 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDPT: Synchronous Dual Prompt Tuning for Fusion-based Visual-Language Pre-trained Models
Paper and Code

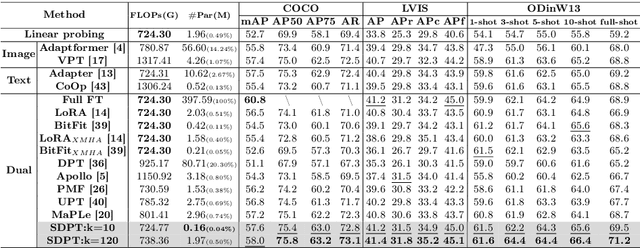
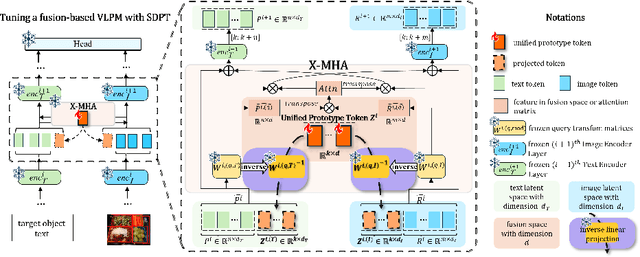

Prompt tuning methods have achieved remarkable success in parameter-efficient fine-tuning on large pre-trained models. However, their application to dual-modal fusion-based visual-language pre-trained models (VLPMs), such as GLIP, has encountered issues. Existing prompt tuning methods have not effectively addressed the modal mapping and aligning problem for tokens in different modalities, leading to poor transfer generalization. To address this issue, we propose Synchronous Dual Prompt Tuning (SDPT). SDPT initializes a single set of learnable unified prototype tokens in the established modal aligning space to represent the aligned semantics of text and image modalities for downstream tasks. Furthermore, SDPT establishes inverse linear projections that require no training to embed the information of unified prototype tokens into the input space of different modalities. The inverse linear projections allow the unified prototype token to synchronously represent the two modalities and enable SDPT to share the unified semantics of text and image for downstream tasks across different modal prompts. Experimental results demonstrate that SDPT assists fusion-based VLPMs to achieve superior outcomes with only 0.04\% of model parameters for training across various scenarios, outperforming other single- or dual-modal methods. The code will be released at https://github.com/wuyongjianCODE/SDPT.