 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Robots in a JIF: Joint Inverse and Forward Dynamics with Human and Robot Demonstrations
Mar 15, 2025Pre-training on large datasets of robot demonstrations is a powerful technique for learning diverse manipulation skills but is often limited by the high cost and complexity of collecting robot-centric data, especially for tasks requiring tactile feedback. This work addresses these challenges by introducing a novel method for pre-training with multi-modal human demonstrations. Our approach jointly learns inverse and forward dynamics to extract latent state representations, towards learning manipulation specific representations. This enables efficient fine-tuning with only a small number of robot demonstrations, significantly improving data efficiency. Furthermore, our method allows for the use of multi-modal data, such as combination of vision and touch for manipulation. By leveraging latent dynamics modeling and tactile sensing, this approach paves the way for scalable robot manipulation learning based on human demonstrations.
QuickDraw: Fast Visualization, Analysis and Active Learning for Medical Image Segmentation
Mar 12, 2025



Analyzing CT scans, MRIs and X-rays is pivotal in diagnosing and treating diseases. However, detecting and identifying abnormalities from such medical images is a time-intensive process that requires expert analysis and is prone to interobserver variability. To mitigate such issues, machine learning-based models have been introduced to automate and significantly reduce the cost of image segmentation. Despite significant advances in medical image analysis in recent years, many of the latest models are never applied in clinical settings because state-of-the-art models do not easily interface with existing medical image viewers. To address these limitations, we propose QuickDraw, an open-source framework for medical image visualization and analysis that allows users to upload DICOM images and run off-the-shelf models to generate 3D segmentation masks. In addition, our tool allows users to edit, export, and evaluate segmentation masks to iteratively improve state-of-the-art models through active learning. In this paper, we detail the design of our tool and present survey results that highlight the usability of our software. Notably, we find that QuickDraw reduces the time to manually segment a CT scan from four hours to six minutes and reduces machine learning-assisted segmentation time by 10\% compared to prior work. Our code and documentation are available at https://github.com/qd-seg/quickdraw
SDPT: Synchronous Dual Prompt Tuning for Fusion-based Visual-Language Pre-trained Models
Jul 16, 2024
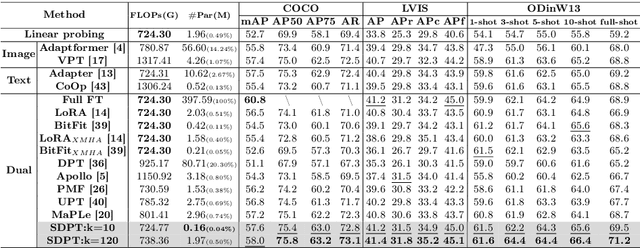
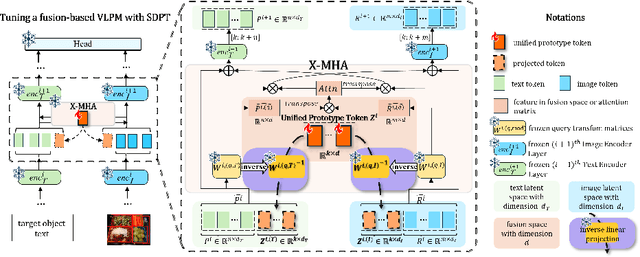

Prompt tuning methods have achieved remarkable success in parameter-efficient fine-tuning on large pre-trained models. However, their application to dual-modal fusion-based visual-language pre-trained models (VLPMs), such as GLIP, has encountered issues. Existing prompt tuning methods have not effectively addressed the modal mapping and aligning problem for tokens in different modalities, leading to poor transfer generalization. To address this issue, we propose Synchronous Dual Prompt Tuning (SDPT). SDPT initializes a single set of learnable unified prototype tokens in the established modal aligning space to represent the aligned semantics of text and image modalities for downstream tasks. Furthermore, SDPT establishes inverse linear projections that require no training to embed the information of unified prototype tokens into the input space of different modalities. The inverse linear projections allow the unified prototype token to synchronously represent the two modalities and enable SDPT to share the unified semantics of text and image for downstream tasks across different modal prompts. Experimental results demonstrate that SDPT assists fusion-based VLPMs to achieve superior outcomes with only 0.04\% of model parameters for training across various scenarios, outperforming other single- or dual-modal methods. The code will be released at https://github.com/wuyongjianCODE/SDPT.
