 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Monolingual Assumptions: A Survey of Code-Switched NLP in the Era of Large Language Models
Oct 08, 2025



Code-switching (CSW), the alternation of languages and scripts within a single utterance, remains a fundamental challenge for multiling ual NLP, even amidst the rapid advances of large language models (LLMs). Most LLMs still struggle with mixed-language inputs, limited CSW datasets, and evaluation biases, hindering deployment in multilingual societies. This survey provides the first comprehensive analysis of CSW-aware LLM research, reviewing \total{unique_references} studies spanning five research areas, 12 NLP tasks, 30+ datasets, and 80+ languages. We classify recent advances by architecture, training strategy, and evaluation methodology, outlining how LLMs have reshaped CSW modeling and what challenges persist. The paper concludes with a roadmap emphasizing the need for inclusive datasets, fair evaluation, and linguistically grounded models to achieve truly multilingual intelligence. A curated collection of all resources is maintained at https://github.com/lingo-iitgn/awesome-code-mixing/.
Eka-Eval : A Comprehensive Evaluation Framework for Large Language Models in Indian Languages
Jul 02, 2025The rapid advancement of Large Language Models (LLMs) has intensified the need for evaluation frameworks that go beyond English centric benchmarks and address the requirements of linguistically diverse regions such as India. We present EKA-EVAL, a unified and production-ready evaluation framework that integrates over 35 benchmarks, including 10 Indic-specific datasets, spanning categories like reasoning, mathematics, tool use, long-context understanding, and reading comprehension. Compared to existing Indian language evaluation tools, EKA-EVAL offers broader benchmark coverage, with built-in support for distributed inference, quantization, and multi-GPU usage. Our systematic comparison positions EKA-EVAL as the first end-to-end, extensible evaluation suite tailored for both global and Indic LLMs, significantly lowering the barrier to multilingual benchmarking. The framework is open-source and publicly available at https://github.com/lingo-iitgn/ eka-eval and a part of ongoing EKA initiative (https://eka.soket.ai), which aims to scale up to over 100 benchmarks and establish a robust, multilingual evaluation ecosystem for LLMs.
COMI-LINGUA: Expert Annotated Large-Scale Dataset for Multitask NLP in Hindi-English Code-Mixing
Mar 27, 2025The rapid growth of digital communication has driven the widespread use of code-mixing, particularly Hindi-English, in multilingual communities. Existing datasets often focus on romanized text, have limited scope, or rely on synthetic data, which fails to capture realworld language nuances. Human annotations are crucial for assessing the naturalness and acceptability of code-mixed text. To address these challenges, We introduce COMI-LINGUA, the largest manually annotated dataset for code-mixed text, comprising 100,970 instances evaluated by three expert annotators in both Devanagari and Roman scripts. The dataset supports five fundamental NLP tasks: Language Identification, Matrix Language Identification, Part-of-Speech Tagging, Named Entity Recognition, and Translation. We evaluate LLMs on these tasks using COMILINGUA, revealing limitations in current multilingual modeling strategies and emphasizing the need for improved code-mixed text processing capabilities. COMI-LINGUA is publically availabe at: https://huggingface.co/datasets/LingoIITGN/COMI-LINGUA.
COMMENTATOR: A Code-mixed Multilingual Text Annotation Framework
Aug 06, 2024
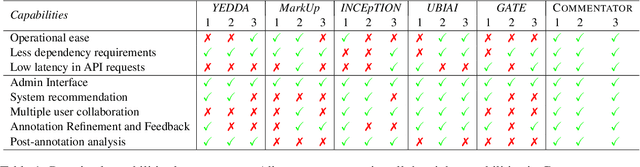


As the NLP community increasingly addresses challenges associated with multilingualism, robust annotation tools are essential to handle multilingual datasets efficiently. In this paper, we introduce a code-mixed multilingual text annotation framework, COMMENTATOR, specifically designed for annotating code-mixed text. The tool demonstrates its effectiveness in token-level and sentence-level language annotation tasks for Hinglish text. We perform robust qualitative human-based evaluations to showcase COMMENTATOR led to 5x faster annotations than the best baseline. Our code is publicly available at \url{https://github.com/lingo-iitgn/commentator}. The demonstration video is available at \url{https://bit.ly/commentator_video}.