 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Trust or Not to Trust a Regressor: Estimating and Explaining Trustworthiness of Regression Predictions
Apr 14, 2021
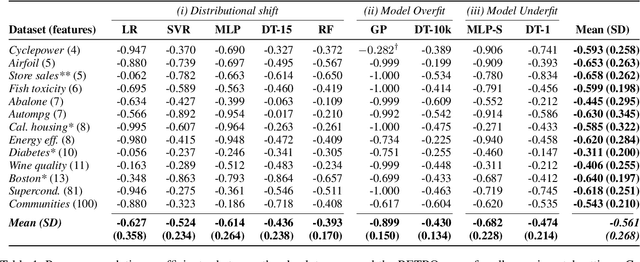
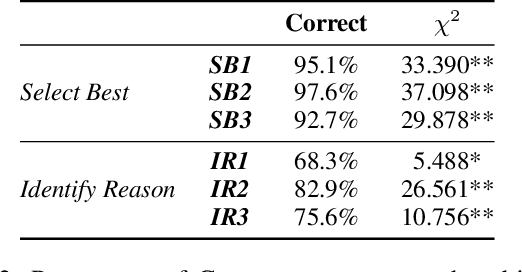
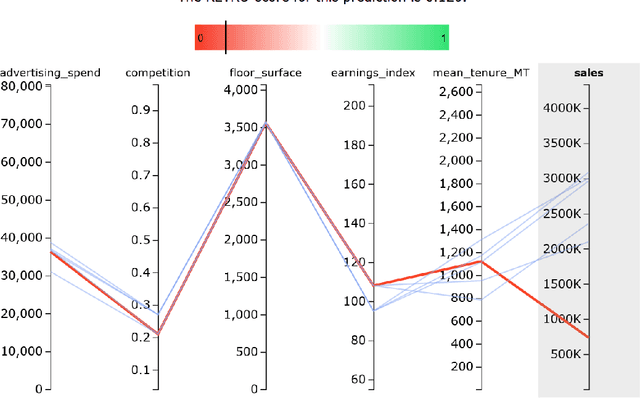
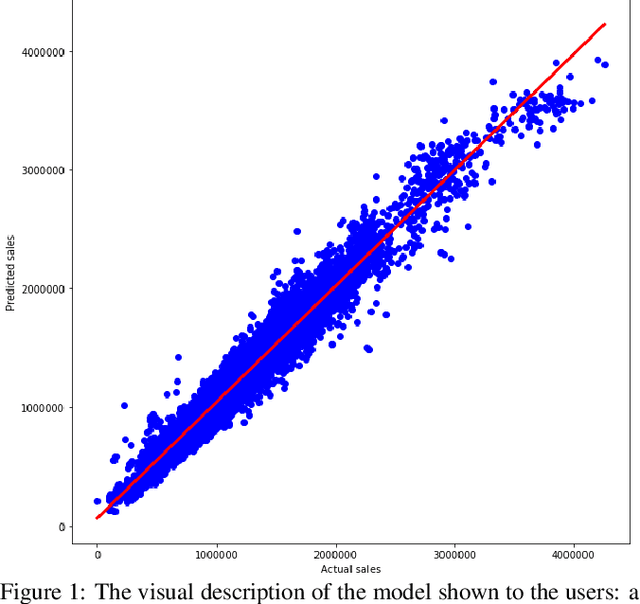
In hybrid human-AI systems, users need to decide whether or not to trust an algorithmic prediction while the true error in the prediction is unknown. To accommodate such settings, we introduce RETRO-VIZ, a method for (i) estimating and (ii) explaining trustworthiness of regression predictions. It consists of RETRO, a quantitative estimate of the trustworthiness of a prediction, and VIZ, a visual explanation that helps users identify the reasons for the (lack of) trustworthiness of a prediction. We find that RETRO-scores negatively correlate with prediction error across 117 experimental settings, indicating that RETRO provides a useful measure to distinguish trustworthy predictions from untrustworthy ones. In a user study with 41 participants, we find that VIZ-explanations help users identify whether a prediction is trustworthy or not: on average, 95.1% of participants correctly select the more trustworthy prediction, given a pair of predictions. In addition, an average of 75.6% of participants can accurately describe why a prediction seems to be (not) trustworthy. Finally, we find that the vast majority of users subjectively experience RETRO-VIZ as a useful tool to assess the trustworthiness of algorithmic predictions.
