 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Guided Quadrupedal Locomotion in the Wild with Multi-Modal Delay Randomization
Sep 29, 2021
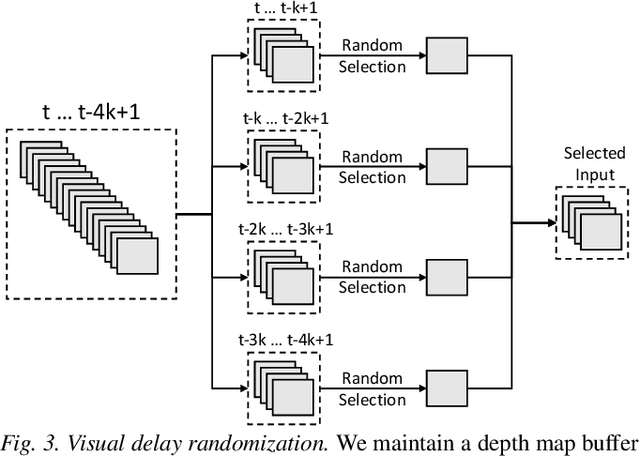

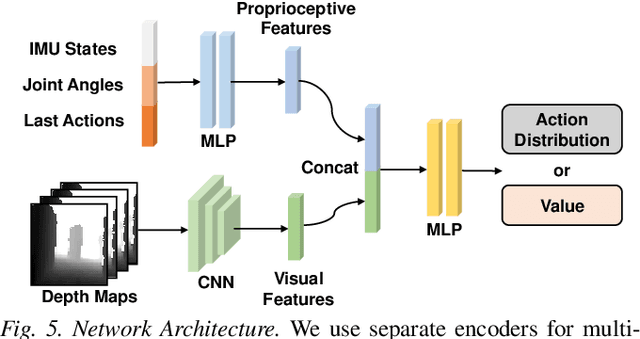
Developing robust vision-guided controllers for quadrupedal robots in complex environments, with various obstacles, dynamical surroundings and uneven terrains, is very challenging. While Reinforcement Learning (RL) provides a promising paradigm for agile locomotion skills with vision inputs in simulation, it is still very challenging to deploy the RL policy in the real world. Our key insight is that aside from the discrepancy in the domain gap, in visual appearance between the simulation and the real world, the latency from the control pipeline is also a major cause of difficulty. In this paper, we propose Multi-Modal Delay Randomization (MMDR) to address this issue when training RL agents. Specifically, we simulate the latency of real hardware by using past observations, sampled with randomized periods, for both proprioception and vision. We train the RL policy for end-to-end control in a physical simulator without any predefined controller or reference motion, and directly deploy it on the real A1 quadruped robot running in the wild. We evaluate our method in different outdoor environments with complex terrains and obstacles. We demonstrate the robot can smoothly maneuver at a high speed, avoid the obstacles, and show significant improvement over the baselines. Our project page with videos is at https://mehooz.github.io/mmdr-wild/.