 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysMetrics.Weather: An Evaluation Framework for Physical Consistency in ML Weather Models
Jun 09, 2026Machine learning weather prediction (MLWP) models have achieved impressive forecasting performance at a small fraction of the computational costs required for traditional physics-based methods. However, they are primarily (1) data-driven and (2) evaluated using pixel-wide error metrics (e.g., RMSE), so there are no guarantees that their forecasts are consistent with known physical laws. We introduce PhysMetrics.Weather, an evaluation framework that assesses the physical realism of MLWP models across three types of metrics: conservation, spectral, and dynamical. By quantifying physical realism, this tool guides the development of physics-informed architectures and helps evaluate whether MLWP models are reliable for operational use. Our framework is available on Github at https://github.com/Emmakast/PhysMetrics.Weather.
Same Content, Different Answers: Cross-Modal Inconsistency in MLLMs
Dec 09, 2025We introduce two new benchmarks REST and REST+(Render-Equivalence Stress Tests) to enable systematic evaluation of cross-modal inconsistency in multimodal large language models (MLLMs). MLLMs are trained to represent vision and language in the same embedding space, yet they cannot perform the same tasks in both modalities. Our benchmarks contain samples with the same semantic information in three modalities (image, text, mixed) and we show that state-of-the-art MLLMs cannot consistently reason over these different modalities. We evaluate 15 MLLMs and find that the degree of modality inconsistency varies substantially, even when accounting for problems with text recognition (OCR). Neither rendering text as image nor rendering an image as text solves the inconsistency. Even if OCR is correct, we find that visual characteristics (text colour and resolution, but not font) and the number of vision tokens have an impact on model performance. Finally, we find that our consistency score correlates with the modality gap between text and images, highlighting a mechanistic interpretation of cross-modal inconsistent MLLMs.
Group Equivariance Meets Mechanistic Interpretability: Equivariant Sparse Autoencoders
Nov 12, 2025



Sparse autoencoders (SAEs) have proven useful in disentangling the opaque activations of neural networks, primarily large language models, into sets of interpretable features. However, adapting them to domains beyond language, such as scientific data with group symmetries, introduces challenges that can hinder their effectiveness. We show that incorporating such group symmetries into the SAEs yields features more useful in downstream tasks. More specifically, we train autoencoders on synthetic images and find that a single matrix can explain how their activations transform as the images are rotated. Building on this, we develop adaptively equivariant SAEs that can adapt to the base model's level of equivariance. These adaptive SAEs discover features that lead to superior probing performance compared to regular SAEs, demonstrating the value of incorporating symmetries in mechanistic interpretability tools.
Information Retrieval for Climate Impact
Apr 01, 2025The purpose of the MANILA24 Workshop on information retrieval for climate impact was to bring together researchers from academia, industry, governments, and NGOs to identify and discuss core research problems in information retrieval to assess climate change impacts. The workshop aimed to foster collaboration by bringing communities together that have so far not been very well connected -- information retrieval, natural language processing, systematic reviews, impact assessments, and climate science. The workshop brought together a diverse set of researchers and practitioners interested in contributing to the development of a technical research agenda for information retrieval to assess climate change impacts.
