 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierCode: A Lightweight Hierarchical Codebook for Zero-shot Chinese Text Recognition
Paper and Code
Mar 20, 2024

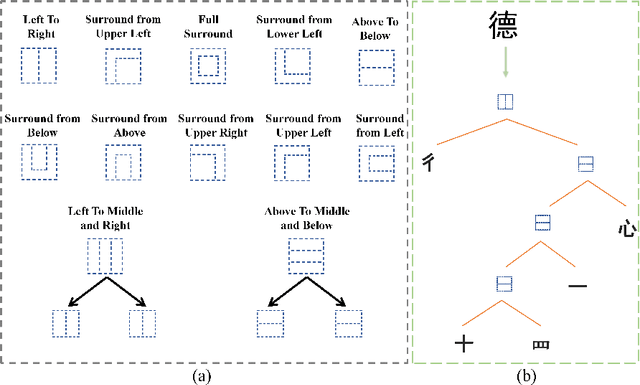

Text recognition, especially for complex scripts like Chinese, faces unique challenges due to its intricate character structures and vast vocabulary. Traditional one-hot encoding methods struggle with the representation of hierarchical radicals, recognition of Out-Of-Vocabulary (OOV) characters, and on-device deployment due to their computational intensity. To address these challenges, we propose HierCode, a novel and lightweight codebook that exploits the innate hierarchical nature of Chinese characters. HierCode employs a multi-hot encoding strategy, leveraging hierarchical binary tree encoding and prototype learning to create distinctive, informative representations for each character. This approach not only facilitates zero-shot recognition of OOV characters by utilizing shared radicals and structures but also excels in line-level recognition tasks by computing similarity with visual features, a notable advantage over existing methods. Extensive experiments across diverse benchmarks, including handwritten, scene, document, web, and ancient text, have showcased HierCode's superiority for both conventional and zero-shot Chinese character or text recognition, exhibiting state-of-the-art performance with significantly fewer parameters and fast inference speed.