 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagnitude-Phase Dual-Path Speech Enhancement Network based on Self-Supervised Embedding and Perceptual Contrast Stretch Boosting
Mar 27, 2025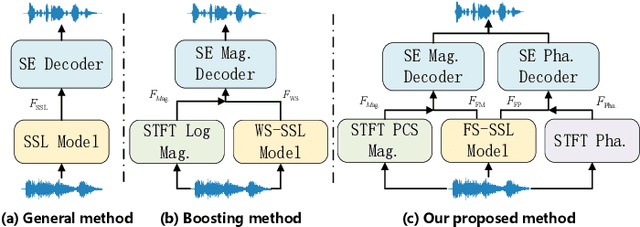
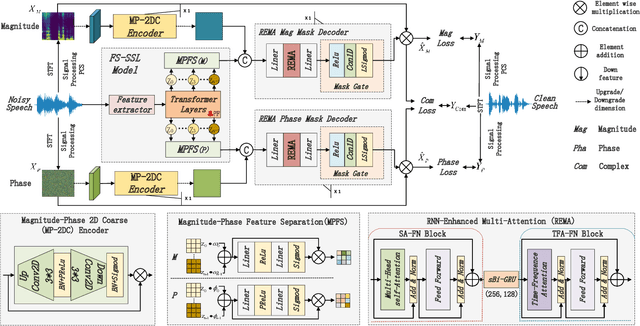
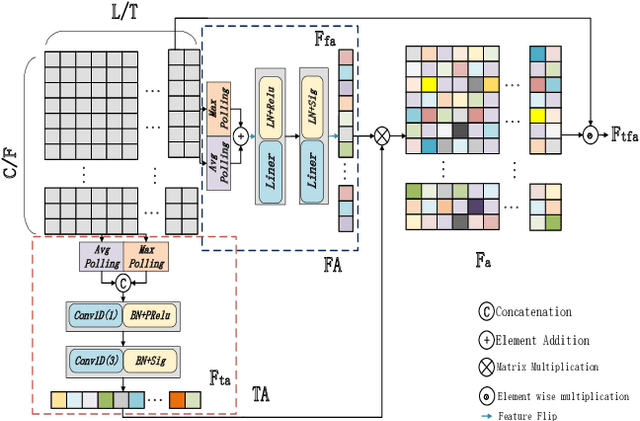
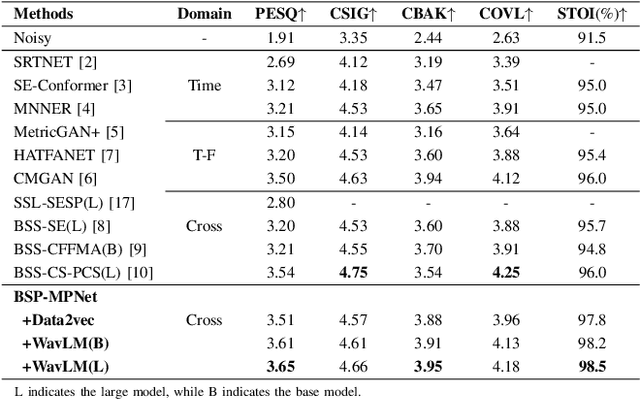
Speech self-supervised learning (SSL) has made great progress in various speech processing tasks, but there is still room for improvement in speech enhancement (SE). This paper presents BSP-MPNet, a dual-path framework that combines self-supervised features with magnitude-phase information for SE. The approach starts by applying the perceptual contrast stretching (PCS) algorithm to enhance the magnitude-phase spectrum. A magnitude-phase 2D coarse (MP-2DC) encoder then extracts coarse features from the enhanced spectrum. Next, a feature-separating self-supervised learning (FS-SSL) model generates self-supervised embeddings for the magnitude and phase components separately. These embeddings are fused to create cross-domain feature representations. Finally, two parallel RNN-enhanced multi-attention (REMA) mask decoders refine the features, apply them to the mask, and reconstruct the speech signal. We evaluate BSP-MPNet on the VoiceBank+DEMAND and WHAMR! datasets. Experimental results show that BSP-MPNet outperforms existing methods under various noise conditions, providing new directions for self-supervised speech enhancement research. The implementation of the BSP-MPNet code is available online\footnote[2]{https://github.com/AlimMat/BSP-MPNet. \label{s1}}
BSS-CFFMA: Cross-Domain Feature Fusion and Multi-Attention Speech Enhancement Network based on Self-Supervised Embedding
Aug 13, 2024Speech self-supervised learning (SSL) represents has achieved state-of-the-art (SOTA) performance in multiple downstream tasks. However, its application in speech enhancement (SE) tasks remains immature, offering opportunities for improvement. In this study, we introduce a novel cross-domain feature fusion and multi-attention speech enhancement network, termed BSS-CFFMA, which leverages self-supervised embeddings. BSS-CFFMA comprises a multi-scale cross-domain feature fusion (MSCFF) block and a residual hybrid multi-attention (RHMA) block. The MSCFF block effectively integrates cross-domain features, facilitating the extraction of rich acoustic information. The RHMA block, serving as the primary enhancement module, utilizes three distinct attention modules to capture diverse attention representations and estimate high-quality speech signals. We evaluate the performance of the BSS-CFFMA model through comparative and ablation studies on the VoiceBank-DEMAND dataset, achieving SOTA results. Furthermore, we select three types of data from the WHAMR! dataset, a collection specifically designed for speech enhancement tasks, to assess the capabilities of BSS-CFFMA in tasks such as denoising only, dereverberation only, and simultaneous denoising and dereverberation. This study marks the first attempt to explore the effectiveness of self-supervised embedding-based speech enhancement methods in complex tasks encompassing dereverberation and simultaneous denoising and dereverberation. The demo implementation of BSS-CFFMA is available online\footnote[2]{https://github.com/AlimMat/BSS-CFFMA. \label{s1}}.