 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Reinforcement Learning with Reverse Model-based Imagination
Oct 01, 2021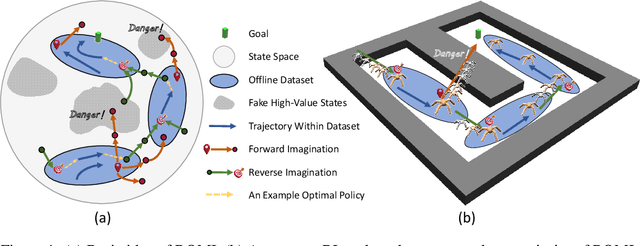
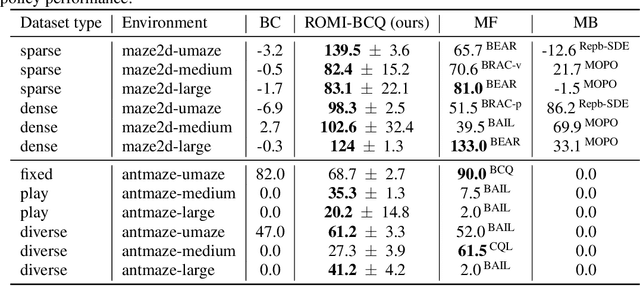

In offline reinforcement learning (offline RL), one of the main challenges is to deal with the distributional shift between the learning policy and the given dataset. To address this problem, recent offline RL methods attempt to introduce conservatism bias to encourage learning on high-confidence areas. Model-free approaches directly encode such bias into policy or value function learning using conservative regularizations or special network structures, but their constrained policy search limits the generalization beyond the offline dataset. Model-based approaches learn forward dynamics models with conservatism quantifications and then generate imaginary trajectories to extend the offline datasets. However, due to limited samples in offline dataset, conservatism quantifications often suffer from overgeneralization in out-of-support regions. The unreliable conservative measures will mislead forward model-based imaginations to undesired areas, leading to overaggressive behaviors. To encourage more conservatism, we propose a novel model-based offline RL framework, called Reverse Offline Model-based Imagination (ROMI). We learn a reverse dynamics model in conjunction with a novel reverse policy, which can generate rollouts leading to the target goal states within the offline dataset. These reverse imaginations provide informed data augmentation for the model-free policy learning and enable conservative generalization beyond the offline dataset. ROMI can effectively combine with off-the-shelf model-free algorithms to enable model-based generalization with proper conservatism. Empirical results show that our method can generate more conservative behaviors and achieve state-of-the-art performance on offline RL benchmark tasks.
On the Estimation Bias in Double Q-Learning
Sep 29, 2021

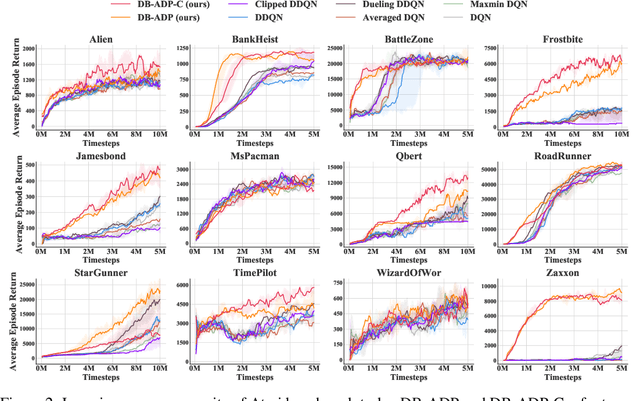

Double Q-learning is a classical method for reducing overestimation bias, which is caused by taking maximum estimated values in the Bellman operation. Its variants in the deep Q-learning paradigm have shown great promise in producing reliable value prediction and improving learning performance. However, as shown by prior work, double Q-learning is not fully unbiased and suffers from underestimation bias. In this paper, we show that such underestimation bias may lead to multiple non-optimal fixed points under an approximated Bellman operator. To address the concerns of converging to non-optimal stationary solutions, we propose a simple but effective approach as a partial fix for the underestimation bias in double Q-learning. This approach leverages an approximate dynamic programming to bound the target value. We extensively evaluate our proposed method in the Atari benchmark tasks and demonstrate its significant improvement over baseline algorithms.
Generalizable Episodic Memory for Deep Reinforcement Learning
Mar 11, 2021


