 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Reinforcement Learning for Waste-Container Lifting Using Large-Scale Cranes with Underactuated Tools
Feb 05, 2026This paper studies the container lifting phase of a waste-container recycling task in urban environments, performed by a hydraulic loader crane equipped with an underactuated discharge unit, and proposes a residual reinforcement learning (RRL) approach that combines a nominal Cartesian controller with a learned residual policy. All experiments are conducted in simulation, where the task is characterized by tight geometric tolerances between the discharge-unit hooks and the container rings relative to the overall crane scale, making precise trajectory tracking and swing suppression essential. The nominal controller uses admittance control for trajectory tracking and pendulum-aware swing damping, followed by damped least-squares inverse kinematics with a nullspace posture term to generate joint velocity commands. A PPO-trained residual policy in Isaac Lab compensates for unmodeled dynamics and parameter variations, improving precision and robustness without requiring end-to-end learning from scratch. We further employ randomized episode initialization and domain randomization over payload properties, actuator gains, and passive joint parameters to enhance generalization. Simulation results demonstrate improved tracking accuracy, reduced oscillations, and higher lifting success rates compared to the nominal controller alone.
SensHRPS: Sensing Comfortable Human-Robot Proxemics and Personal Space With Eye-Tracking
Dec 10, 2025Social robots must adjust to human proxemic norms to ensure user comfort and engagement. While prior research demonstrates that eye-tracking features reliably estimate comfort in human-human interactions, their applicability to interactions with humanoid robots remains unexplored. In this study, we investigate user comfort with the robot "Ameca" across four experimentally controlled distances (0.5 m to 2.0 m) using mobile eye-tracking and subjective reporting (N=19). We evaluate multiple machine learning and deep learning models to estimate comfort based on gaze features. Contrary to previous human-human studies where Transformer models excelled, a Decision Tree classifier achieved the highest performance (F1-score = 0.73), with minimum pupil diameter identified as the most critical predictor. These findings suggest that physiological comfort thresholds in human-robot interaction differ from human-human dynamics and can be effectively modeled using interpretable logic.
Beyond Attention: Investigating the Threshold Where Objective Robot Exclusion Becomes Subjective
Apr 22, 2025As robots become increasingly involved in decision-making processes (e.g., personnel selection), concerns about fairness and social inclusion arise. This study examines social exclusion in robot-led group interviews by robot Ameca, exploring the relationship between objective exclusion (robot's attention allocation), subjective exclusion (perceived exclusion), mood change, and need fulfillment. In a controlled lab study (N = 35), higher objective exclusion significantly predicted subjective exclusion. In turn, subjective exclusion negatively impacted mood and need fulfillment but only mediated the relationship between objective exclusion and need fulfillment. A piecewise regression analysis identified a critical threshold at which objective exclusion begins to be perceived as subjective exclusion. Additionally, the standing position was the primary predictor of exclusion, whereas demographic factors (e.g., gender, height) had no significant effect. These findings underscore the need to consider both objective and subjective exclusion in human-robot interactions and have implications for fairness in robot-assisted hiring processes.
