 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttriPrompter: Auto-Prompting with Attribute Semantics for Zero-shot Nuclei Detection via Visual-Language Pre-trained Models
Oct 22, 2024



Large-scale visual-language pre-trained models (VLPMs) have demonstrated exceptional performance in downstream object detection through text prompts for natural scenes. However, their application to zero-shot nuclei detection on histopathology images remains relatively unexplored, mainly due to the significant gap between the characteristics of medical images and the web-originated text-image pairs used for pre-training. This paper aims to investigate the potential of the object-level VLPM, Grounded Language-Image Pre-training (GLIP), for zero-shot nuclei detection. Specifically, we propose an innovative auto-prompting pipeline, named AttriPrompter, comprising attribute generation, attribute augmentation, and relevance sorting, to avoid subjective manual prompt design. AttriPrompter utilizes VLPMs' text-to-image alignment to create semantically rich text prompts, which are then fed into GLIP for initial zero-shot nuclei detection. Additionally, we propose a self-trained knowledge distillation framework, where GLIP serves as the teacher with its initial predictions used as pseudo labels, to address the challenges posed by high nuclei density, including missed detections, false positives, and overlapping instances. Our method exhibits remarkable performance in label-free nuclei detection, outperforming all existing unsupervised methods and demonstrating excellent generality. Notably, this work highlights the astonishing potential of VLPMs pre-trained on natural image-text pairs for downstream tasks in the medical field as well. Code will be released at https://github.com/wuyongjianCODE/AttriPrompter.
SDPT: Synchronous Dual Prompt Tuning for Fusion-based Visual-Language Pre-trained Models
Jul 16, 2024
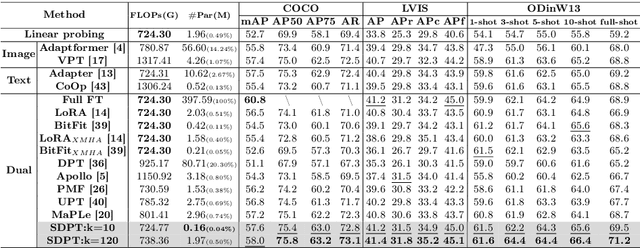
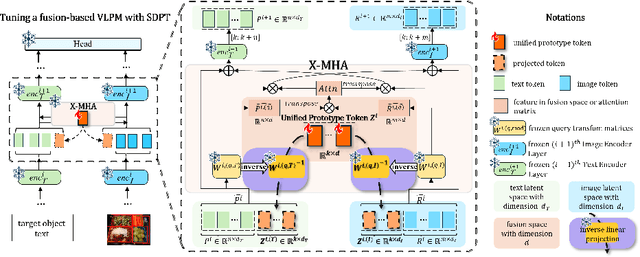

Prompt tuning methods have achieved remarkable success in parameter-efficient fine-tuning on large pre-trained models. However, their application to dual-modal fusion-based visual-language pre-trained models (VLPMs), such as GLIP, has encountered issues. Existing prompt tuning methods have not effectively addressed the modal mapping and aligning problem for tokens in different modalities, leading to poor transfer generalization. To address this issue, we propose Synchronous Dual Prompt Tuning (SDPT). SDPT initializes a single set of learnable unified prototype tokens in the established modal aligning space to represent the aligned semantics of text and image modalities for downstream tasks. Furthermore, SDPT establishes inverse linear projections that require no training to embed the information of unified prototype tokens into the input space of different modalities. The inverse linear projections allow the unified prototype token to synchronously represent the two modalities and enable SDPT to share the unified semantics of text and image for downstream tasks across different modal prompts. Experimental results demonstrate that SDPT assists fusion-based VLPMs to achieve superior outcomes with only 0.04\% of model parameters for training across various scenarios, outperforming other single- or dual-modal methods. The code will be released at https://github.com/wuyongjianCODE/SDPT.
Zero-shot Nuclei Detection via Visual-Language Pre-trained Models
Jun 30, 2023



Large-scale visual-language pre-trained models (VLPM) have proven their excellent performance in downstream object detection for natural scenes. However, zero-shot nuclei detection on H\&E images via VLPMs remains underexplored. The large gap between medical images and the web-originated text-image pairs used for pre-training makes it a challenging task. In this paper, we attempt to explore the potential of the object-level VLPM, Grounded Language-Image Pre-training (GLIP) model, for zero-shot nuclei detection. Concretely, an automatic prompts design pipeline is devised based on the association binding trait of VLPM and the image-to-text VLPM BLIP, avoiding empirical manual prompts engineering. We further establish a self-training framework, using the automatically designed prompts to generate the preliminary results as pseudo labels from GLIP and refine the predicted boxes in an iterative manner. Our method achieves a remarkable performance for label-free nuclei detection, surpassing other comparison methods. Foremost, our work demonstrates that the VLPM pre-trained on natural image-text pairs exhibits astonishing potential for downstream tasks in the medical field as well. Code will be released at https://github.com/wuyongjianCODE/VLPMNuD.