KU-DMIS-MSRA at RadSum23: Pre-trained Vision-Language Model for Radiology Report Summarization
Jul 10, 2023In this paper, we introduce CheXOFA, a new pre-trained vision-language model (VLM) for the chest X-ray domain. Our model is initially pre-trained on various multimodal datasets within the general domain before being transferred to the chest X-ray domain. Following a prominent VLM, we unify various domain-specific tasks into a simple sequence-to-sequence schema. It enables the model to effectively learn the required knowledge and skills from limited resources in the domain. Demonstrating superior performance on the benchmark datasets provided by the BioNLP shared task, our model benefits from its training across multiple tasks and domains. With subtle techniques including ensemble and factual calibration, our system achieves first place on the RadSum23 leaderboard for the hidden test set.
Weakly Supervised Contrastive Learning for Chest X-Ray Report Generation
Sep 25, 2021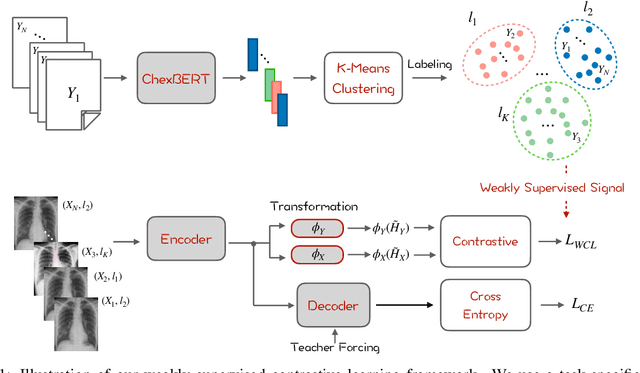
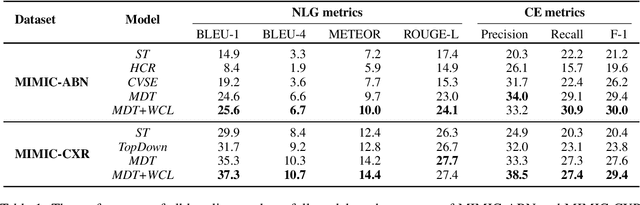
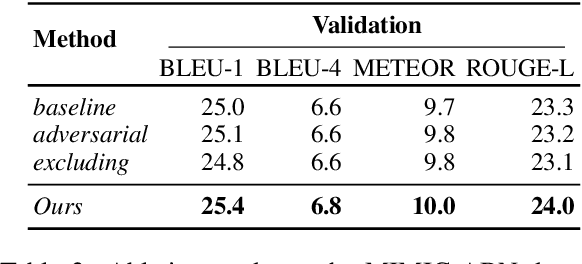
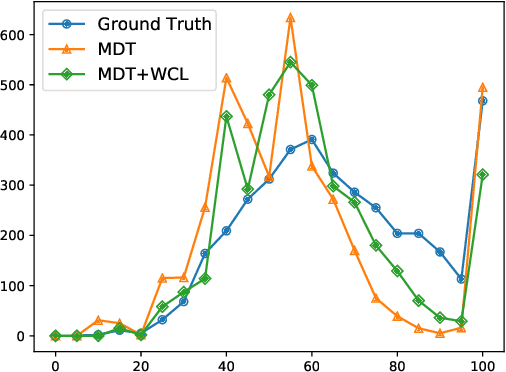
Radiology report generation aims at generating descriptive text from radiology images automatically, which may present an opportunity to improve radiology reporting and interpretation. A typical setting consists of training encoder-decoder models on image-report pairs with a cross entropy loss, which struggles to generate informative sentences for clinical diagnoses since normal findings dominate the datasets. To tackle this challenge and encourage more clinically-accurate text outputs, we propose a novel weakly supervised contrastive loss for medical report generation. Experimental results demonstrate that our method benefits from contrasting target reports with incorrect but semantically-close ones. It outperforms previous work on both clinical correctness and text generation metrics for two public benchmarks.