 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtrapolating Large Language Models to Non-English by Aligning Languages
Aug 09, 2023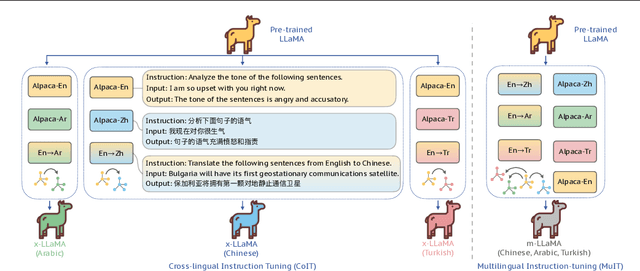
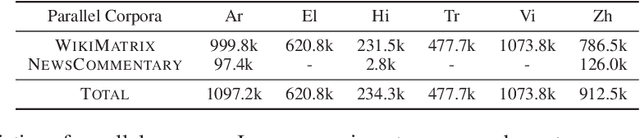
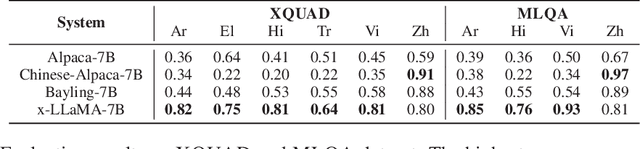
Due to the unbalanced training data distribution, the language ability of large language models (LLMs) is often biased towards English. In this paper, we propose to empower pre-trained LLMs on non-English languages by building semantic alignment across languages. We perform instruction-tuning on LLaMA with both translation task data and cross-lingual general task data to obtain cross-lingual models (x-LLaMA). Experiment results on cross-lingual benchmark XQUAD and MLQA show that x-LLaMA models outperform the English instruction-tuned counterpart (Alpaca) by 42.50% on average on six non-English languages. Further experiments on Chinese benchmark C-Eval show that x-LLaMA achieves significant improvement on Chinese humanities tasks, outperforming Alpaca by 8.2%. We also discover that incorporating non-English text on the target side of translation data is particularly effective for boosting non-English ability. Besides, we find that semantic alignment within LLM can be further strengthened as translation task data scales up and we present the formulation of the underlying scaling law. Evaluation results on translation dataset Flores-101 show that \method outperforms previous LLaMA-based models in all evaluated directions. Code and data will be available at: https://github.com/OwenNJU/x-LLM.
kNN-BOX: A Unified Framework for Nearest Neighbor Generation
Feb 27, 2023Augmenting the base neural model with a token-level symbolic datastore is a novel generation paradigm and has achieved promising results in machine translation (MT). In this paper, we introduce a unified framework kNN-BOX, which enables quick development and interactive analysis for this novel paradigm. kNN-BOX decomposes the datastore-augmentation approach into three modules: datastore, retriever and combiner, thus putting diverse kNN generation methods into a unified way. Currently, kNN-BOX has provided implementation of seven popular kNN-MT variants, covering research from performance enhancement to efficiency optimization. It is easy for users to reproduce these existing works or customize their own models. Besides, users can interact with their kNN generation systems with kNN-BOX to better understand the underlying inference process in a visualized way. In the experiment section, we apply kNN-BOX for machine translation and three other seq2seq generation tasks, namely, text simplification, paraphrase generation and question generation. Experiment results show that augmenting the base neural model with kNN-BOX leads to a large performance improvement in all these tasks. The code and document of kNN-BOX is available at https://github.com/NJUNLP/knn-box.
What Knowledge Is Needed? Towards Explainable Memory for kNN-MT Domain Adaptation
Nov 08, 2022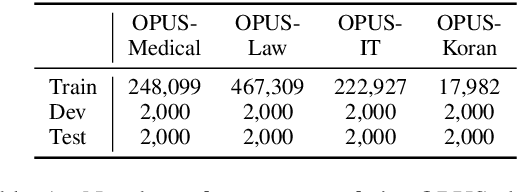
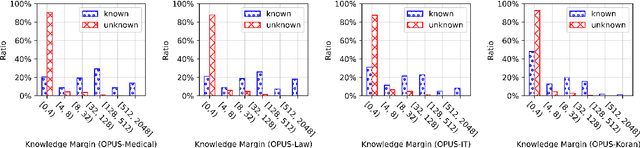
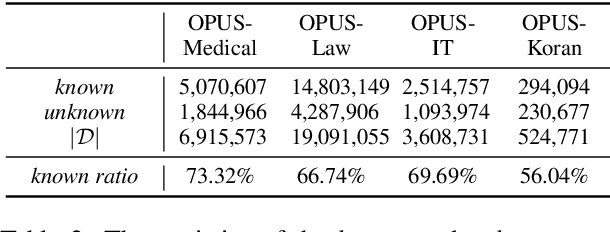
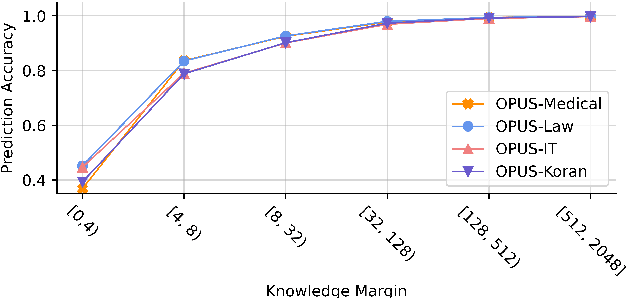
kNN-MT presents a new paradigm for domain adaptation by building an external datastore, which usually saves all target language token occurrences in the parallel corpus. As a result, the constructed datastore is usually large and possibly redundant. In this paper, we investigate the interpretability issue of this approach: what knowledge does the NMT model need? We propose the notion of local correctness (LAC) as a new angle, which describes the potential translation correctness for a single entry and for a given neighborhood. Empirical study shows that our investigation successfully finds the conditions where the NMT model could easily fail and need related knowledge. Experiments on six diverse target domains and two language-pairs show that pruning according to local correctness brings a light and more explainable memory for kNN-MT domain adaptation.