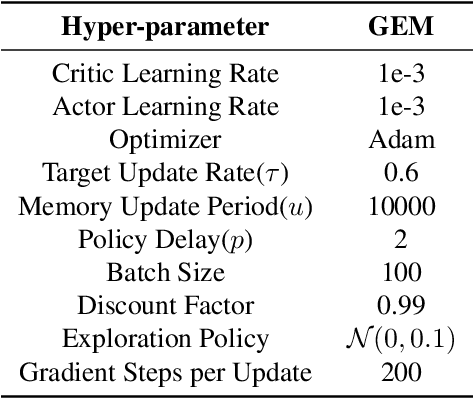
Episodic memory-based methods can rapidly latch onto past successful strategies by a non-parametric memory and improve sample efficiency of traditional reinforcement learning. However, little effort is put into the continuous domain, where a state is never visited twice and previous episodic methods fail to efficiently aggregate experience across trajectories. To address this problem, we propose Generalizable Episodic Memory (GEM), which effectively organizes the state-action values of episodic memory in a generalizable manner and supports implicit planning on memorized trajectories. GEM utilizes a double estimator to reduce the overestimation bias induced by value propagation in the planning process. Empirical evaluation shows that our method significantly outperforms existing trajectory-based methods on various MuJoCo continuous control tasks. To further show the general applicability, we evaluate our method on Atari games with discrete action space, which also shows significant improvement over baseline algorithms.
Bridging Imagination and Reality for Model-Based Deep Reinforcement Learning
Oct 23, 2020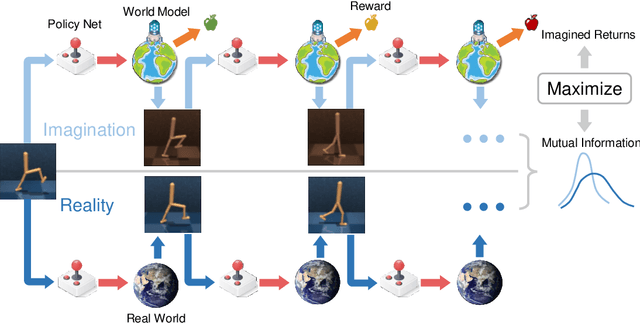

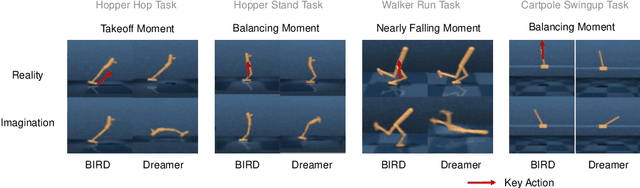
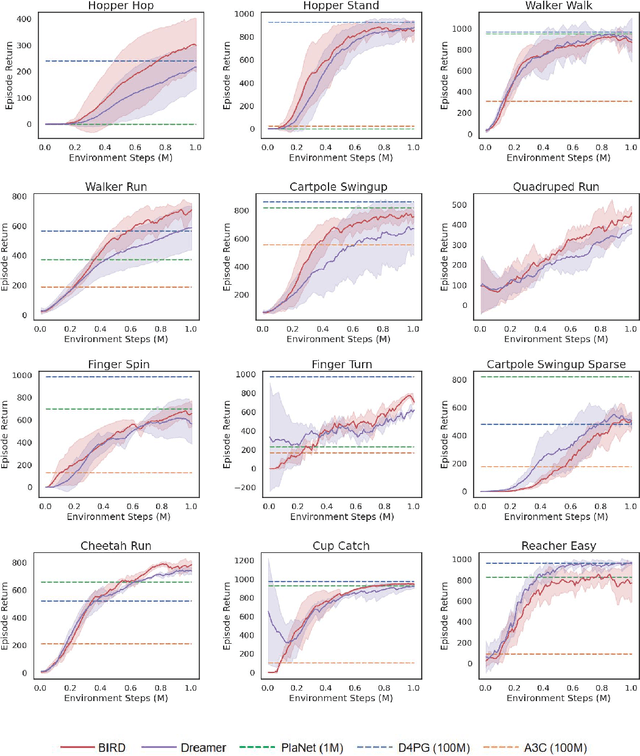
Sample efficiency has been one of the major challenges for deep reinforcement learning. Recently, model-based reinforcement learning has been proposed to address this challenge by performing planning on imaginary trajectories with a learned world model. However, world model learning may suffer from overfitting to training trajectories, and thus model-based value estimation and policy search will be pone to be sucked in an inferior local policy. In this paper, we propose a novel model-based reinforcement learning algorithm, called BrIdging Reality and Dream (BIRD). It maximizes the mutual information between imaginary and real trajectories so that the policy improvement learned from imaginary trajectories can be easily generalized to real trajectories. We demonstrate that our approach improves sample efficiency of model-based planning, and achieves state-of-the-art performance on challenging visual control benchmarks.
Object-Oriented Dynamics Learning through Multi-Level Abstraction
May 25, 2019

