 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence-Based Opportunistic Coronary Calcium Screening in the Veterans Affairs National Healthcare System
Sep 16, 2024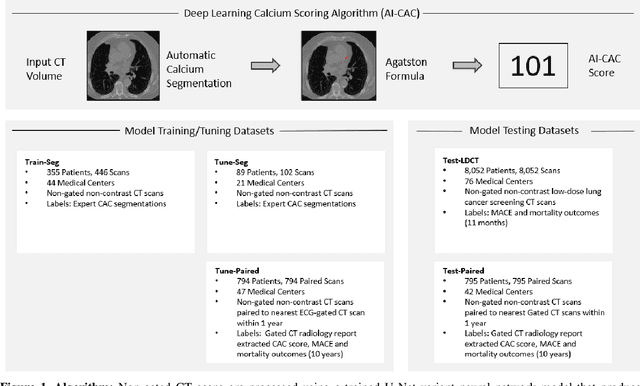
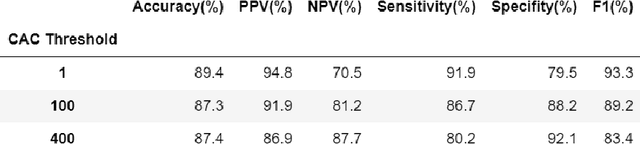
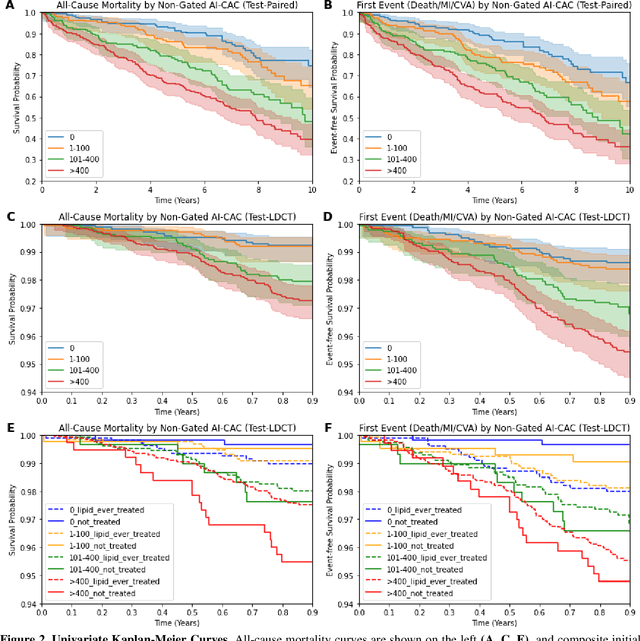
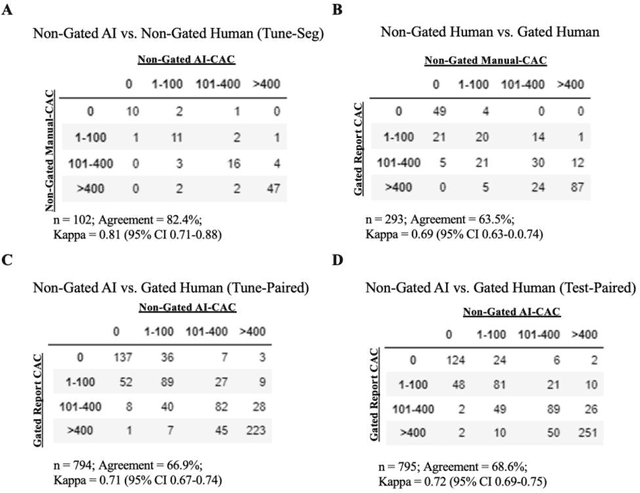
Coronary artery calcium (CAC) is highly predictive of cardiovascular events. While millions of chest CT scans are performed annually in the United States, CAC is not routinely quantified from scans done for non-cardiac purposes. A deep learning algorithm was developed using 446 expert segmentations to automatically quantify CAC on non-contrast, non-gated CT scans (AI-CAC). Our study differs from prior works as we leverage imaging data across the Veterans Affairs national healthcare system, from 98 medical centers, capturing extensive heterogeneity in imaging protocols, scanners, and patients. AI-CAC performance on non-gated scans was compared against clinical standard ECG-gated CAC scoring. Non-gated AI-CAC differentiated zero vs. non-zero and less than 100 vs. 100 or greater Agatston scores with accuracies of 89.4% (F1 0.93) and 87.3% (F1 0.89), respectively, in 795 patients with paired gated scans within a year of a non-gated CT scan. Non-gated AI-CAC was predictive of 10-year all-cause mortality (CAC 0 vs. >400 group: 25.4% vs. 60.2%, Cox HR 3.49, p < 0.005), and composite first-time stroke, MI, or death (CAC 0 vs. >400 group: 33.5% vs. 63.8%, Cox HR 3.00, p < 0.005). In a screening dataset of 8,052 patients with low-dose lung cancer-screening CTs (LDCT), 3,091/8,052 (38.4%) individuals had AI-CAC >400. Four cardiologists qualitatively reviewed LDCT images from a random sample of >400 AI-CAC patients and verified that 527/531 (99.2%) would benefit from lipid-lowering therapy. To the best of our knowledge, this is the first non-gated CT CAC algorithm developed across a national healthcare system, on multiple imaging protocols, without filtering intra-cardiac hardware, and compared against a strong gated CT reference. We report superior performance relative to previous CAC algorithms evaluated against paired gated scans that included patients with intra-cardiac hardware.
