 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Adversarial Discriminator: Mine the Non-causal Factors for Object Detection in Unseen Domains
Apr 06, 2023Domain shift degrades the performance of object detection models in practical applications. To alleviate the influence of domain shift, plenty of previous work try to decouple and learn the domain-invariant (common) features from source domains via domain adversarial learning (DAL). However, inspired by causal mechanisms, we find that previous methods ignore the implicit insignificant non-causal factors hidden in the common features. This is mainly due to the single-view nature of DAL. In this work, we present an idea to remove non-causal factors from common features by multi-view adversarial training on source domains, because we observe that such insignificant non-causal factors may still be significant in other latent spaces (views) due to the multi-mode structure of data. To summarize, we propose a Multi-view Adversarial Discriminator (MAD) based domain generalization model, consisting of a Spurious Correlations Generator (SCG) that increases the diversity of source domain by random augmentation and a Multi-View Domain Classifier (MVDC) that maps features to multiple latent spaces, such that the non-causal factors are removed and the domain-invariant features are purified. Extensive experiments on six benchmarks show our MAD obtains state-of-the-art performance.
Layer-wise Customized Weak Segmentation Block and AIoU Loss for Accurate Object Detection
Aug 25, 2021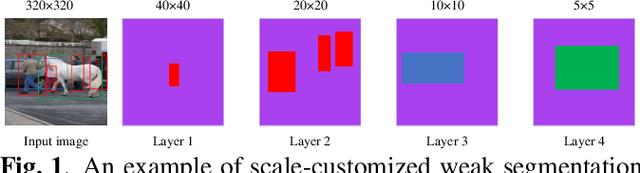
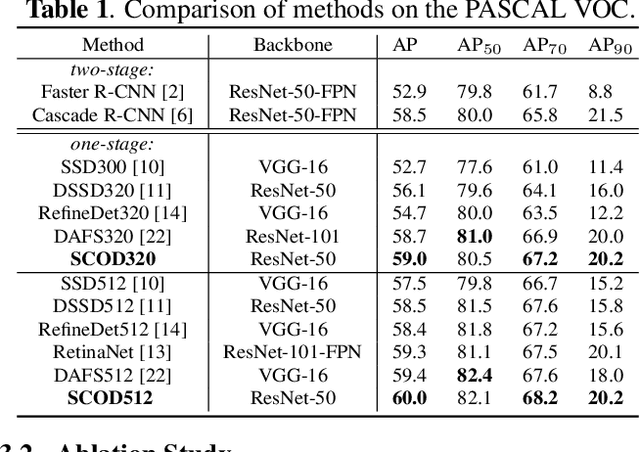
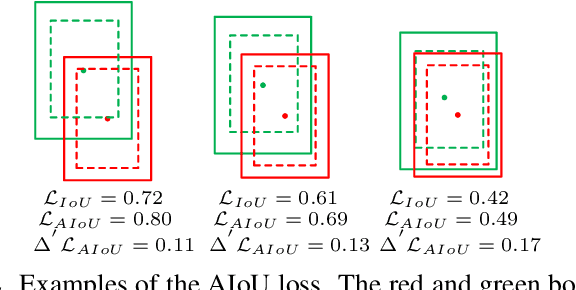
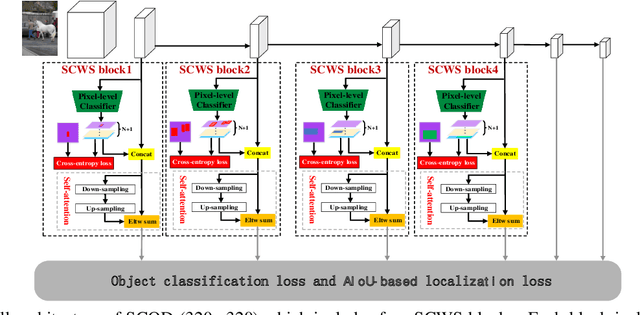
The anchor-based detectors handle the problem of scale variation by building the feature pyramid and directly setting different scales of anchors on each cell in different layers. However, it is difficult for box-wise anchors to guide the adaptive learning of scale-specific features in each layer because there is no one-to-one correspondence between box-wise anchors and pixel-level features. In order to alleviate the problem, in this paper, we propose a scale-customized weak segmentation (SCWS) block at the pixel level for scale customized object feature learning in each layer. By integrating the SCWS blocks into the single-shot detector, a scale-aware object detector (SCOD) is constructed to detect objects of different sizes naturally and accurately. Furthermore, the standard location loss neglects the fact that the hard and easy samples may be seriously imbalanced. A forthcoming problem is that it is unable to get more accurate bounding boxes due to the imbalance. To address this problem, an adaptive IoU (AIoU) loss via a simple yet effective squeeze operation is specified in our SCOD. Extensive experiments on PASCAL VOC and MS COCO demonstrate the superiority of our SCOD.
Deep Double-Side Learning Ensemble Model for Few-Shot Parkinson Speech Recognition
Jun 20, 2020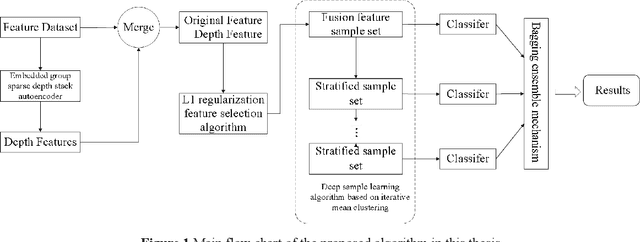

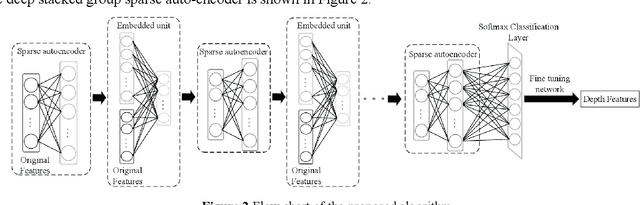

Diagnosis and therapeutic effect assessment of Parkinson disease based on voice data are very important,but its few-shot learning problem is challenging.Although deep learning is good at automatic feature extraction, it suffers from few-shot learning problem. Therefore, the general effective method is first conduct feature extraction based on prior knowledge, and then carry out feature reduction for subsequent classification. However, there are two major problems: 1) Structural information among speech features has not been mined and new features of higher quality have not been reconstructed. 2) Structural information between data samples has not been mined and new samples with higher quality have not been reconstructed. To solve these two problems, based on the existing Parkinson speech feature data set, a deep double-side learning ensemble model is designed in this paper that can reconstruct speech features and samples deeply and simultaneously. As to feature reconstruction, an embedded deep stacked group sparse auto-encoder is designed in this paper to conduct nonlinear feature transformation, so as to acquire new high-level deep features, and then the deep features are fused with original speech features by L1 regularization feature selection method. As to speech sample reconstruction, a deep sample learning algorithm is designed in this paper based on iterative mean clustering to conduct samples transformation, so as to obtain new high-level deep samples. Finally, the bagging ensemble learning mode is adopted to fuse the deep feature learning algorithm and the deep samples learning algorithm together, thereby constructing a deep double-side learning ensemble model. At the end of this paper, two representative speech datasets of Parkinson's disease were used for verification. The experimental results show that the proposed algorithm are effective.