Evaluating the Robustness of Off-Road Autonomous Driving Segmentation against Adversarial Attacks: A Dataset-Centric analysis
Feb 03, 2024This study investigates the vulnerability of semantic segmentation models to adversarial input perturbations, in the domain of off-road autonomous driving. Despite good performance in generic conditions, the state-of-the-art classifiers are often susceptible to (even) small perturbations, ultimately resulting in inaccurate predictions with high confidence. Prior research has directed their focus on making models more robust by modifying the architecture and training with noisy input images, but has not explored the influence of datasets in adversarial attacks. Our study aims to address this gap by examining the impact of non-robust features in off-road datasets and comparing the effects of adversarial attacks on different segmentation network architectures. To enable this, a robust dataset is created consisting of only robust features and training the networks on this robustified dataset. We present both qualitative and quantitative analysis of our findings, which have important implications on improving the robustness of machine learning models in off-road autonomous driving applications. Additionally, this work contributes to the safe navigation of autonomous robot Unimog U5023 in rough off-road unstructured environments by evaluating the robustness of segmentation outputs. The code is publicly available at https://github.com/rohtkumar/adversarial_attacks_ on_segmentation
Dimensionality of datasets in object detection networks
Oct 13, 2022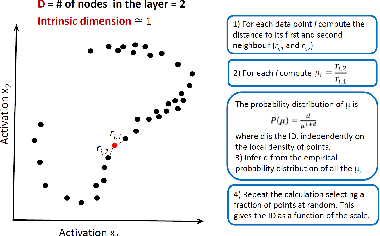
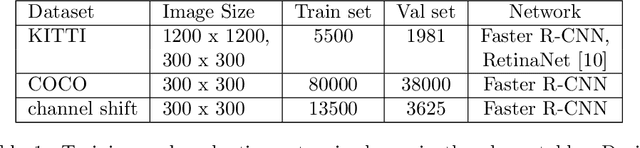
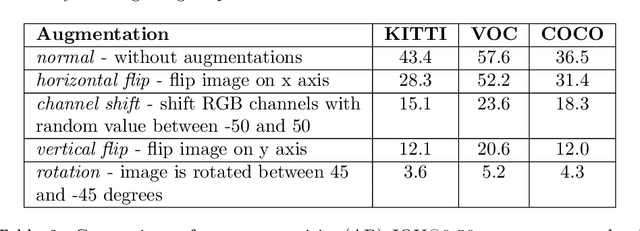
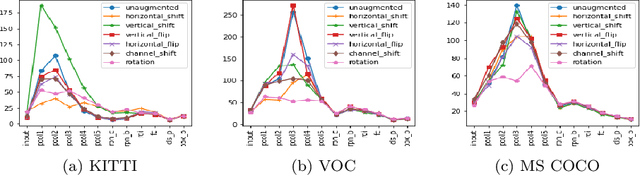
