 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruth-value judgment in language models: belief directions are context sensitive
Apr 29, 2024



Recent work has demonstrated that the latent spaces of large language models (LLMs) contain directions predictive of the truth of sentences. Multiple methods recover such directions and build probes that are described as getting at a model's "knowledge" or "beliefs". We investigate this phenomenon, looking closely at the impact of context on the probes. Our experiments establish where in the LLM the probe's predictions can be described as being conditional on the preceding (related) sentences. Specifically, we quantify the responsiveness of the probes to the presence of (negated) supporting and contradicting sentences, and score the probes on their consistency. We also perform a causal intervention experiment, investigating whether moving the representation of a premise along these belief directions influences the position of the hypothesis along that same direction. We find that the probes we test are generally context sensitive, but that contexts which should not affect the truth often still impact the probe outputs. Our experiments show that the type of errors depend on the layer, the (type of) model, and the kind of data. Finally, our results suggest that belief directions are (one of the) causal mediators in the inference process that incorporates in-context information.
Reasoning about Ambiguous Definite Descriptions
Oct 23, 2023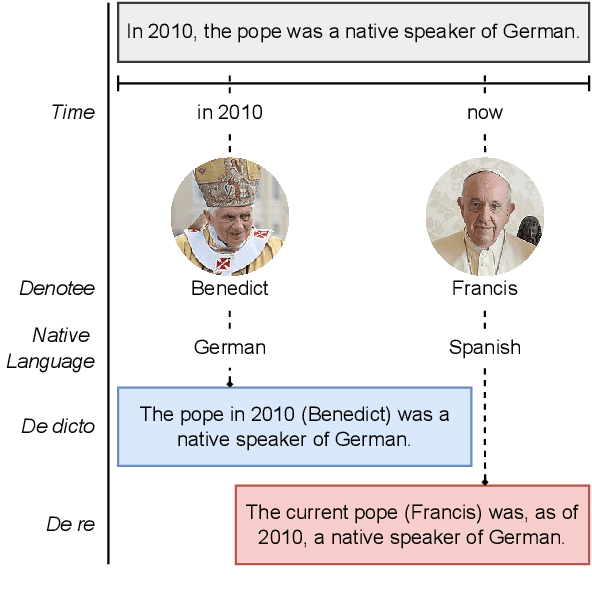


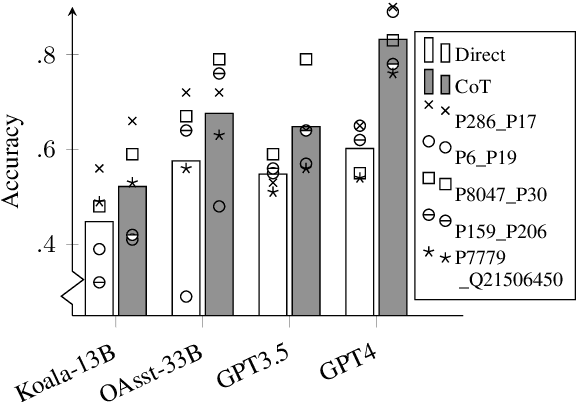
Natural language reasoning plays an increasingly important role in improving language models' ability to solve complex language understanding tasks. An interesting use case for reasoning is the resolution of context-dependent ambiguity. But no resources exist to evaluate how well Large Language Models can use explicit reasoning to resolve ambiguity in language. We propose to use ambiguous definite descriptions for this purpose and create and publish the first benchmark dataset consisting of such phrases. Our method includes all information required to resolve the ambiguity in the prompt, which means a model does not require anything but reasoning to do well. We find this to be a challenging task for recent LLMs. Code and data available at: https://github.com/sfschouten/exploiting-ambiguity
Cross-Domain Toxic Spans Detection
Jun 16, 2023Given the dynamic nature of toxic language use, automated methods for detecting toxic spans are likely to encounter distributional shift. To explore this phenomenon, we evaluate three approaches for detecting toxic spans under cross-domain conditions: lexicon-based, rationale extraction, and fine-tuned language models. Our findings indicate that a simple method using off-the-shelf lexicons performs best in the cross-domain setup. The cross-domain error analysis suggests that (1) rationale extraction methods are prone to false negatives, while (2) language models, despite performing best for the in-domain case, recall fewer explicitly toxic words than lexicons and are prone to certain types of false positives. Our code is publicly available at: https://github.com/sfschouten/toxic-cross-domain.
