change detection and environmental adaptation of existing EDOs for this scenario. We thus present a pretrained posterior model for implementation, and fine-tune it during the optimization. Extensive tests on both economic and financial simulators verify that the posterior distribution strongly promotes EDOs in such DOPs widely existed in social science.
Calibrating Agent-Based Financial Markets Simulators with Pretrainable Automatic Posterior Transformation-Based Surrogates
Jan 11, 2026Calibrating Agent-Based Models (ABMs) is an important optimization problem for simulating the complex social systems, where the goal is to identify the optimal parameter of a given ABM by minimizing the discrepancy between the simulated data and the real-world observations. Unfortunately, it suffers from the extensive computational costs of iterative evaluations, which involves the expensive simulation with the candidate parameter. While Surrogate-Assisted Evolutionary Algorithms (SAEAs) have been widely adopted to alleviate the computational burden, existing methods face two key limitations: 1) surrogating the original evaluation function is hard due the nonlinear yet multi-modal nature of the ABMs, and 2) the commonly used surrogates cannot share the optimization experience among multiple calibration tasks, making the batched calibration less effective. To address these issues, this work proposes Automatic posterior transformation with Negatively Correlated Search and Adaptive Trust-Region (ANTR). ANTR first replaces the traditional surrogates with a pretrainable neural density estimator that directly models the posterior distribution of the parameters given observed data, thereby aligning the optimization objective with parameter-space accuracy. Furthermore, we incorporate a diversity-preserving search strategy to prevent premature convergence and an adaptive trust-region method to efficiently allocate computational resources. We take two representative ABM-based financial market simulators as the test bench as due to the high non-linearity. Experiments demonstrate that the proposed ANTR significantly outperforms conventional metaheuristics and state-of-the-art SAEAs in both calibration accuracy and computational efficiency, particularly in batch calibration scenarios across multiple market conditions.
MegaHan97K: A Large-Scale Dataset for Mega-Category Chinese Character Recognition with over 97K Categories
Jun 05, 2025Foundational to the Chinese language and culture, Chinese characters encompass extraordinarily extensive and ever-expanding categories, with the latest Chinese GB18030-2022 standard containing 87,887 categories. The accurate recognition of this vast number of characters, termed mega-category recognition, presents a formidable yet crucial challenge for cultural heritage preservation and digital applications. Despite significant advances in Optical Character Recognition (OCR), mega-category recognition remains unexplored due to the absence of comprehensive datasets, with the largest existing dataset containing merely 16,151 categories. To bridge this critical gap, we introduce MegaHan97K, a mega-category, large-scale dataset covering an unprecedented 97,455 categories of Chinese characters. Our work offers three major contributions: (1) MegaHan97K is the first dataset to fully support the latest GB18030-2022 standard, providing at least six times more categories than existing datasets; (2) It effectively addresses the long-tail distribution problem by providing balanced samples across all categories through its three distinct subsets: handwritten, historical and synthetic subsets; (3) Comprehensive benchmarking experiments reveal new challenges in mega-category scenarios, including increased storage demands, morphologically similar character recognition, and zero-shot learning difficulties, while also unlocking substantial opportunities for future research. To the best of our knowledge, the MetaHan97K is likely the dataset with the largest classes not only in the field of OCR but may also in the broader domain of pattern recognition. The dataset is available at https://github.com/SCUT-DLVCLab/MegaHan97K.
Predicting the Original Appearance of Damaged Historical Documents
Dec 16, 2024



Historical documents encompass a wealth of cultural treasures but suffer from severe damages including character missing, paper damage, and ink erosion over time. However, existing document processing methods primarily focus on binarization, enhancement, etc., neglecting the repair of these damages. To this end, we present a new task, termed Historical Document Repair (HDR), which aims to predict the original appearance of damaged historical documents. To fill the gap in this field, we propose a large-scale dataset HDR28K and a diffusion-based network DiffHDR for historical document repair. Specifically, HDR28K contains 28,552 damaged-repaired image pairs with character-level annotations and multi-style degradations. Moreover, DiffHDR augments the vanilla diffusion framework with semantic and spatial information and a meticulously designed character perceptual loss for contextual and visual coherence. Experimental results demonstrate that the proposed DiffHDR trained using HDR28K significantly surpasses existing approaches and exhibits remarkable performance in handling real damaged documents. Notably, DiffHDR can also be extended to document editing and text block generation, showcasing its high flexibility and generalization capacity. We believe this study could pioneer a new direction of document processing and contribute to the inheritance of invaluable cultures and civilizations. The dataset and code is available at https://github.com/yeungchenwa/HDR.
* Accepted to AAAI 2025; Github Page: https://github.com/yeungchenwa/HDR
HierCode: A Lightweight Hierarchical Codebook for Zero-shot Chinese Text Recognition
Mar 20, 2024