MedEval: A Multi-Level, Multi-Task, and Multi-Domain Medical Benchmark for Language Model Evaluation
Oct 27, 2023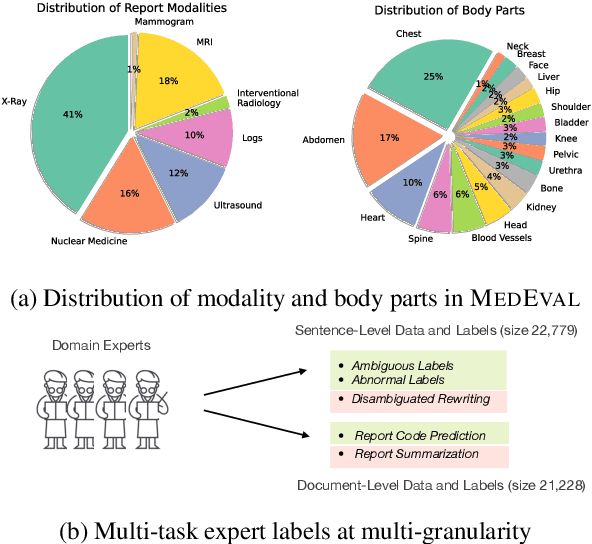
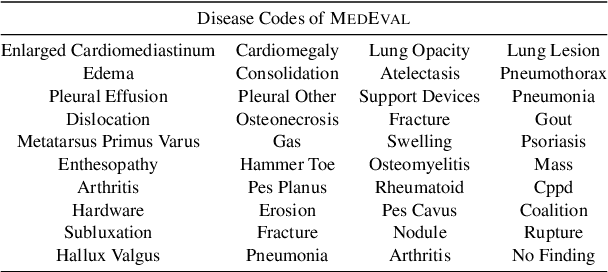
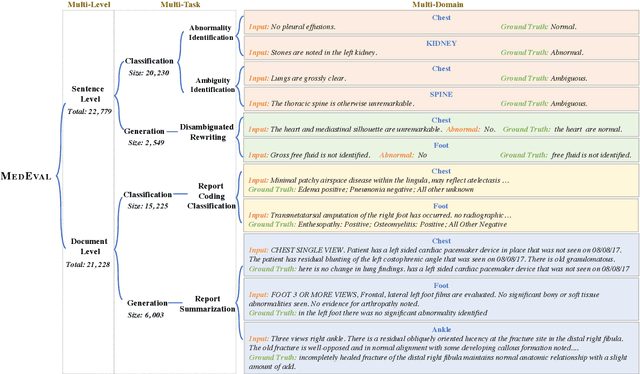
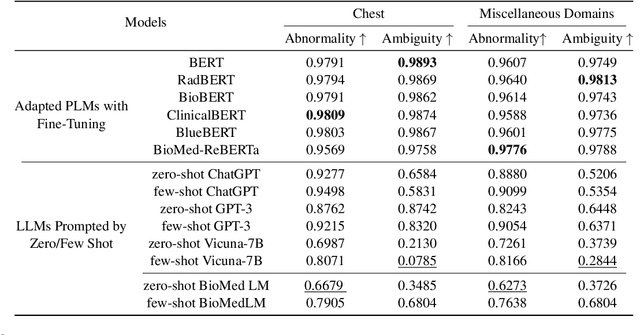
Curated datasets for healthcare are often limited due to the need of human annotations from experts. In this paper, we present MedEval, a multi-level, multi-task, and multi-domain medical benchmark to facilitate the development of language models for healthcare. MedEval is comprehensive and consists of data from several healthcare systems and spans 35 human body regions from 8 examination modalities. With 22,779 collected sentences and 21,228 reports, we provide expert annotations at multiple levels, offering a granular potential usage of the data and supporting a wide range of tasks. Moreover, we systematically evaluated 10 generic and domain-specific language models under zero-shot and finetuning settings, from domain-adapted baselines in healthcare to general-purposed state-of-the-art large language models (e.g., ChatGPT). Our evaluations reveal varying effectiveness of the two categories of language models across different tasks, from which we notice the importance of instruction tuning for few-shot usage of large language models. Our investigation paves the way toward benchmarking language models for healthcare and provides valuable insights into the strengths and limitations of adopting large language models in medical domains, informing their practical applications and future advancements.