A Song of agreement: Evaluating the Evaluation of Explainable Artificial Intelligence in Natural Language Processing
May 09, 2022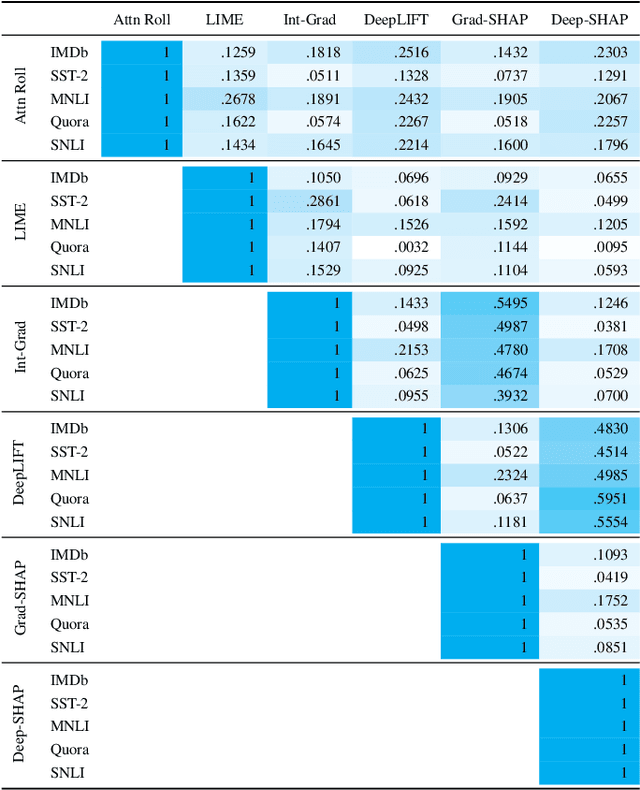

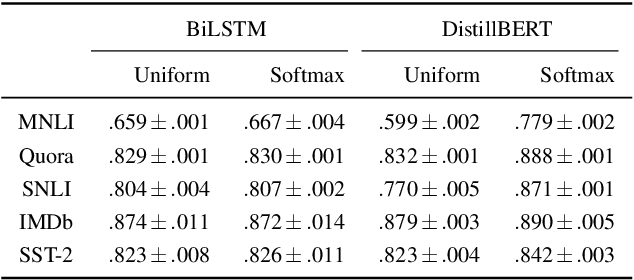
There has been significant debate in the NLP community about whether or not attention weights can be used as an explanation - a mechanism for interpreting how important each input token is for a particular prediction. The validity of "attention as explanation" has so far been evaluated by computing the rank correlation between attention-based explanations and existing feature attribution explanations using LSTM-based models. In our work, we (i) compare the rank correlation between five more recent feature attribution methods and two attention-based methods, on two types of NLP tasks, and (ii) extend this analysis to also include transformer-based models. We find that attention-based explanations do not correlate strongly with any recent feature attribution methods, regardless of the model or task. Furthermore, we find that none of the tested explanations correlate strongly with one another for the transformer-based model, leading us to question the underlying assumption that we should measure the validity of attention-based explanations based on how well they correlate with existing feature attribution explanation methods. After conducting experiments on five datasets using two different models, we argue that the community should stop using rank correlation as an evaluation metric for attention-based explanations. We suggest that researchers and practitioners should instead test various explanation methods and employ a human-in-the-loop process to determine if the explanations align with human intuition for the particular use case at hand.
