 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Invariant Bidirectional Temporal Representation Distillation Network for Missing Multimodal Sentiment Analysis
Jan 07, 2025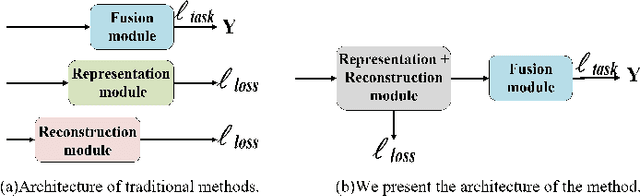
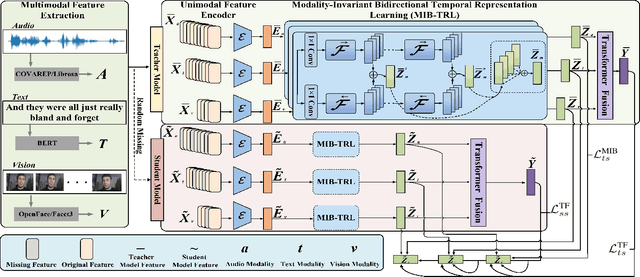
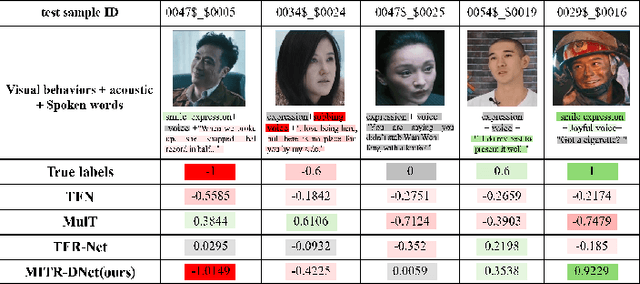
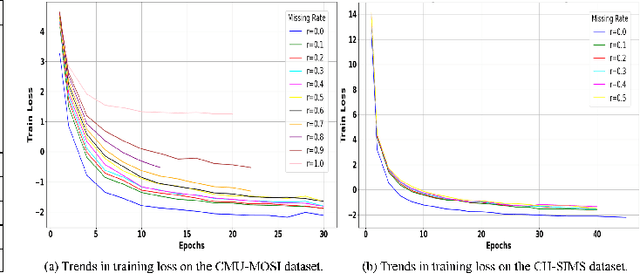
Multimodal Sentiment Analysis (MSA) integrates diverse modalities(text, audio, and video) to comprehensively analyze and understand individuals' emotional states. However, the real-world prevalence of incomplete data poses significant challenges to MSA, mainly due to the randomness of modality missing. Moreover, the heterogeneity issue in multimodal data has yet to be effectively addressed. To tackle these challenges, we introduce the Modality-Invariant Bidirectional Temporal Representation Distillation Network (MITR-DNet) for Missing Multimodal Sentiment Analysis. MITR-DNet employs a distillation approach, wherein a complete modality teacher model guides a missing modality student model, ensuring robustness in the presence of modality missing. Simultaneously, we developed the Modality-Invariant Bidirectional Temporal Representation Learning Module (MIB-TRL) to mitigate heterogeneity.
PCQ: Emotion Recognition in Speech via Progressive Channel Querying
Jul 17, 2024In human-computer interaction (HCI), Speech Emotion Recognition (SER) is a key technology for understanding human intentions and emotions. Traditional SER methods struggle to effectively capture the long-term temporal correla-tions and dynamic variations in complex emotional expressions. To overcome these limitations, we introduce the PCQ method, a pioneering approach for SER via \textbf{P}rogressive \textbf{C}hannel \textbf{Q}uerying. This method can drill down layer by layer in the channel dimension through the channel query technique to achieve dynamic modeling of long-term contextual information of emotions. This mul-ti-level analysis gives the PCQ method an edge in capturing the nuances of hu-man emotions. Experimental results show that our model improves the weighted average (WA) accuracy by 3.98\% and 3.45\% and the unweighted av-erage (UA) accuracy by 5.67\% and 5.83\% on the IEMOCAP and EMODB emotion recognition datasets, respectively, significantly exceeding the baseline levels.
MFHCA: Enhancing Speech Emotion Recognition Via Multi-Spatial Fusion and Hierarchical Cooperative Attention
Apr 21, 2024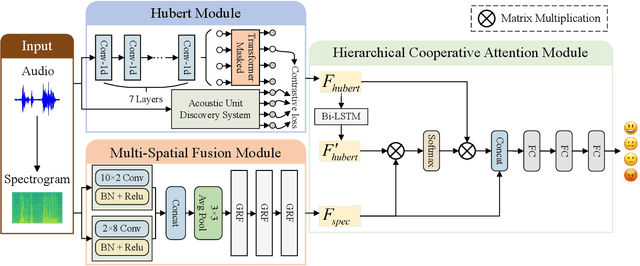
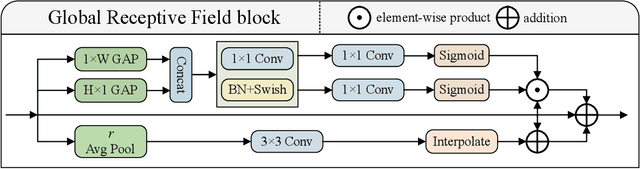
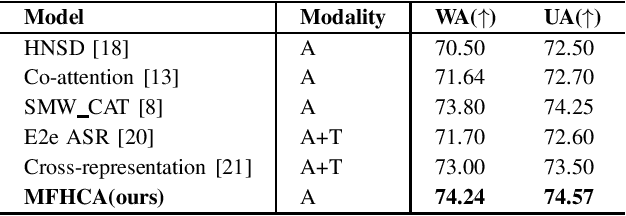
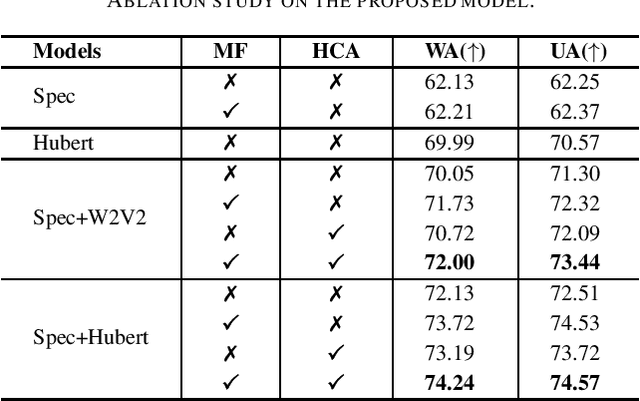
Speech emotion recognition is crucial in human-computer interaction, but extracting and using emotional cues from audio poses challenges. This paper introduces MFHCA, a novel method for Speech Emotion Recognition using Multi-Spatial Fusion and Hierarchical Cooperative Attention on spectrograms and raw audio. We employ the Multi-Spatial Fusion module (MF) to efficiently identify emotion-related spectrogram regions and integrate Hubert features for higher-level acoustic information. Our approach also includes a Hierarchical Cooperative Attention module (HCA) to merge features from various auditory levels. We evaluate our method on the IEMOCAP dataset and achieve 2.6\% and 1.87\% improvements on the weighted accuracy and unweighted accuracy, respectively. Extensive experiments demonstrate the effectiveness of the proposed method.