In recent years, convolutional neural networks (CNNs) are used in a large number of tasks in computer vision. One of them is object detection for autonomous driving. Although CNNs are used widely in many areas, what happens inside the network is still unexplained on many levels. Our goal is to determine the effect of Intrinsic dimension (i.e. minimum number of parameters required to represent data) in different layers on the accuracy of object detection network for augmented data sets. Our investigation determines that there is difference between the representation of normal and augmented data during feature extraction.
Real-time Emotion Appraisal with Circumplex Model for Human-Robot Interaction
Feb 20, 2022
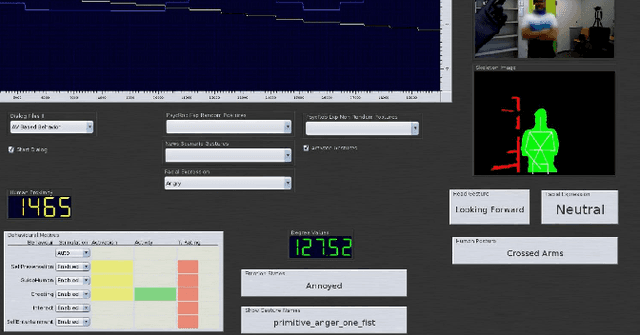
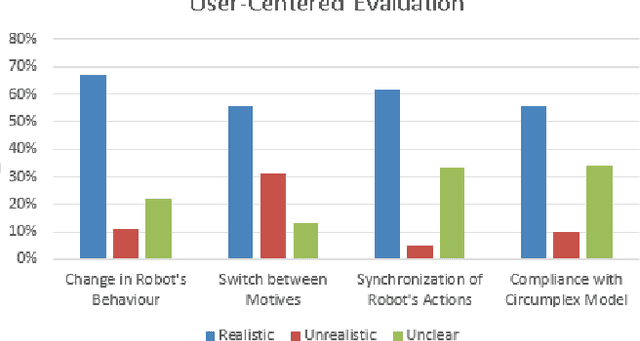
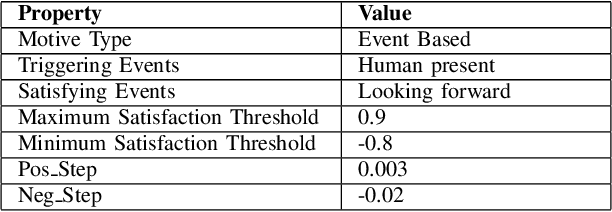
Emotions are the intrinsic or extrinsic representations of our experiences. The importance of emotions during a human-human interaction is immense as it formulates the basis of our interaction framework. There are several approaches in psychology to evaluate emotional states in humans based on the perceived stimuli. However, the topic has been less explored as far as human-robot interaction is concerned. This paper uses an appropriate emotion appraisal mechanism from psychology, generating an emotional state in a humanoid robot on-the-fly during human-robot interaction. Since the exhibition of only six basic emotions is not sufficient to cater to diverse situations, the use of the Circumplex Model in this work has allowed the life-sized robot called ROBIN to experience 28 emotional states in different interaction scenarios. Realistic robot behaviour has been generated based on the proposed appraisal system in various interaction scenarios.
Multi-Modal Depth Estimation Using Convolutional Neural Networks
Dec 17, 2020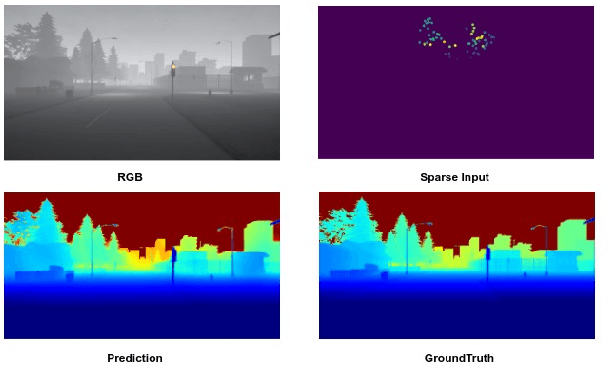
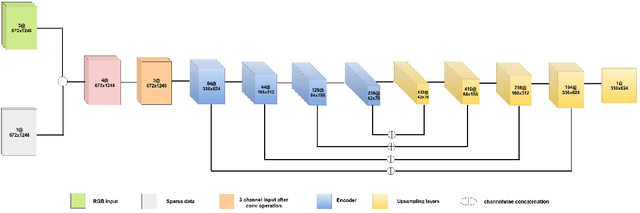
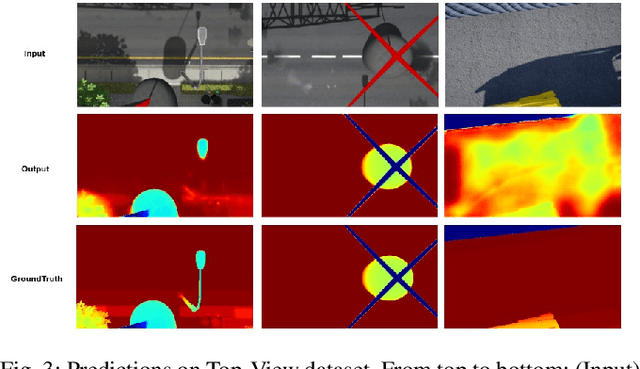
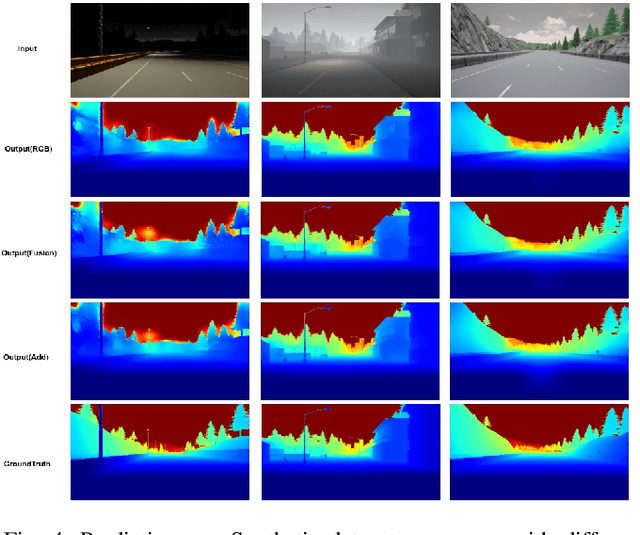
