 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPLAIN: Augmenting CybersecurityWarnings with Reasons and Data
Nov 19, 2023Effective cyber threat recognition and prevention demand comprehensible forecasting systems, as prior approaches commonly offer limited and, ultimately, unconvincing information. We introduce Simplified Plaintext Language (SPLAIN), a natural language generator that converts warning data into user-friendly cyber threat explanations. SPLAIN is designed to generate clear, actionable outputs, incorporating hierarchically organized explanatory details about input data and system functionality. Given the inputs of individual sensor-induced forecasting signals and an overall warning from a fusion module, SPLAIN queries each signal for information on contributing sensors and data signals. This collected data is processed into a coherent English explanation, encompassing forecasting, sensing, and data elements for user review. SPLAIN's template-based approach ensures consistent warning structure and vocabulary. SPLAIN's hierarchical output structure allows each threat and its components to be expanded to reveal underlying explanations on demand. Our conclusions emphasize the need for designers to specify the "how" and "why" behind cyber warnings, advocate for simple structured templates in generating consistent explanations, and recognize that direct causal links in Machine Learning approaches may not always be identifiable, requiring some explanations to focus on general methodologies, such as model and training data.
* Presented at FLAIRS-2019 as poster (see ancillary files)
Human-Computer Conversation
Jun 25, 1999
The article surveys a little of the history of the technology, sets out the main current theoretical approaches in brief, and discusses the on-going opposition between theoretical and empirical approaches. It illustrates the situation with some discussion of CONVERSE, a system that won the Loebner prize in 1997 and which displays features of both approaches.
An ascription-based approach to speech acts
Apr 15, 1999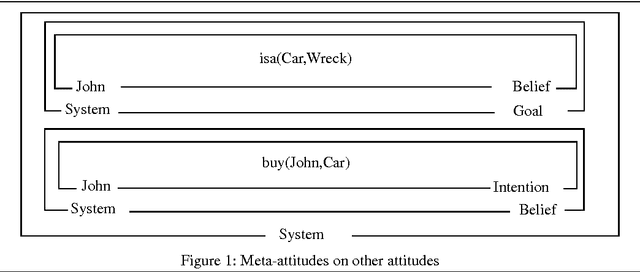


The two principal areas of natural language processing research in pragmatics are belief modelling and speech act processing. Belief modelling is the development of techniques to represent the mental attitudes of a dialogue participant. The latter approach, speech act processing, based on speech act theory, involves viewing dialogue in planning terms. Utterances in a dialogue are modelled as steps in a plan where understanding an utterance involves deriving the complete plan a speaker is attempting to achieve. However, previous speech act based approaches have been limited by a reliance upon relatively simplistic belief modelling techniques and their relationship to planning and plan recognition. In particular, such techniques assume precomputed nested belief structures. In this paper, we will present an approach to speech act processing based on novel belief modelling techniques where nested beliefs are propagated on demand.
* 6 pages
Is Word Sense Disambiguation just one more NLP task?
Feb 25, 1999This paper compares the tasks of part-of-speech (POS) tagging and word-sense-tagging or disambiguation (WSD), and argues that the tasks are not related by fineness of grain or anything like that, but are quite different kinds of task, particularly becuase there is nothing in POS corresponding to sense novelty. The paper also argues for the reintegration of sub-tasks that are being separated for evaluation
The "Fodor"-FODOR fallacy bites back
Feb 25, 1999The paper argues that Fodor and Lepore are misguided in their attack on Pustejovsky's Generative Lexicon, largely because their argument rests on a traditional, but implausible and discredited, view of the lexicon on which it is effectively empty of content, a view that stands in the long line of explaining word meaning (a) by ostension and then (b) explaining it by means of a vacuous symbol in a lexicon, often the word itself after typographic transmogrification. (a) and (b) both share the wrong belief that to a word must correspond a simple entity that is its meaning. I then turn to the semantic rules that Pustejovsky uses and argue first that, although they have novel features, they are in a well-established Artificial Intelligence tradition of explaining meaning by reference to structures that mention other structures assigned to words that may occur in close proximity to the first. It is argued that Fodor and Lepore's view that there cannot be such rules is without foundation, and indeed systems using such rules have proved their practical worth in computational systems. Their justification descends from line of argument, whose high points were probably Wittgenstein and Quine that meaning is not to be understood by simple links to the world, ostensive or otherwise, but by the relationship of whole cultural representational structures to each other and to the world as a whole.
