 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLMs on Chinese Idiom Translation
Aug 14, 2025Idioms, whose figurative meanings usually differ from their literal interpretations, are common in everyday language, especially in Chinese, where they often contain historical references and follow specific structural patterns. Despite recent progress in machine translation with large language models, little is known about Chinese idiom translation. In this work, we introduce IdiomEval, a framework with a comprehensive error taxonomy for Chinese idiom translation. We annotate 900 translation pairs from nine modern systems, including GPT-4o and Google Translate, across four domains: web, news, Wikipedia, and social media. We find these systems fail at idiom translation, producing incorrect, literal, partial, or even missing translations. The best-performing system, GPT-4, makes errors in 28% of cases. We also find that existing evaluation metrics measure idiom quality poorly with Pearson correlation below 0.48 with human ratings. We thus develop improved models that achieve F$_1$ scores of 0.68 for detecting idiom translation errors.
ST-DPGAN: A Privacy-preserving Framework for Spatiotemporal Data Generation
Jun 04, 2024



Spatiotemporal data is prevalent in a wide range of edge devices, such as those used in personal communication and financial transactions. Recent advancements have sparked a growing interest in integrating spatiotemporal analysis with large-scale language models. However, spatiotemporal data often contains sensitive information, making it unsuitable for open third-party access. To address this challenge, we propose a Graph-GAN-based model for generating privacy-protected spatiotemporal data. Our approach incorporates spatial and temporal attention blocks in the discriminator and a spatiotemporal deconvolution structure in the generator. These enhancements enable efficient training under Gaussian noise to achieve differential privacy. Extensive experiments conducted on three real-world spatiotemporal datasets validate the efficacy of our model. Our method provides a privacy guarantee while maintaining the data utility. The prediction model trained on our generated data maintains a competitive performance compared to the model trained on the original data.
BLIAM: Literature-based Data Synthesis for Synergistic Drug Combination Prediction
Feb 16, 2023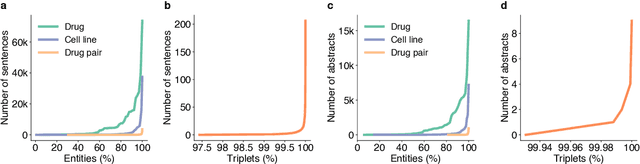
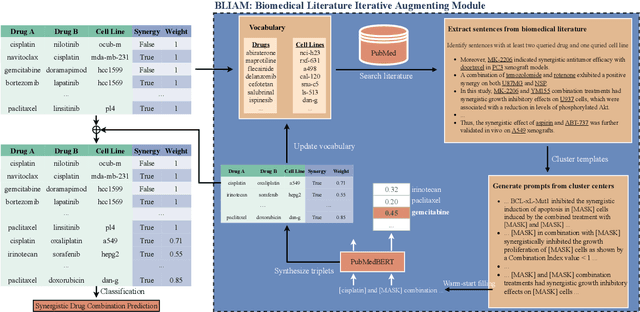
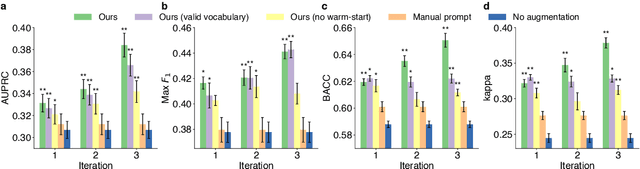
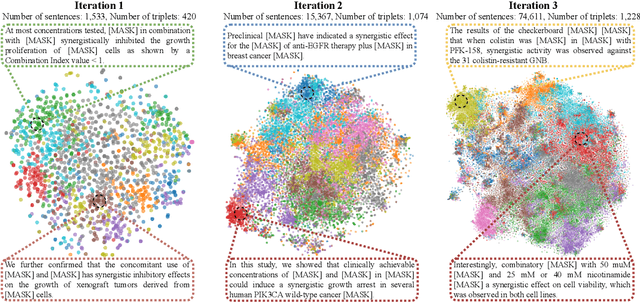
Language models pre-trained on scientific literature corpora have substantially advanced scientific discovery by offering high-quality feature representations for downstream applications. However, these features are often not interpretable, and thus can reveal limited insights to domain experts. Instead of obtaining features from language models, we propose BLIAM, a literature-based data synthesis approach to directly generate training data points that are interpretable and model-agnostic to downstream applications. The key idea of BLIAM is to create prompts using existing training data and then use these prompts to synthesize new data points. BLIAM performs these two steps iteratively as new data points will define more informative prompts and new prompts will in turn synthesize more accurate data points. Notably, literature-based data augmentation might introduce data leakage since labels of test data points in downstream applications might have already been mentioned in the language model corpus. To prevent such leakage, we introduce GDSC-combo, a large-scale drug combination discovery dataset that was published after the biomedical language model was trained. We found that BLIAM substantially outperforms a non-augmented approach and manual prompting in this rigorous data split setting. BLIAM can be further used to synthesize data points for novel drugs and cell lines that were not even measured in biomedical experiments. In addition to the promising prediction performance, the data points synthesized by BLIAM are interpretable and model-agnostic, enabling in silico augmentation for in vitro experiments.