Order in the Court: Explainable AI Methods Prone to Disagreement
May 07, 2021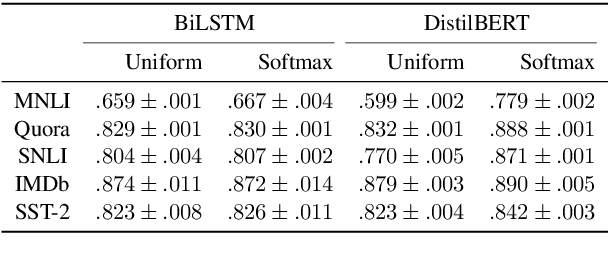
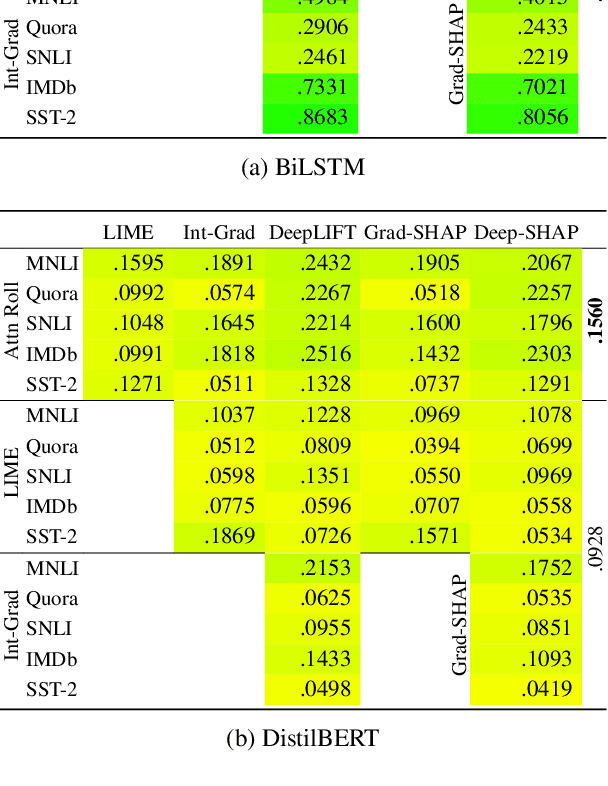
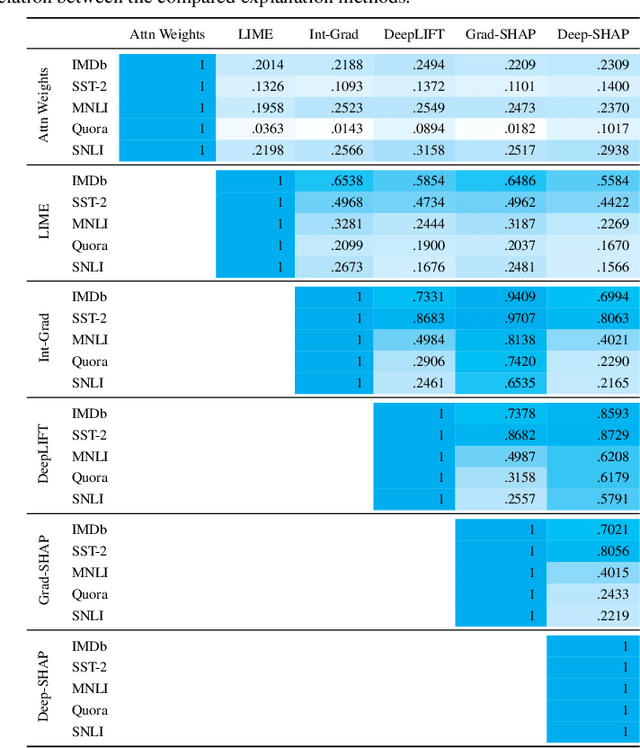
In Natural Language Processing, feature-additive explanation methods quantify the independent contribution of each input token towards a model's decision. By computing the rank correlation between attention weights and the scores produced by a small sample of these methods, previous analyses have sought to either invalidate or support the role of attention-based explanations as a faithful and plausible measure of salience. To investigate what measures of rank correlation can reliably conclude, we comprehensively compare feature-additive methods, including attention-based explanations, across several neural architectures and tasks. In most cases, we find that none of our chosen methods agree. Therefore, we argue that rank correlation is largely uninformative and does not measure the quality of feature-additive methods. Additionally, the range of conclusions a practitioner may draw from a single explainability algorithm are limited.