Diversifying Task-oriented Dialogue Response Generation with Prototype Guided Paraphrasing
Aug 07, 2020Existing methods for Dialogue Response Generation (DRG) in Task-oriented Dialogue Systems (TDSs) can be grouped into two categories: template-based and corpus-based. The former prepare a collection of response templates in advance and fill the slots with system actions to produce system responses at runtime. The latter generate system responses token by token by taking system actions into account. While template-based DRG provides high precision and highly predictable responses, they usually lack in terms of generating diverse and natural responses when compared to (neural) corpus-based approaches. Conversely, while corpus-based DRG methods are able to generate natural responses, we cannot guarantee their precision or predictability. Moreover, the diversity of responses produced by today's corpus-based DRG methods is still limited. We propose to combine the merits of template-based and corpus-based DRGs by introducing a prototype-based, paraphrasing neural network, called P2-Net, which aims to enhance quality of the responses in terms of both precision and diversity. Instead of generating a response from scratch, P2-Net generates system responses by paraphrasing template-based responses. To guarantee the precision of responses, P2-Net learns to separate a response into its semantics, context influence, and paraphrasing noise, and to keep the semantics unchanged during paraphrasing. To introduce diversity, P2-Net randomly samples previous conversational utterances as prototypes, from which the model can then extract speaking style information. We conduct extensive experiments on the MultiWOZ dataset with both automatic and human evaluations. The results show that P2-Net achieves a significant improvement in diversity while preserving the semantics of responses.
Actionable Interpretability through Optimizable Counterfactual Explanations for Tree Ensembles
Nov 27, 2019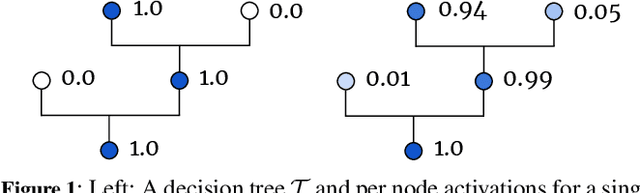

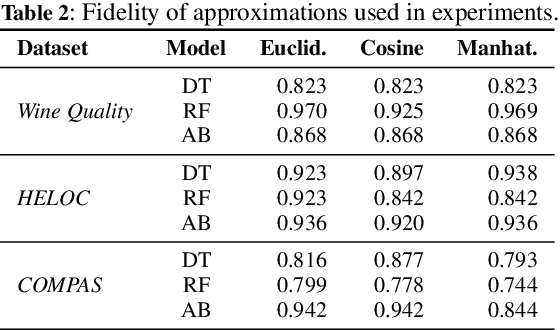
Counterfactual explanations help users understand why machine learned models make certain decisions, and more specifically, how these decisions can be changed. In this work, we frame the problem of finding counterfactual explanations -- the minimal perturbation to an input such that the prediction changes -- as an optimization task. Previously, optimization techniques for generating counterfactual examples could only be applied to differentiable models, or alternatively via query access to the model by estimating gradients from randomly sampled perturbations. In order to accommodate non-differentiable models such as tree ensembles, we propose using probabilistic model approximations in the optimization framework. We introduce a novel approximation technique that is effective for finding counterfactual explanations while also closely approximating the original model. Our results show that our method is able to produce counterfactual examples that are closer to the original instance in terms of Euclidean, Cosine, and Manhattan distance compared to other methods specifically designed for tree ensembles.