This paper addresses the problem of dense depth predictions from sparse distance sensor data and a single camera image on challenging weather conditions. This work explores the significance of different sensor modalities such as camera, Radar, and Lidar for estimating depth by applying Deep Learning approaches. Although Lidar has higher depth-sensing abilities than Radar and has been integrated with camera images in lots of previous works, depth estimation using CNN's on the fusion of robust Radar distance data and camera images has not been explored much. In this work, a deep regression network is proposed utilizing a transfer learning approach consisting of an encoder where a high performing pre-trained model has been used to initialize it for extracting dense features and a decoder for upsampling and predicting desired depth. The results are demonstrated on Nuscenes, KITTI, and a Synthetic dataset which was created using the CARLA simulator. Also, top-view zoom-camera images captured from the crane on a construction site are evaluated to estimate the distance of the crane boom carrying heavy loads from the ground to show the usability in safety-critical applications.
Radar+RGB Attentive Fusion for Robust Object Detection in Autonomous Vehicles
Aug 31, 2020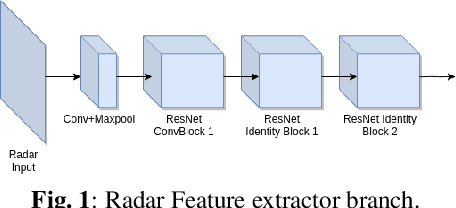
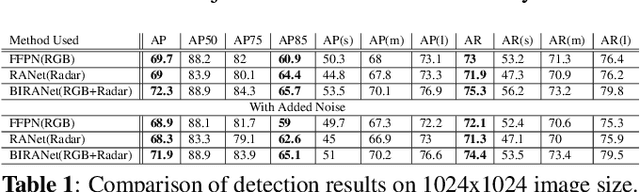
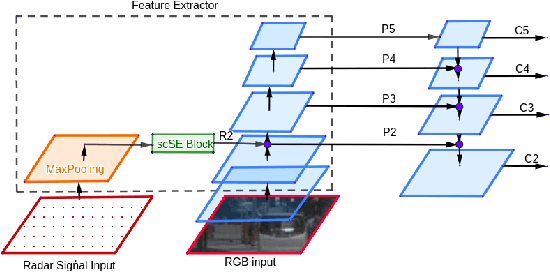
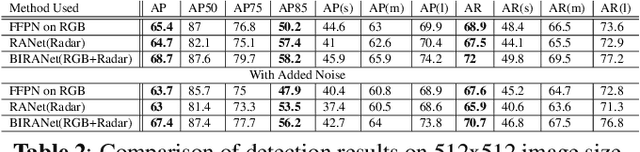
This paper presents two variations of architecture referred to as RANet and BIRANet. The proposed architecture aims to use radar signal data along with RGB camera images to form a robust detection network that works efficiently, even in variable lighting and weather conditions such as rain, dust, fog, and others. First, radar information is fused in the feature extractor network. Second, radar points are used to generate guided anchors. Third, a method is proposed to improve region proposal network targets. BIRANet yields 72.3/75.3% average AP/AR on the NuScenes dataset, which is better than the performance of our base network Faster-RCNN with Feature pyramid network(FFPN). RANet gives 69.6/71.9% average AP/AR on the same dataset, which is reasonably acceptable performance. Also, both BIRANet and RANet are evaluated to be robust towards the noise.