Robust and Interpretable Medical Image Classifiers via Concept Bottleneck Models
Oct 04, 2023



Medical image classification is a critical problem for healthcare, with the potential to alleviate the workload of doctors and facilitate diagnoses of patients. However, two challenges arise when deploying deep learning models to real-world healthcare applications. First, neural models tend to learn spurious correlations instead of desired features, which could fall short when generalizing to new domains (e.g., patients with different ages). Second, these black-box models lack interpretability. When making diagnostic predictions, it is important to understand why a model makes a decision for trustworthy and safety considerations. In this paper, to address these two limitations, we propose a new paradigm to build robust and interpretable medical image classifiers with natural language concepts. Specifically, we first query clinical concepts from GPT-4, then transform latent image features into explicit concepts with a vision-language model. We systematically evaluate our method on eight medical image classification datasets to verify its effectiveness. On challenging datasets with strong confounding factors, our method can mitigate spurious correlations thus substantially outperform standard visual encoders and other baselines. Finally, we show how classification with a small number of concepts brings a level of interpretability for understanding model decisions through case studies in real medical data.
"Nothing Abnormal": Disambiguating Medical Reports via Contrastive Knowledge Infusion
May 15, 2023Sharing medical reports is essential for patient-centered care. A recent line of work has focused on automatically generating reports with NLP methods. However, different audiences have different purposes when writing/reading medical reports -- for example, healthcare professionals care more about pathology, whereas patients are more concerned with the diagnosis ("Is there any abnormality?"). The expectation gap results in a common situation where patients find their medical reports to be ambiguous and therefore unsure about the next steps. In this work, we explore the audience expectation gap in healthcare and summarize common ambiguities that lead patients to be confused about their diagnosis into three categories: medical jargon, contradictory findings, and misleading grammatical errors. Based on our analysis, we define a disambiguation rewriting task to regenerate an input to be unambiguous while preserving information about the original content. We further propose a rewriting algorithm based on contrastive pretraining and perturbation-based rewriting. In addition, we create two datasets, OpenI-Annotated based on chest reports and VA-Annotated based on general medical reports, with available binary labels for ambiguity and abnormality presence annotated by radiology specialists. Experimental results on these datasets show that our proposed algorithm effectively rewrites input sentences in a less ambiguous way with high content fidelity. Our code and annotated data are released to facilitate future research.