Contrastive Explanations for Large Errors in Retail Forecasting Predictions through Monte Carlo Simulations
Jul 17, 2019
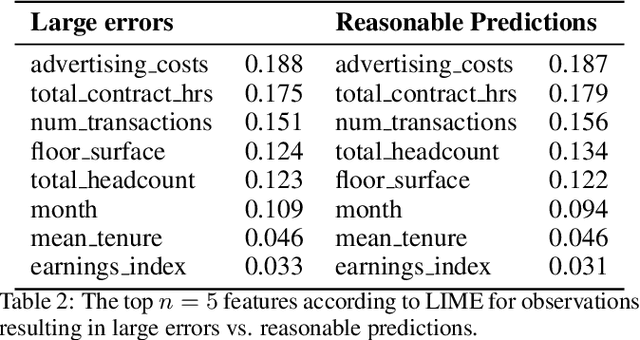
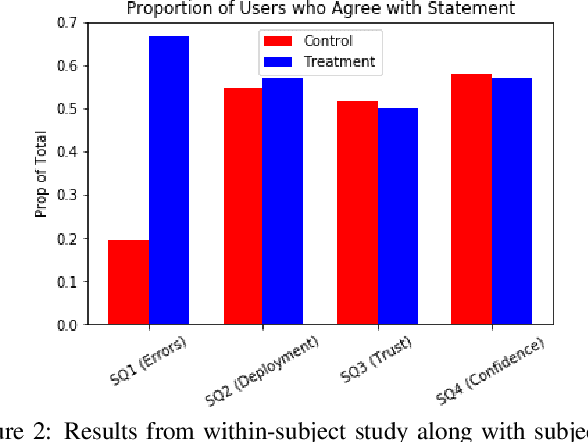
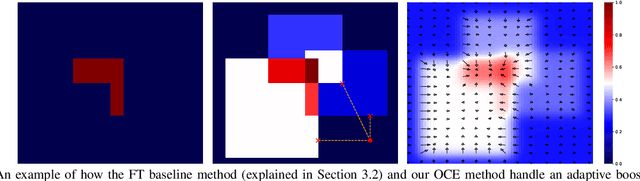
At Ahold Delhaize, there is an interest in using more complex machine learning techniques for sales forecasting. It is difficult to convince analysts, along with their superiors, to adopt these techniques since the models are considered to be 'black boxes,' even if they perform better than current models in use. We aim to explore the impact of contrastive explanations about large errors on users' attitudes towards a 'black-box' model. In this work, we make two contributions. The first is an algorithm, Monte Carlo Bounds for Reasonable Predictions (MC-BRP). Given a large error, MC-BRP determines (1) feature values that would result in a reasonable prediction, and (2) general trends between each feature and the target, based on Monte Carlo simulations. The second contribution is the evaluation of MC-BRP along with its outcomes, which has both objective and subjective components. We evaluate on a real dataset with real users from Ahold Delhaize by conducting a user study to determine if explanations generated by MC-BRP help users understand why a prediction results in a large error, and if this promotes trust in an automatically-learned model. The study shows that users are able to answer objective questions about the model's predictions with overall 81.7% accuracy when provided with these contrastive explanations. We also show that users who saw MC-BRP explanations understand why the model makes large errors in predictions significantly more than users in the control group.
Global Aggregations of Local Explanations for Black Box models
Jul 05, 2019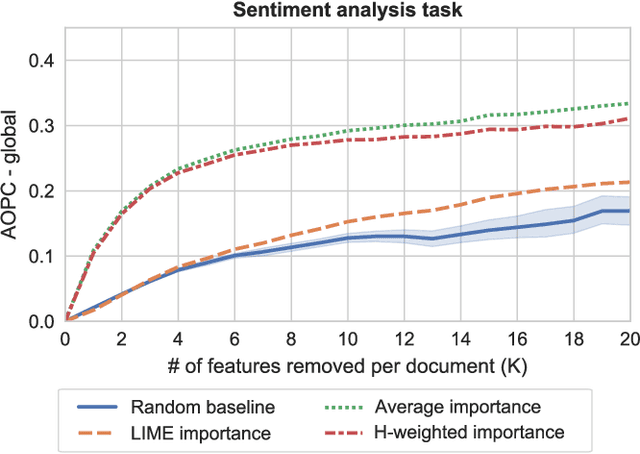
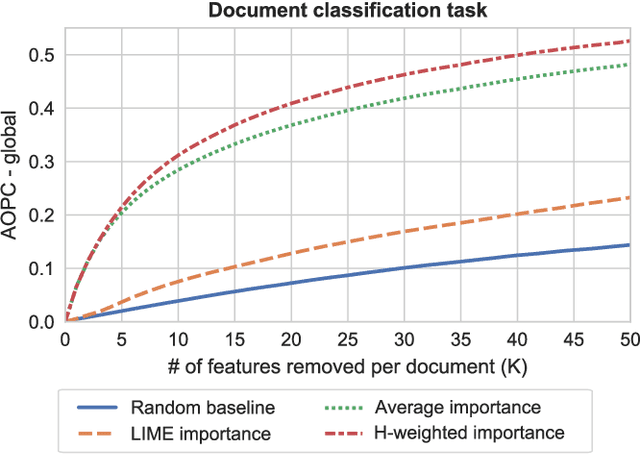


The decision-making process of many state-of-the-art machine learning models is inherently inscrutable to the extent that it is impossible for a human to interpret the model directly: they are black box models. This has led to a call for research on explaining black box models, for which there are two main approaches. Global explanations that aim to explain a model's decision making process in general, and local explanations that aim to explain a single prediction. Since it remains challenging to establish fidelity to black box models in globally interpretable approximations, much attention is put on local explanations. However, whether local explanations are able to reliably represent the black box model and provide useful insights remains an open question. We present Global Aggregations of Local Explanations (GALE) with the objective to provide insights in a model's global decision making process. Overall, our results reveal that the choice of aggregation matters. We find that the global importance introduced by Local Interpretable Model-agnostic Explanations (LIME) does not reliably represent the model's global behavior. Our proposed aggregations are better able to represent how features affect the model's predictions, and to provide global insights by identifying distinguishing features.