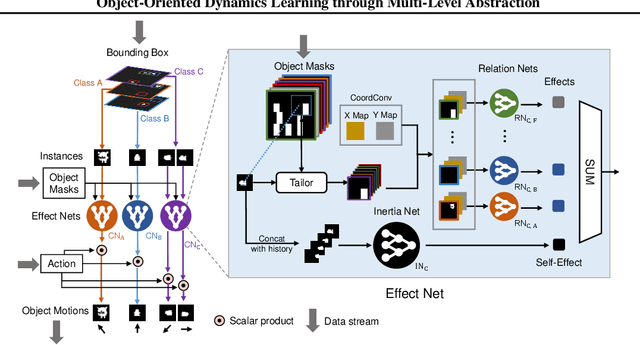
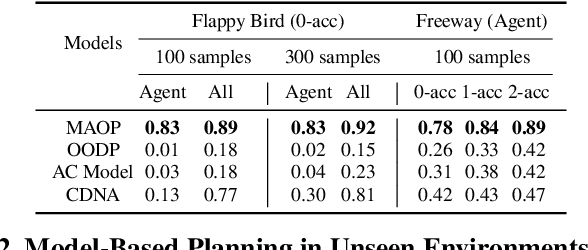
Object-based approaches for learning action-conditioned dynamics has demonstrated promise for generalization and interpretability. However, existing approaches suffer from structural limitations and optimization difficulties for common environments with multiple dynamic objects. In this paper, we present a novel self-supervised learning framework, called Multi-level Abstraction Object-oriented Predictor (MAOP), which employs a three-level learning architecture that enables efficient object-based dynamics learning from raw visual observations. We also design a spatial-temporal relational reasoning mechanism for MAOP to support instance-level dynamics learning and handle partial observability. Our results show that MAOP significantly outperforms previous methods in terms of sample efficiency and generalization over novel environments for learning environment models. We also demonstrate that learned dynamics models enable efficient planning in unseen environments, comparable to true environment models. In addition, MAOP learns semantically and visually interpretable disentangled representations.
Object-Oriented Dynamics Predictor
Oct 30, 2018



Generalization has been one of the major challenges for learning dynamics models in model-based reinforcement learning. However, previous work on action-conditioned dynamics prediction focuses on learning the pixel-level motion and thus does not generalize well to novel environments with different object layouts. In this paper, we present a novel object-oriented framework, called object-oriented dynamics predictor (OODP), which decomposes the environment into objects and predicts the dynamics of objects conditioned on both actions and object-to-object relations. It is an end-to-end neural network and can be trained in an unsupervised manner. To enable the generalization ability of dynamics learning, we design a novel CNN-based relation mechanism that is class-specific (rather than object-specific) and exploits the locality principle. Empirical results show that OODP significantly outperforms previous methods in terms of generalization over novel environments with various object layouts. OODP is able to learn from very few environments and accurately predict dynamics in a large number of unseen environments. In addition, OODP learns semantically and visually interpretable dynamics models.
Context-Aware Policy Reuse
Jun 28, 2018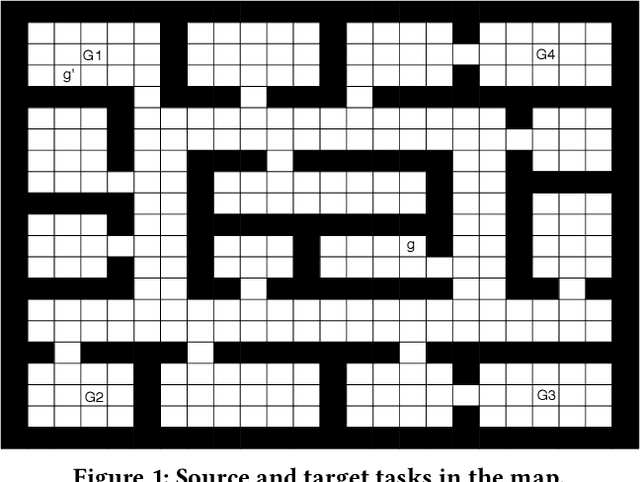
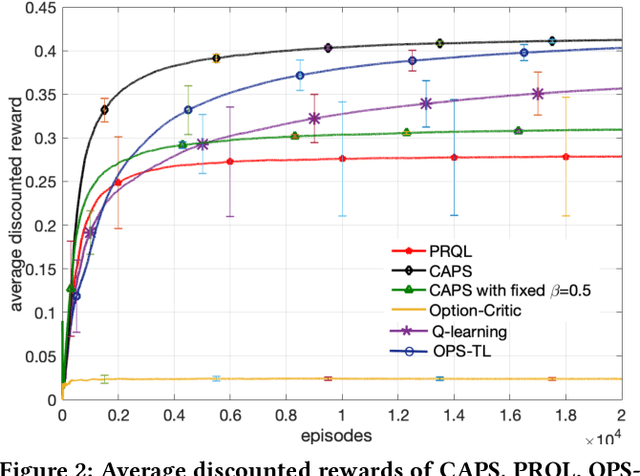