Weakly Supervised Contrastive Learning for Chest X-Ray Report Generation
Sep 25, 2021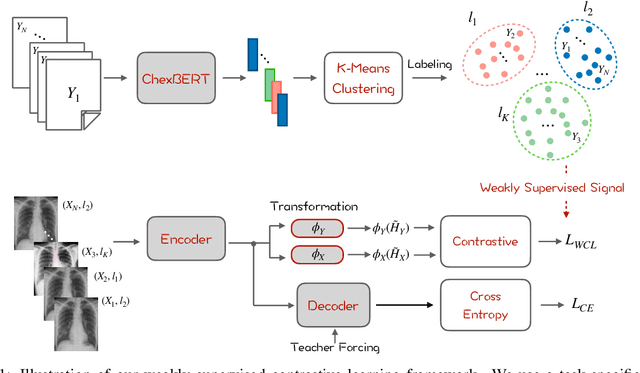
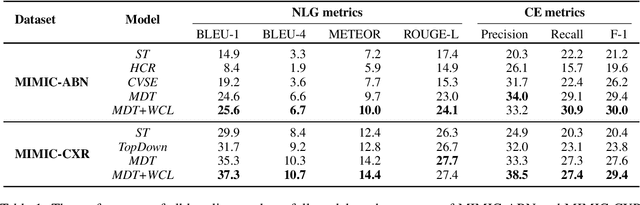
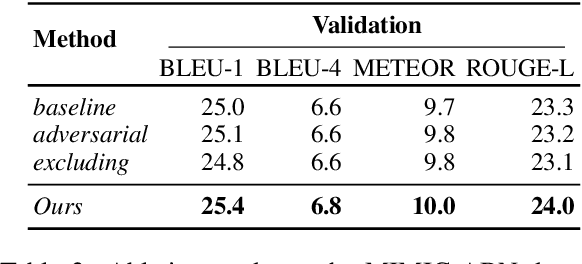
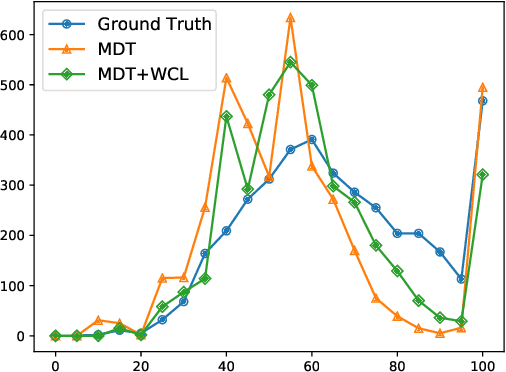
Radiology report generation aims at generating descriptive text from radiology images automatically, which may present an opportunity to improve radiology reporting and interpretation. A typical setting consists of training encoder-decoder models on image-report pairs with a cross entropy loss, which struggles to generate informative sentences for clinical diagnoses since normal findings dominate the datasets. To tackle this challenge and encourage more clinically-accurate text outputs, we propose a novel weakly supervised contrastive loss for medical report generation. Experimental results demonstrate that our method benefits from contrasting target reports with incorrect but semantically-close ones. It outperforms previous work on both clinical correctness and text generation metrics for two public benchmarks.
Learning Visual-Semantic Embeddings for Reporting Abnormal Findings on Chest X-rays
Oct 06, 2020
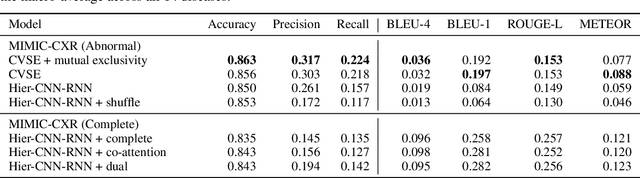
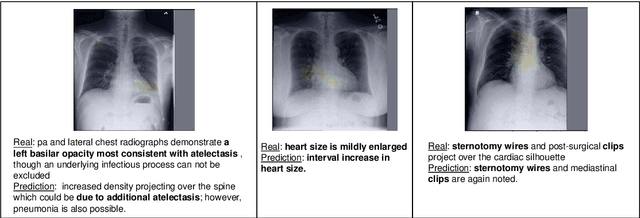
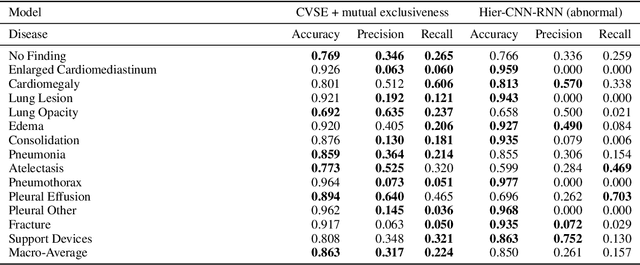
Automatic medical image report generation has drawn growing attention due to its potential to alleviate radiologists' workload. Existing work on report generation often trains encoder-decoder networks to generate complete reports. However, such models are affected by data bias (e.g.~label imbalance) and face common issues inherent in text generation models (e.g.~repetition). In this work, we focus on reporting abnormal findings on radiology images; instead of training on complete radiology reports, we propose a method to identify abnormal findings from the reports in addition to grouping them with unsupervised clustering and minimal rules. We formulate the task as cross-modal retrieval and propose Conditional Visual-Semantic Embeddings to align images and fine-grained abnormal findings in a joint embedding space. We demonstrate that our method is able to retrieve abnormal findings and outperforms existing generation models on both clinical correctness and text generation metrics.