Aurora: A Foundation Model of the Atmosphere
May 20, 2024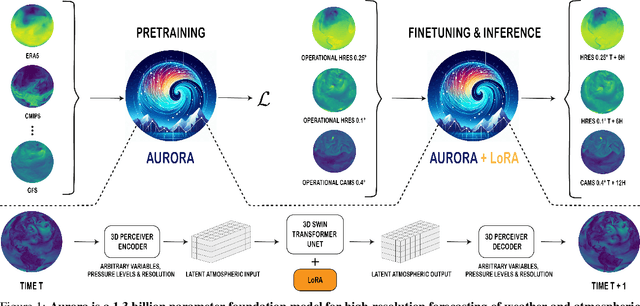
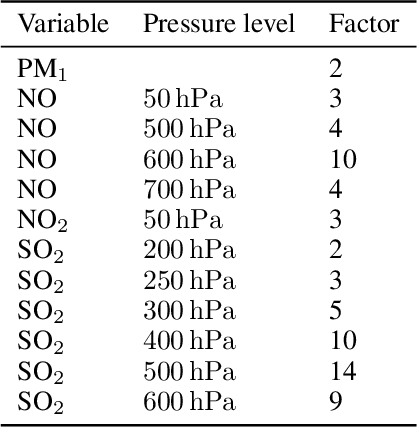
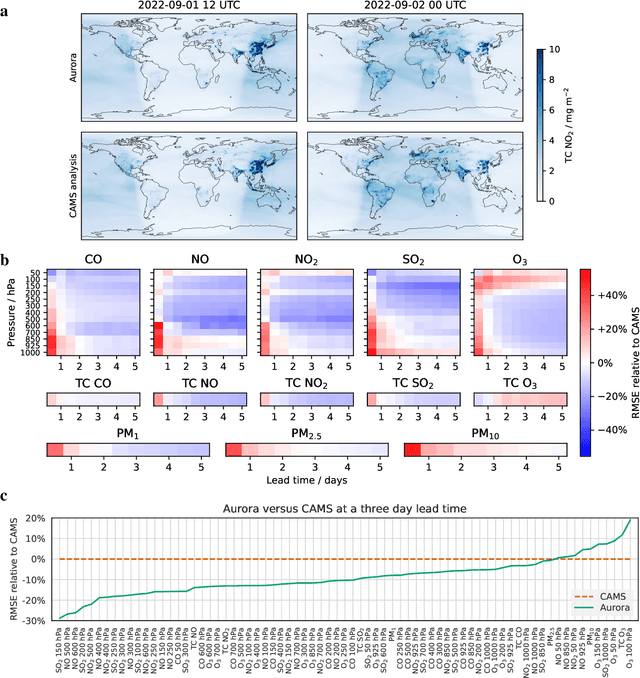

Deep learning foundation models are revolutionizing many facets of science by leveraging vast amounts of data to learn general-purpose representations that can be adapted to tackle diverse downstream tasks. Foundation models hold the promise to also transform our ability to model our planet and its subsystems by exploiting the vast expanse of Earth system data. Here we introduce Aurora, a large-scale foundation model of the atmosphere trained on over a million hours of diverse weather and climate data. Aurora leverages the strengths of the foundation modelling approach to produce operational forecasts for a wide variety of atmospheric prediction problems, including those with limited training data, heterogeneous variables, and extreme events. In under a minute, Aurora produces 5-day global air pollution predictions and 10-day high-resolution weather forecasts that outperform state-of-the-art classical simulation tools and the best specialized deep learning models. Taken together, these results indicate that foundation models can transform environmental forecasting.
Clifford-Steerable Convolutional Neural Networks
Feb 22, 2024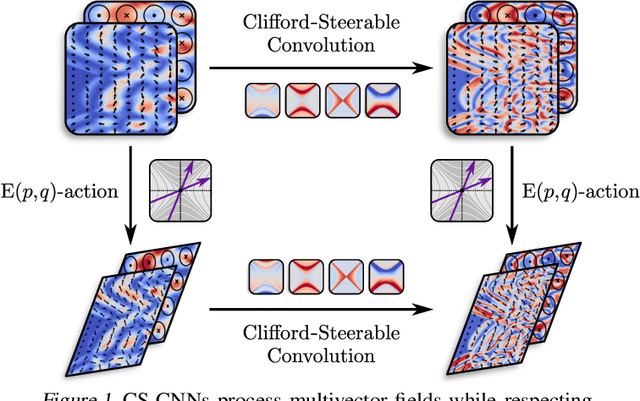
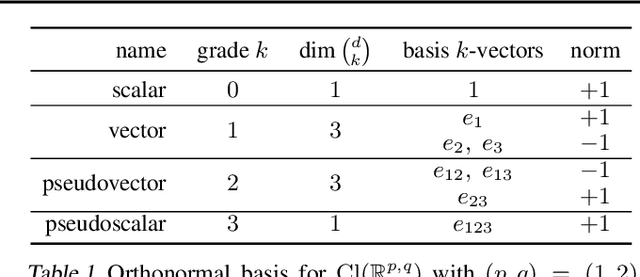
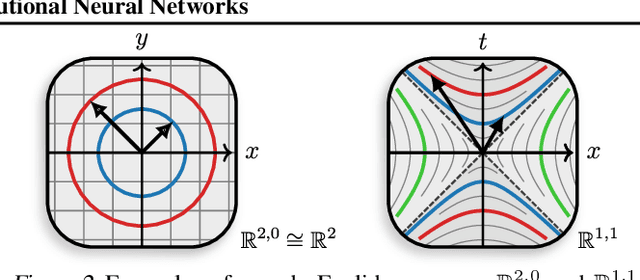
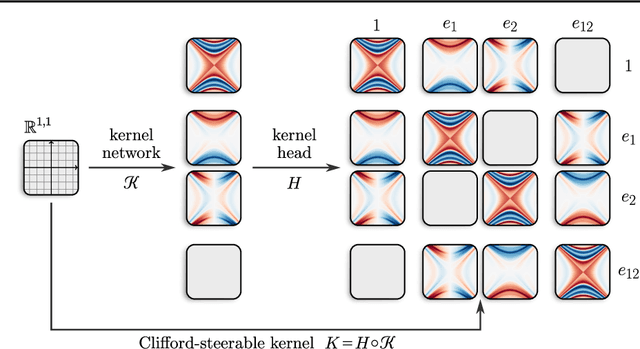
We present Clifford-Steerable Convolutional Neural Networks (CS-CNNs), a novel class of $\mathrm{E}(p, q)$-equivariant CNNs. CS-CNNs process multivector fields on pseudo-Euclidean spaces $\mathbb{R}^{p,q}$. They cover, for instance, $\mathrm{E}(3)$-equivariance on $\mathbb{R}^3$ and Poincar\'e-equivariance on Minkowski spacetime $\mathbb{R}^{1,3}$. Our approach is based on an implicit parametrization of $\mathrm{O}(p,q)$-steerable kernels via Clifford group equivariant neural networks. We significantly and consistently outperform baseline methods on fluid dynamics as well as relativistic electrodynamics forecasting tasks.
