 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Knowledge Is Needed? Towards Explainable Memory for kNN-MT Domain Adaptation
Paper and Code
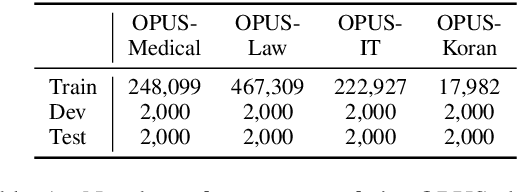
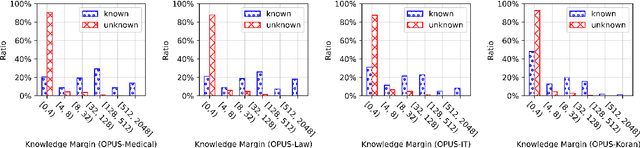
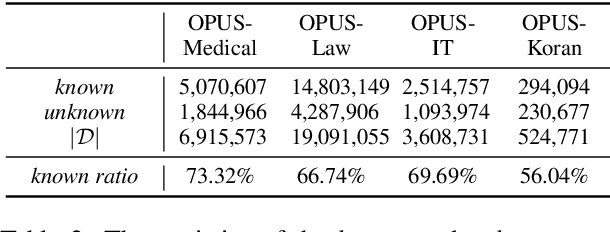
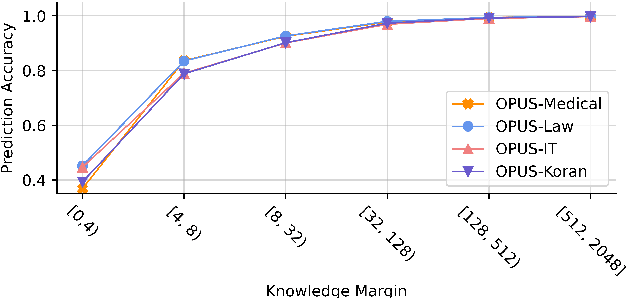
kNN-MT presents a new paradigm for domain adaptation by building an external datastore, which usually saves all target language token occurrences in the parallel corpus. As a result, the constructed datastore is usually large and possibly redundant. In this paper, we investigate the interpretability issue of this approach: what knowledge does the NMT model need? We propose the notion of local correctness (LAC) as a new angle, which describes the potential translation correctness for a single entry and for a given neighborhood. Empirical study shows that our investigation successfully finds the conditions where the NMT model could easily fail and need related knowledge. Experiments on six diverse target domains and two language-pairs show that pruning according to local correctness brings a light and more explainable memory for kNN-MT domain adaptation.