Compacting the Penn Treebank Grammar
Jan 31, 1999
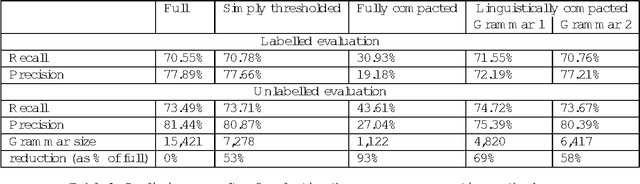
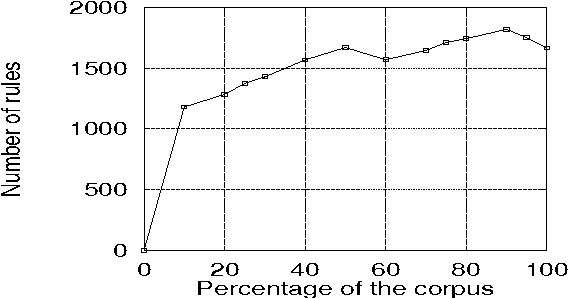
Treebanks, such as the Penn Treebank (PTB), offer a simple approach to obtaining a broad coverage grammar: one can simply read the grammar off the parse trees in the treebank. While such a grammar is easy to obtain, a square-root rate of growth of the rule set with corpus size suggests that the derived grammar is far from complete and that much more treebanked text would be required to obtain a complete grammar, if one exists at some limit. However, we offer an alternative explanation in terms of the underspecification of structures within the treebank. This hypothesis is explored by applying an algorithm to compact the derived grammar by eliminating redundant rules -- rules whose right hand sides can be parsed by other rules. The size of the resulting compacted grammar, which is significantly less than that of the full treebank grammar, is shown to approach a limit. However, such a compacted grammar does not yield very good performance figures. A version of the compaction algorithm taking rule probabilities into account is proposed, which is argued to be more linguistically motivated. Combined with simple thresholding, this method can be used to give a 58% reduction in grammar size without significant change in parsing performance, and can produce a 69% reduction with some gain in recall, but a loss in precision.
* 5 pages, 2 figures
Word Sense Disambiguation using Optimised Combinations of Knowledge Sources
Jun 22, 1998

Word sense disambiguation algorithms, with few exceptions, have made use of only one lexical knowledge source. We describe a system which performs unrestricted word sense disambiguation (on all content words in free text) by combining different knowledge sources: semantic preferences, dictionary definitions and subject/domain codes along with part-of-speech tags. The usefulness of these sources is optimised by means of a learning algorithm. We also describe the creation of a new sense tagged corpus by combining existing resources. Tested accuracy of our approach on this corpus exceeds 92%, demonstrating the viability of all-word disambiguation rather than restricting oneself to a small sample.
Eliminating deceptions and mistaken belief to infer conversational implicature
Jun 05, 1998
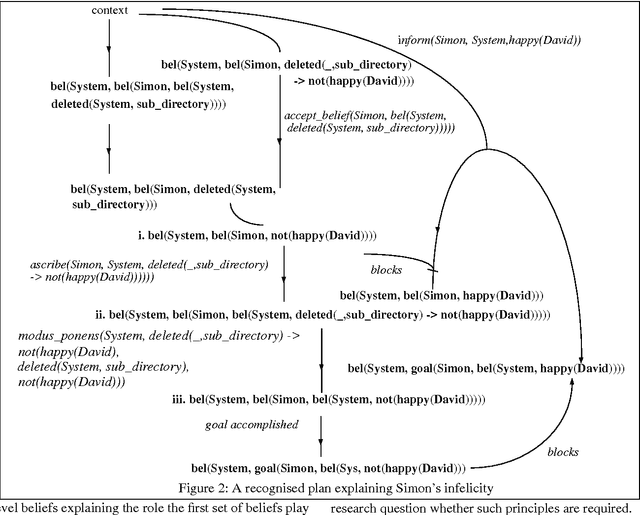
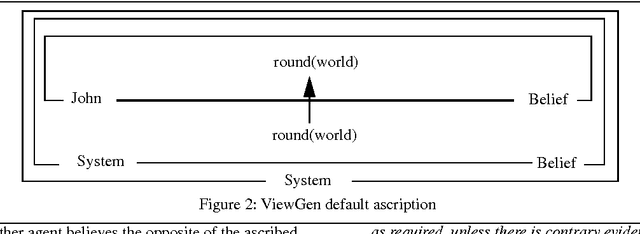
Conversational implicatures are usually described as being licensed by the disobeying or flouting of some principle by the speaker in cooperative dialogue. However, such work has failed to distinguish cases of the speaker flouting such a principle from cases where the speaker is either deceptive or holds a mistaken belief. In this paper, we demonstrate how the three different cases can be distinguished in terms of the beliefs ascribed to the speaker of the utterance. We argue that in the act of distinguishing the speaker's intention and ascribing such beliefs, the intended inference can be made by the hearer. This theory is implemented in ViewGen, a pre-existing belief modelling system used in a medical counselling domain.
Sense Tagging: Semantic Tagging with a Lexicon
May 29, 1997Sense tagging, the automatic assignment of the appropriate sense from some lexicon to each of the words in a text, is a specialised instance of the general problem of semantic tagging by category or type. We discuss which recent word sense disambiguation algorithms are appropriate for sense tagging. It is our belief that sense tagging can be carried out effectively by combining several simple, independent, methods and we include the design of such a tagger. A prototype of this system has been implemented, correctly tagging 86% of polysemous word tokens in a small test set, providing evidence that our hypothesis is correct.
Software Infrastructure for Natural Language Processing
Feb 10, 1997
We classify and review current approaches to software infrastructure for research, development and delivery of NLP systems. The task is motivated by a discussion of current trends in the field of NLP and Language Engineering. We describe a system called GATE (a General Architecture for Text Engineering) that provides a software infrastructure on top of which heterogeneous NLP processing modules may be evaluated and refined individually, or may be combined into larger application systems. GATE aims to support both researchers and developers working on component technologies (e.g. parsing, tagging, morphological analysis) and those working on developing end-user applications (e.g. information extraction, text summarisation, document generation, machine translation, and second language learning). GATE promotes reuse of component technology, permits specialisation and collaboration in large-scale projects, and allows for the comparison and evaluation of alternative technologies. The first release of GATE is now available - see http://www.dcs.shef.ac.uk/research/groups/nlp/gate/
* LaTeX, uses aclap.sty, 8 pages