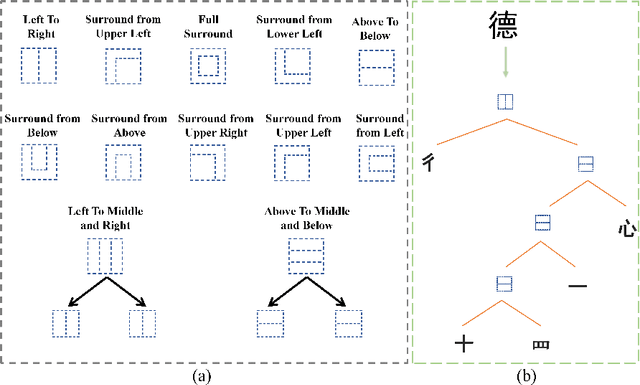

Text recognition, especially for complex scripts like Chinese, faces unique challenges due to its intricate character structures and vast vocabulary. Traditional one-hot encoding methods struggle with the representation of hierarchical radicals, recognition of Out-Of-Vocabulary (OOV) characters, and on-device deployment due to their computational intensity. To address these challenges, we propose HierCode, a novel and lightweight codebook that exploits the innate hierarchical nature of Chinese characters. HierCode employs a multi-hot encoding strategy, leveraging hierarchical binary tree encoding and prototype learning to create distinctive, informative representations for each character. This approach not only facilitates zero-shot recognition of OOV characters by utilizing shared radicals and structures but also excels in line-level recognition tasks by computing similarity with visual features, a notable advantage over existing methods. Extensive experiments across diverse benchmarks, including handwritten, scene, document, web, and ancient text, have showcased HierCode's superiority for both conventional and zero-shot Chinese character or text recognition, exhibiting state-of-the-art performance with significantly fewer parameters and fast inference speed.
FontDiffuser: One-Shot Font Generation via Denoising Diffusion with Multi-Scale Content Aggregation and Style Contrastive Learning
Dec 19, 2023Automatic font generation is an imitation task, which aims to create a font library that mimics the style of reference images while preserving the content from source images. Although existing font generation methods have achieved satisfactory performance, they still struggle with complex characters and large style variations. To address these issues, we propose FontDiffuser, a diffusion-based image-to-image one-shot font generation method, which innovatively models the font imitation task as a noise-to-denoise paradigm. In our method, we introduce a Multi-scale Content Aggregation (MCA) block, which effectively combines global and local content cues across different scales, leading to enhanced preservation of intricate strokes of complex characters. Moreover, to better manage the large variations in style transfer, we propose a Style Contrastive Refinement (SCR) module, which is a novel structure for style representation learning. It utilizes a style extractor to disentangle styles from images, subsequently supervising the diffusion model via a meticulously designed style contrastive loss. Extensive experiments demonstrate FontDiffuser's state-of-the-art performance in generating diverse characters and styles. It consistently excels on complex characters and large style changes compared to previous methods. The code is available at https://github.com/yeungchenwa/FontDiffuser.
* Accepted to AAAI 2024; Github Page: https://github.com/yeungchenwa/FontDiffuser
UPOCR: Towards Unified Pixel-Level OCR Interface
Dec 05, 2023In recent years, the optical character recognition (OCR) field has been proliferating with plentiful cutting-edge approaches for a wide spectrum of tasks. However, these approaches are task-specifically designed with divergent paradigms, architectures, and training strategies, which significantly increases the complexity of research and maintenance and hinders the fast deployment in applications. To this end, we propose UPOCR, a simple-yet-effective generalist model for Unified Pixel-level OCR interface. Specifically, the UPOCR unifies the paradigm of diverse OCR tasks as image-to-image transformation and the architecture as a vision Transformer (ViT)-based encoder-decoder. Learnable task prompts are introduced to push the general feature representations extracted by the encoder toward task-specific spaces, endowing the decoder with task awareness. Moreover, the model training is uniformly aimed at minimizing the discrepancy between the generated and ground-truth images regardless of the inhomogeneity among tasks. Experiments are conducted on three pixel-level OCR tasks including text removal, text segmentation, and tampered text detection. Without bells and whistles, the experimental results showcase that the proposed method can simultaneously achieve state-of-the-art performance on three tasks with a unified single model, which provides valuable strategies and insights for future research on generalist OCR models. Code will be publicly available.