Explaining Predictions from Tree-based Boosting Ensembles
Jul 04, 2019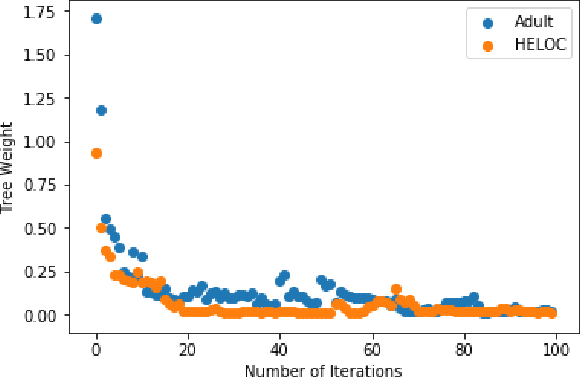
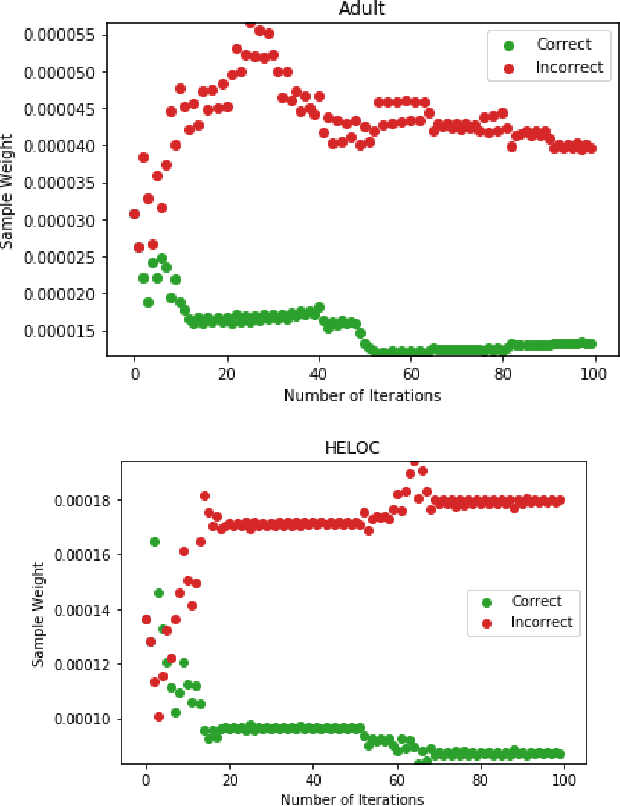
Understanding how "black-box" models arrive at their predictions has sparked significant interest from both within and outside the AI community. Our work focuses on doing this by generating local explanations about individual predictions for tree-based ensembles, specifically Gradient Boosting Decision Trees (GBDTs). Given a correctly predicted instance in the training set, we wish to generate a counterfactual explanation for this instance, that is, the minimal perturbation of this instance such that the prediction flips to the opposite class. Most existing methods for counterfactual explanations are (1) model-agnostic, so they do not take into account the structure of the original model, and/or (2) involve building a surrogate model on top of the original model, which is not guaranteed to represent the original model accurately. There exists a method specifically for random forests; we wish to extend this method for GBDTs. This involves accounting for (1) the sequential dependency between trees and (2) training on the negative gradients instead of the original labels.