Semi-Supervised Object Detection in the Open World
Jul 28, 2023Existing approaches for semi-supervised object detection assume a fixed set of classes present in training and unlabeled datasets, i.e., in-distribution (ID) data. The performance of these techniques significantly degrades when these techniques are deployed in the open-world, due to the fact that the unlabeled and test data may contain objects that were not seen during training, i.e., out-of-distribution (OOD) data. The two key questions that we explore in this paper are: can we detect these OOD samples and if so, can we learn from them? With these considerations in mind, we propose the Open World Semi-supervised Detection framework (OWSSD) that effectively detects OOD data along with a semi-supervised learning pipeline that learns from both ID and OOD data. We introduce an ensemble based OOD detector consisting of lightweight auto-encoder networks trained only on ID data. Through extensive evalulation, we demonstrate that our method performs competitively against state-of-the-art OOD detection algorithms and also significantly boosts the semi-supervised learning performance in open-world scenarios.
Explaining Predictions from Machine Learning Models: Algorithms, Users, and Pedagogy
Sep 12, 2022
Model explainability has become an important problem in machine learning (ML) due to the increased effect that algorithmic predictions have on humans. Explanations can help users understand not only why ML models make certain predictions, but also how these predictions can be changed. In this thesis, we examine the explainability of ML models from three vantage points: algorithms, users, and pedagogy, and contribute several novel solutions to the explainability problem.