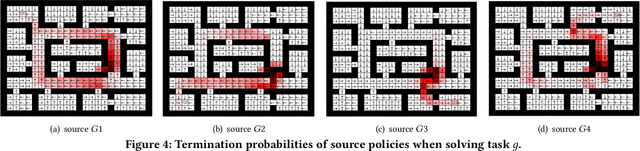
Transfer learning can greatly speed up reinforcement learning for a new task by leveraging policies of relevant tasks. Existing works of policy reuse either focus on only selecting a single best source policy for transfer without considering contexts, or cannot guarantee to learn an optimal policy for a target task. To improve transfer efficiency and guarantee optimality, we develop a novel policy reuse method, called Context-Aware Policy reuSe (CAPS), that enables multi-policy transfer. Our method learns when and which source policy is best for reuse, as well as when to terminate its reuse. CAPS provides theoretical guarantees in convergence and optimality for both source policy selection and target task learning. Empirical results on a grid-based navigation domain and the Pygame Learning Environment demonstrate that CAPS significantly outperforms other state-of-the-art policy reuse methods.
Generative Adversarial Mapping Networks
Sep 28, 2017


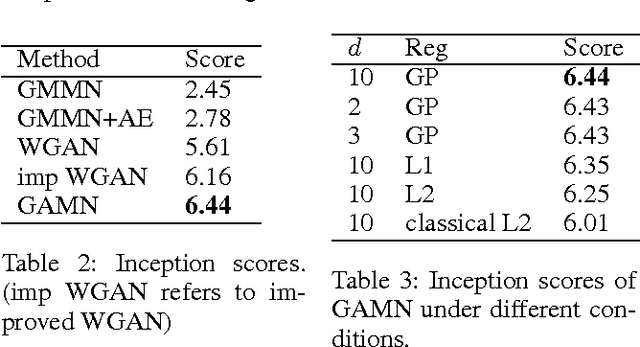
Generative Adversarial Networks (GANs) have shown impressive performance in generating photo-realistic images. They fit generative models by minimizing certain distance measure between the real image distribution and the generated data distribution. Several distance measures have been used, such as Jensen-Shannon divergence, $f$-divergence, and Wasserstein distance, and choosing an appropriate distance measure is very important for training the generative network. In this paper, we choose to use the maximum mean discrepancy (MMD) as the distance metric, which has several nice theoretical guarantees. In fact, generative moment matching network (GMMN) (Li, Swersky, and Zemel 2015) is such a generative model which contains only one generator network $G$ trained by directly minimizing MMD between the real and generated distributions. However, it fails to generate meaningful samples on challenging benchmark datasets, such as CIFAR-10 and LSUN. To improve on GMMN, we propose to add an extra network $F$, called mapper. $F$ maps both real data distribution and generated data distribution from the original data space to a feature representation space $\mathcal{R}$, and it is trained to maximize MMD between the two mapped distributions in $\mathcal{R}$, while the generator $G$ tries to minimize the MMD. We call the new model generative adversarial mapping networks (GAMNs). We demonstrate that the adversarial mapper $F$ can help $G$ to better capture the underlying data distribution. We also show that GAMN significantly outperforms GMMN, and is also superior to or comparable with other state-of-the-art GAN based methods on MNIST, CIFAR-10 and LSUN-Bedrooms datasets.