 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Video Object Segmentation
Paper and Code

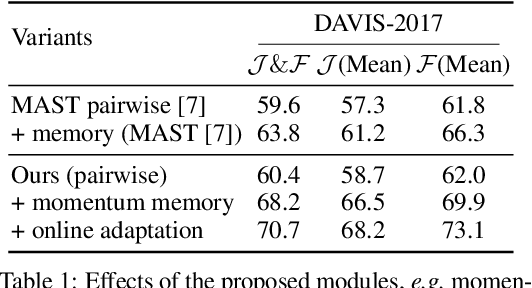
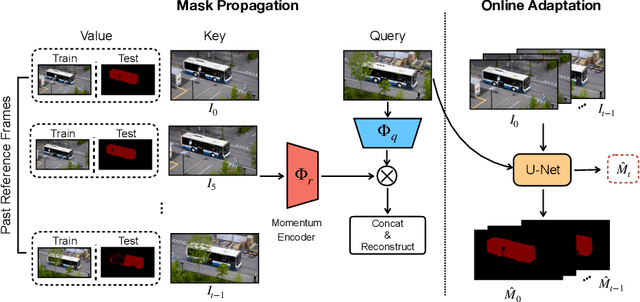

The objective of this paper is self-supervised representation learning, with the goal of solving semi-supervised video object segmentation (a.k.a. dense tracking). We make the following contributions: (i) we propose to improve the existing self-supervised approach, with a simple, yet more effective memory mechanism for long-term correspondence matching, which resolves the challenge caused by the dis-appearance and reappearance of objects; (ii) by augmenting the self-supervised approach with an online adaptation module, our method successfully alleviates tracker drifts caused by spatial-temporal discontinuity, e.g. occlusions or dis-occlusions, fast motions; (iii) we explore the efficiency of self-supervised representation learning for dense tracking, surprisingly, we show that a powerful tracking model can be trained with as few as 100 raw video clips (equivalent to a duration of 11mins), indicating that low-level statistics have already been effective for tracking tasks; (iv) we demonstrate state-of-the-art results among the self-supervised approaches on DAVIS-2017 and YouTube-VOS, as well as surpassing most of methods trained with millions of manual segmentation annotations, further bridging the gap between self-supervised and supervised learning. Codes are released to foster any further research (https://github.com/fangruizhu/self_sup_semiVOS).