Towards the Use of Saliency Maps for Explaining Low-Quality Electrocardiograms to End Users
Jul 06, 2022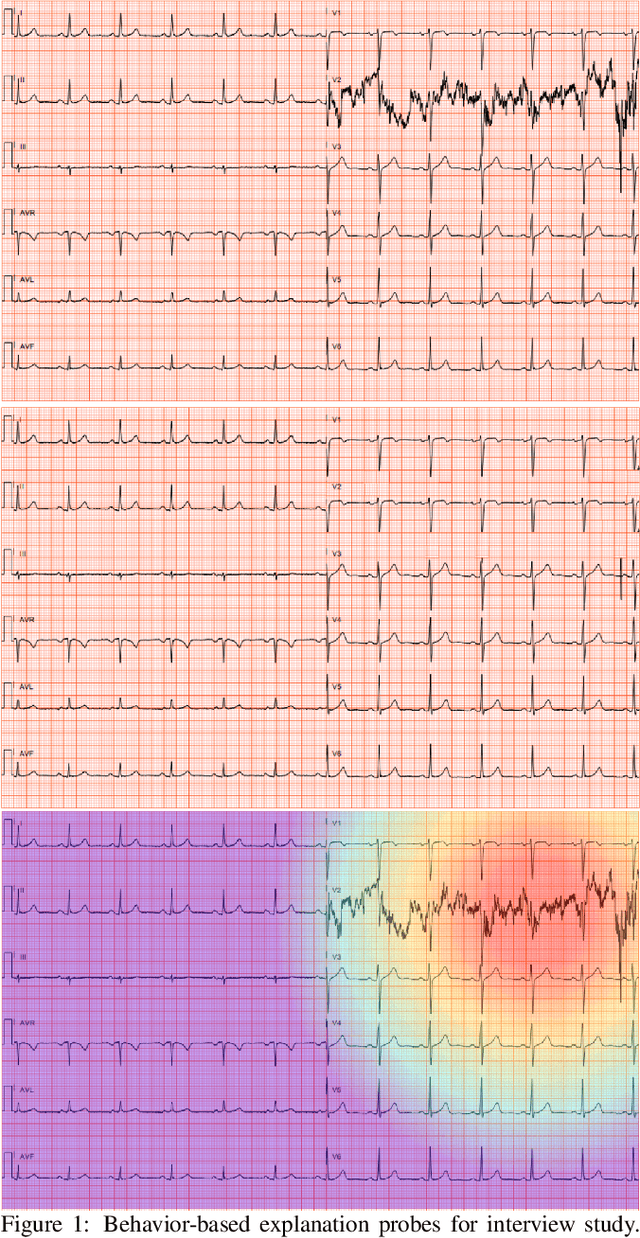

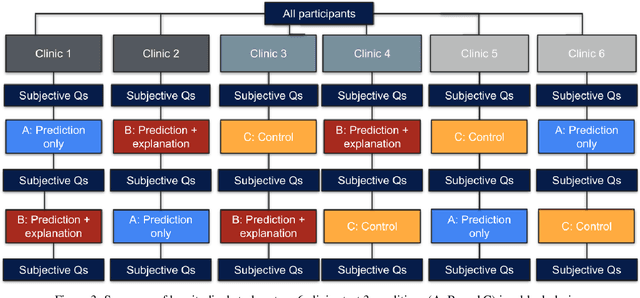
When using medical images for diagnosis, either by clinicians or artificial intelligence (AI) systems, it is important that the images are of high quality. When an image is of low quality, the medical exam that produced the image often needs to be redone. In telemedicine, a common problem is that the quality issue is only flagged once the patient has left the clinic, meaning they must return in order to have the exam redone. This can be especially difficult for people living in remote regions, who make up a substantial portion of the patients at Portal Telemedicina, a digital healthcare organization based in Brazil. In this paper, we report on ongoing work regarding (i) the development of an AI system for flagging and explaining low-quality medical images in real-time, (ii) an interview study to understand the explanation needs of stakeholders using the AI system at OurCompany, and, (iii) a longitudinal user study design to examine the effect of including explanations on the workflow of the technicians in our clinics. To the best of our knowledge, this would be the first longitudinal study on evaluating the effects of XAI methods on end-users -- stakeholders that use AI systems but do not have AI-specific expertise. We welcome feedback and suggestions on our experimental setup.
A Song of agreement: Evaluating the Evaluation of Explainable Artificial Intelligence in Natural Language Processing
May 09, 2022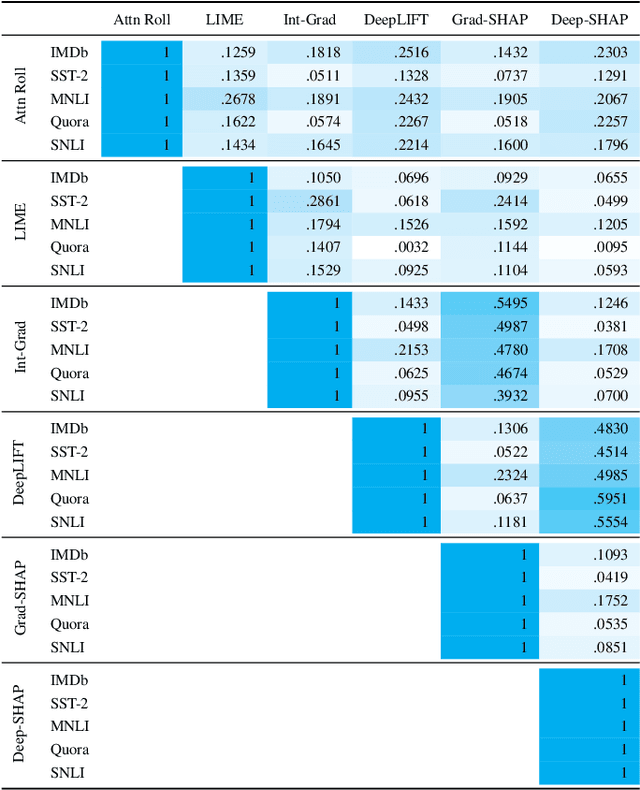

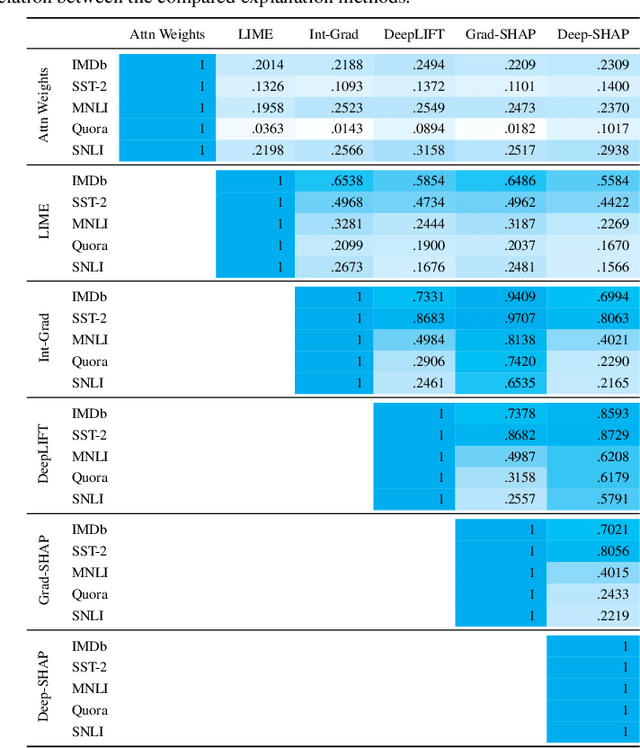
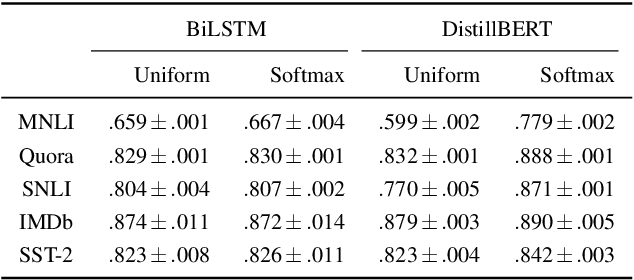
There has been significant debate in the NLP community about whether or not attention weights can be used as an explanation - a mechanism for interpreting how important each input token is for a particular prediction. The validity of "attention as explanation" has so far been evaluated by computing the rank correlation between attention-based explanations and existing feature attribution explanations using LSTM-based models. In our work, we (i) compare the rank correlation between five more recent feature attribution methods and two attention-based methods, on two types of NLP tasks, and (ii) extend this analysis to also include transformer-based models. We find that attention-based explanations do not correlate strongly with any recent feature attribution methods, regardless of the model or task. Furthermore, we find that none of the tested explanations correlate strongly with one another for the transformer-based model, leading us to question the underlying assumption that we should measure the validity of attention-based explanations based on how well they correlate with existing feature attribution explanation methods. After conducting experiments on five datasets using two different models, we argue that the community should stop using rank correlation as an evaluation metric for attention-based explanations. We suggest that researchers and practitioners should instead test various explanation methods and employ a human-in-the-loop process to determine if the explanations align with human intuition for the particular use case at hand.